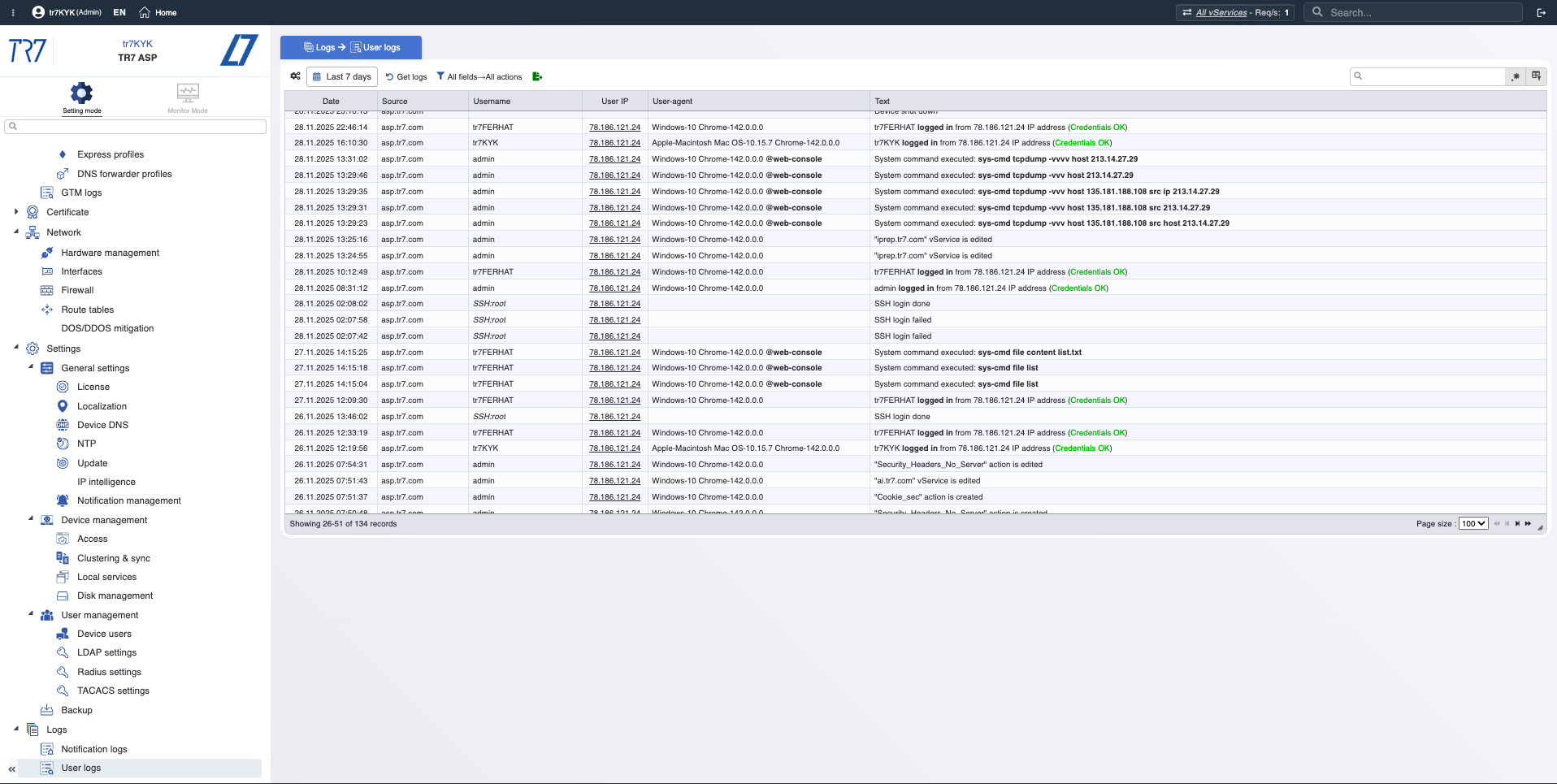
L'envoi de télémétrie ne suffit pas : ADC prêt pour l'investigation, Forensics rétrospective et chaîne de preuves
Métriques sur l'appliance + enregistrements d'événements + audit + visibilité du trafic pour une investigation rétrospective et une analyse rapide des causes profondes
Lorsque la production tombe en panne, trois questions importent : Que s'est-il passé ? Quand cela s'est-il passé ? Pourquoi cela s'est-il passé ?
En pratique, les réponses sont souvent dispersées : les métriques à un endroit, les journaux de trafic à un autre, et l'historique des modifications ailleurs.
Il y a une autre réalité : les exportations vers les systèmes externes sont généralement sélectives. Si le signal dont vous avez besoin lors d'un incident n'a jamais été sélectionné pour l'exportation, vous ne l'aurez pas.
L'approche de TR7 est claire : les intégrations d'exportation sont importantes, mais l'investigation ne doit pas dépendre uniquement d'elles. C'est pourquoi TR7 conserve les signaux critiques sur l'appliance, alignés sur une chronologie unique.
Un signal qui n'est pas capturé est un risque qui reste invisible.
Pourquoi l'exportation seule ne suffit-elle pas ?
Les plateformes SIEM, serveurs de journaux et Prometheus/Grafana sont précieuses pour la visibilité d'entreprise. Cependant, le succès de l'investigation dépend de la disponibilité des bonnes données au moment où vous en avez besoin.
La collecte sélective est inévitable
Les coûts et le bruit signifient que toutes les métriques/journaux ne sont pas exportés. Lorsqu'un incident se produit, le signal critique peut manquer.
La corrélation devient plus difficile avec la dispersion des données
Lorsque les métriques, événements, audit et journaux de trafic sont à différents endroits, construire une chronologie unique prend plus de temps.
Le pipeline est une autre zone à risque
Les problèmes d'agent, de réseau, de quota/limite ou d'indexation peuvent causer une perte de données, surtout pendant les incidents.
Prêt pour l'investigation
Consacrez du temps à résoudre, pas à collecter des données. TR7 maintient les signaux critiques prêts sur l'appliance.
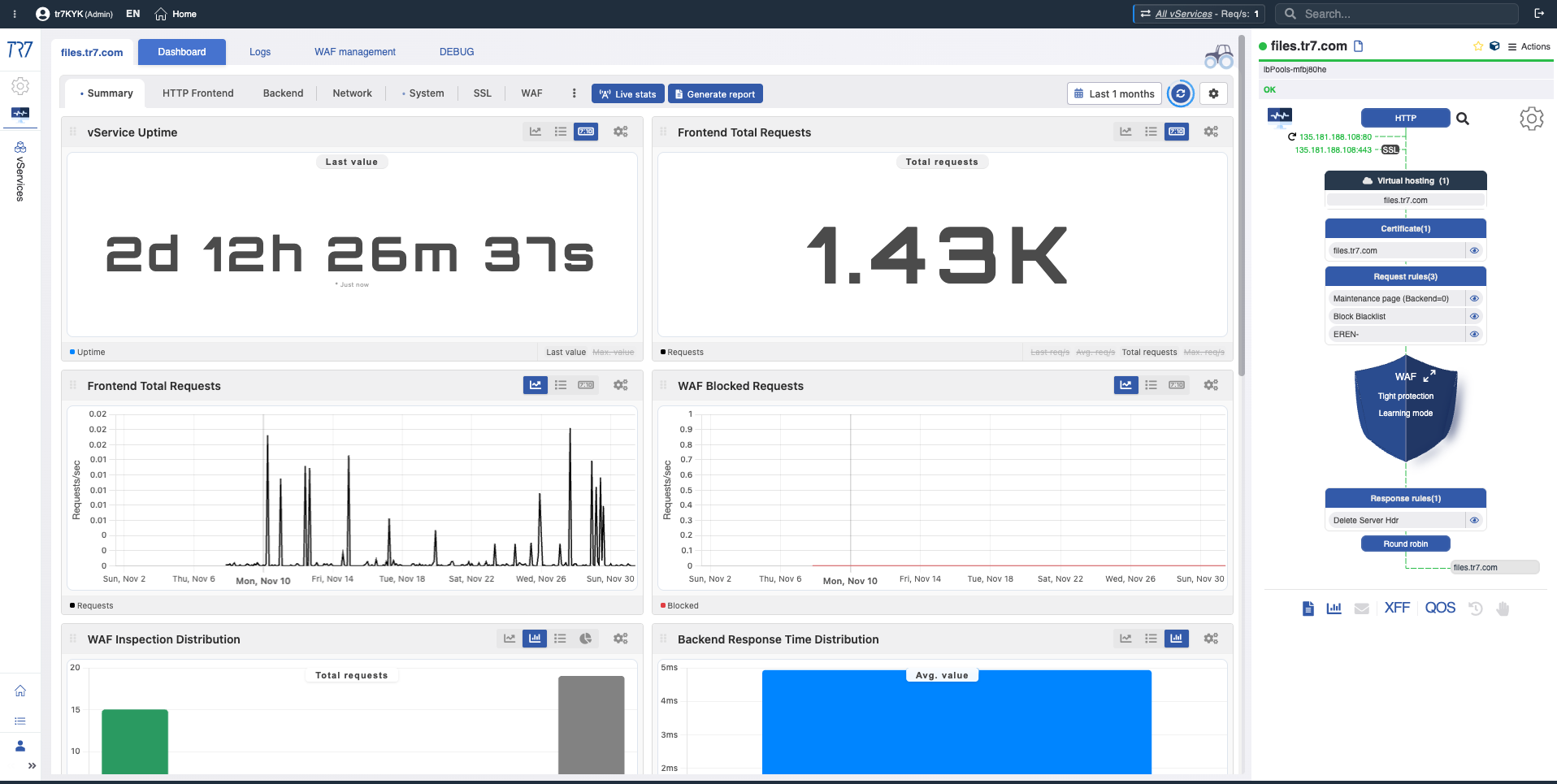
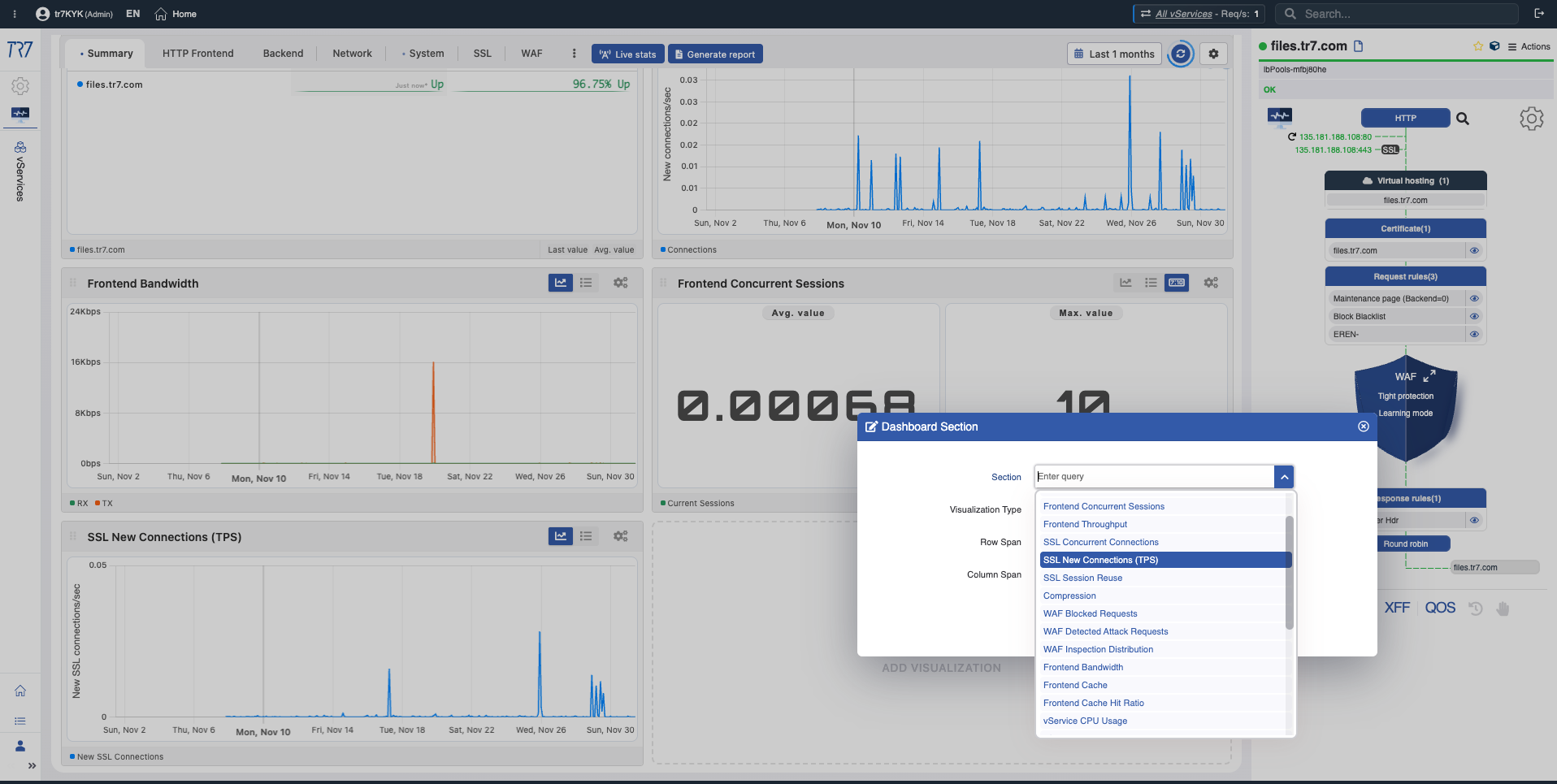
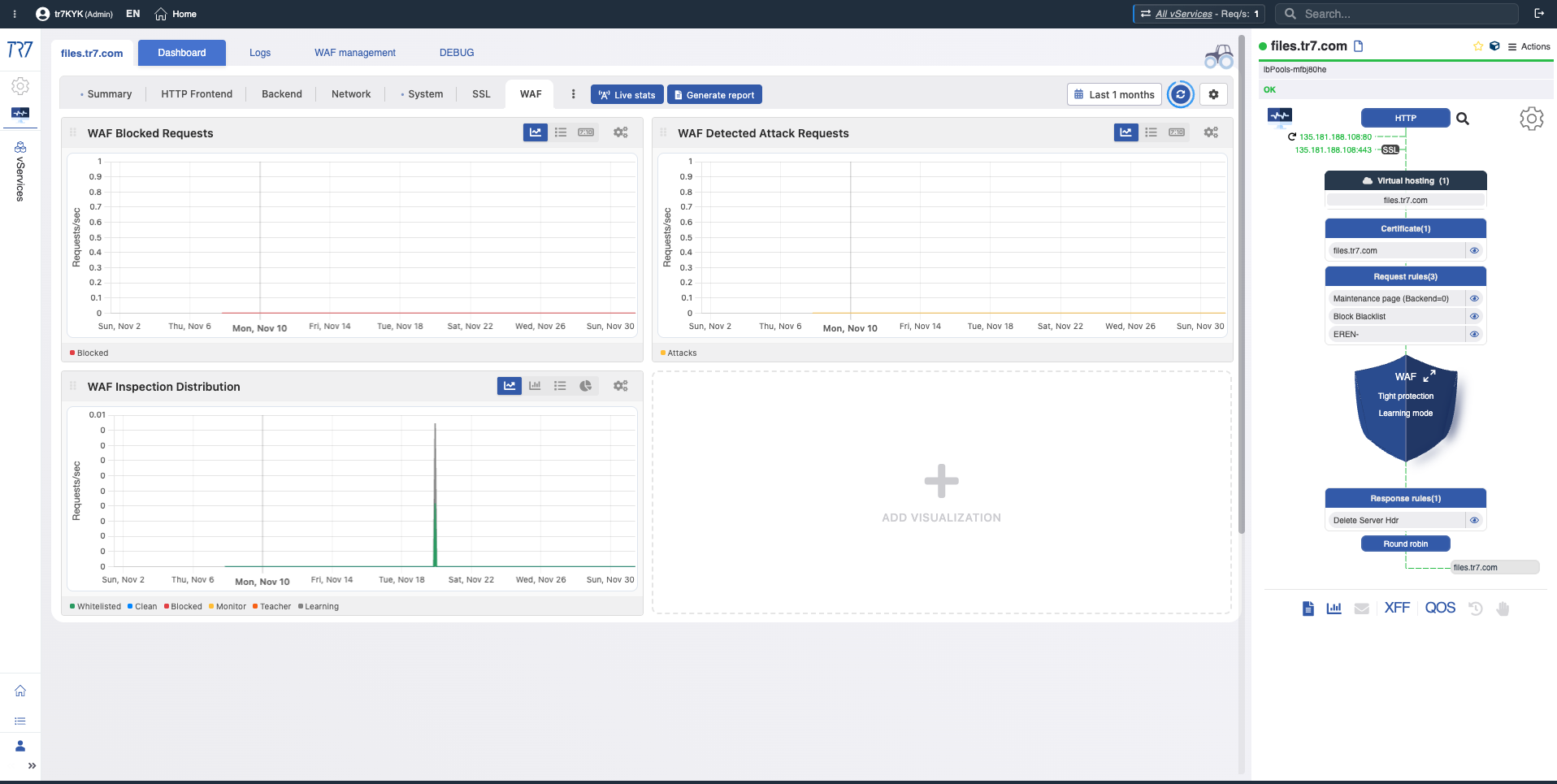
Dynamic Flow Panel : visibilité runtime et point de départ rapide
Dans l'interface de TR7, la topologie des services peut être surveillée en direct (runtime) via le Dynamic Flow Panel. Contrôle complet →
Le panneau affiche l'état du service avec des couleurs. Par exemple, si la liaison d'interface servant l'IP d'un vService tombe en panne, le système génère un avertissement et le nom du service passe du vert au jaune.
Cela permet aux opérateurs de voir immédiatement ce qu'il faut investiguer. Le triage commence plus rapidement et le temps d'investigation diminue.
Couleurs d'état
Les couleurs dans le Flow Panel vous aident à lire rapidement l'état du service :
Vert : Normal
Les connexions de service et les vérifications de santé fonctionnent comme prévu.
Tous les backends sains
Liaisons d'interface actives
Vérifications de santé réussies
Surveillance de routine
Jaune : Attention
Il y a une condition qui nécessite une surveillance.
Liaison d'interface inactive (le service peut toujours fonctionner)
Échec d'une vérification de santé backend
Approche du seuil de ressources
Vérification rapide via métriques + notification + audit
Rouge : Critique
Il y a un problème affectant le service.
Backends en panne
vService inaccessible
Erreur de configuration critique
Triage rapide : métrique + événement + audit
Exemples de scénarios d'investigation
Les exemples suivants montrent comment une investigation typique progresse sur TR7.
Scénario A : Augmentation de la latence
Plainte : 'L'application est lente'
Vérifier la tendance du temps de réponse vService → Y a-t-il des pics ?
Vérifier la distribution du temps de réponse backend → Quel backend est lent ?
Vérifier avec les vérifications de santé et les distributions de connexion
Y a-t-il des alertes de ressources dans les journaux de notification pendant la même période ?
Piste d'audit : Y a-t-il eu des changements récents ?
Résultat : Couche LB ou backend spécifique — rapidement clarifié
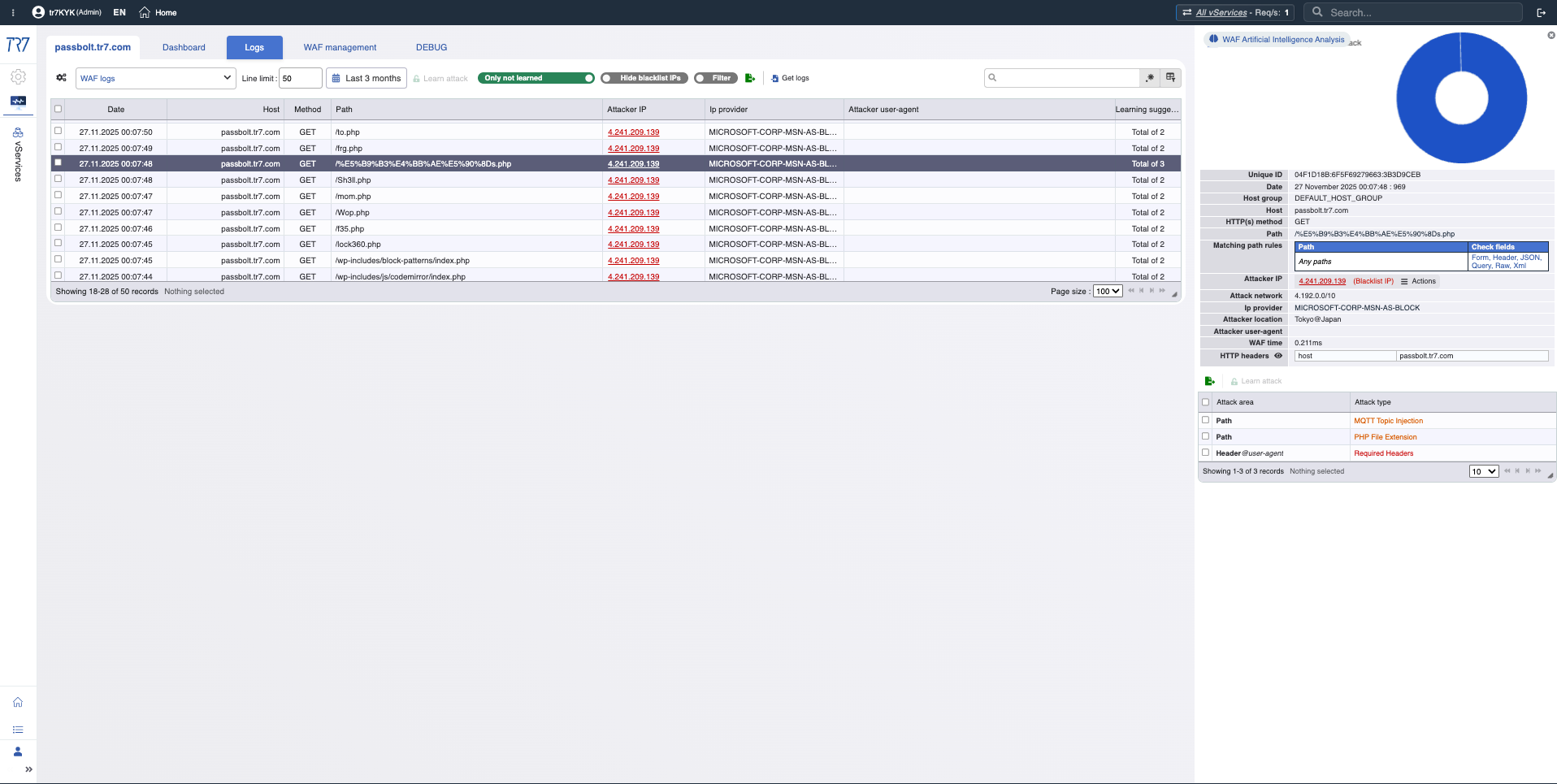
Scénario B : Augmentation des blocages WAF
Plainte : 'Les soumissions de formulaires échouent'
Vérifier la métrique de blocage WAF → Y a-t-il des pics ?
Trouver la règle déclenchée dans les journaux HTTP/WAF
Déterminer à partir des détails de la requête : faux positif ou attaque réelle ?
Piste d'audit : Y a-t-il eu des changements de règle/politique ?
Utiliser le débogage ciblé si nécessaire pour inspecter uniquement le trafic pertinent
Résultat : Ajustement de règle ou action de sécurité — décider avec des données
Aperçu de l'appareil : point de départ de l'investigation
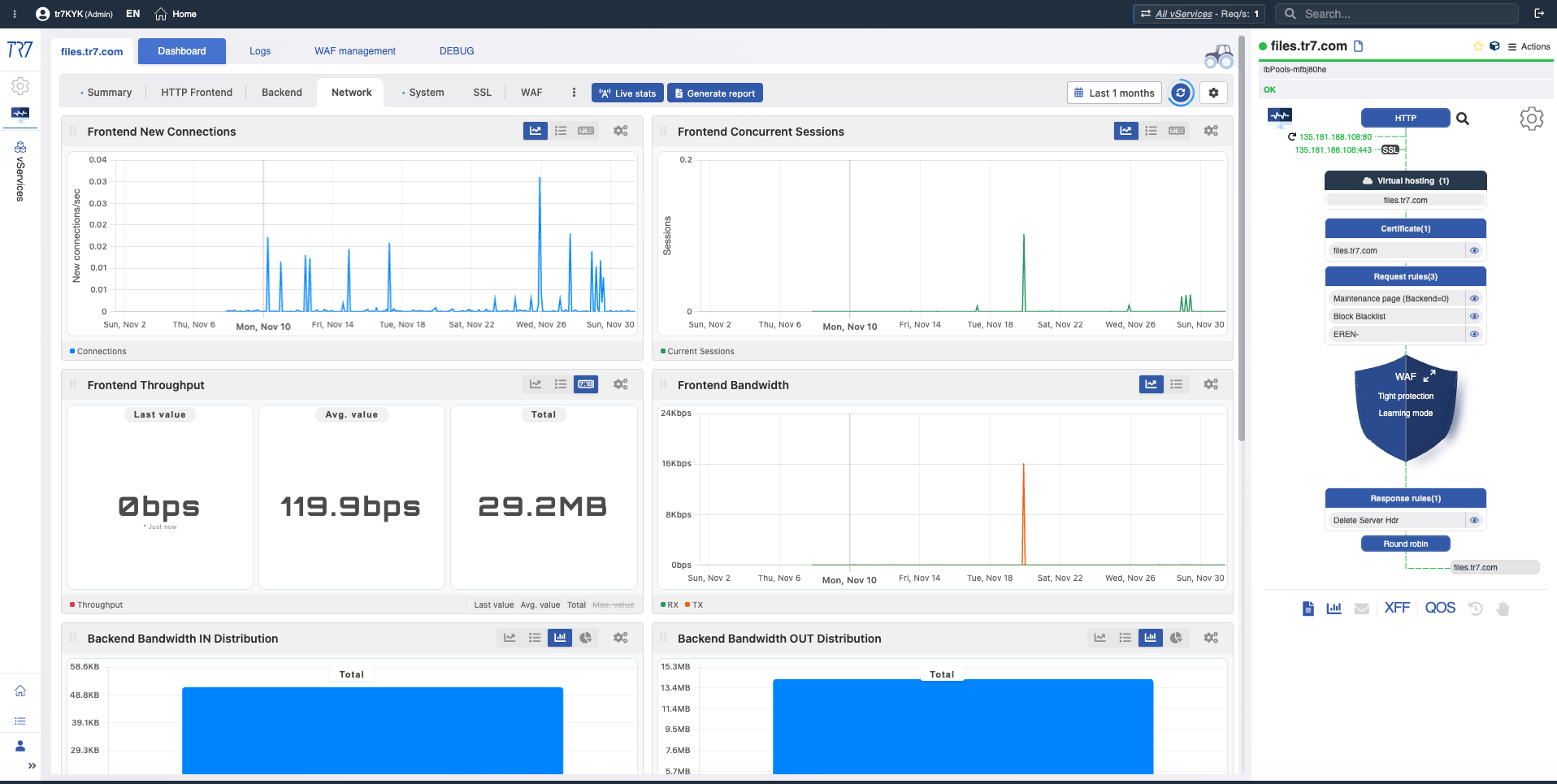
L'investigation d'incident commence toujours par l'aperçu de l'appareil. CPU, mémoire, utilisation du disque et santé du système — évaluez l'état global de l'appareil d'un coup d'œil. La sélection de plage de temps permet une forensics rétrospective.
Résumé système : Temps de fonctionnement, total des requêtes, charge CPU, mémoire, bande passante — évaluer rapidement l'état de l'appareil lors d'un incident.
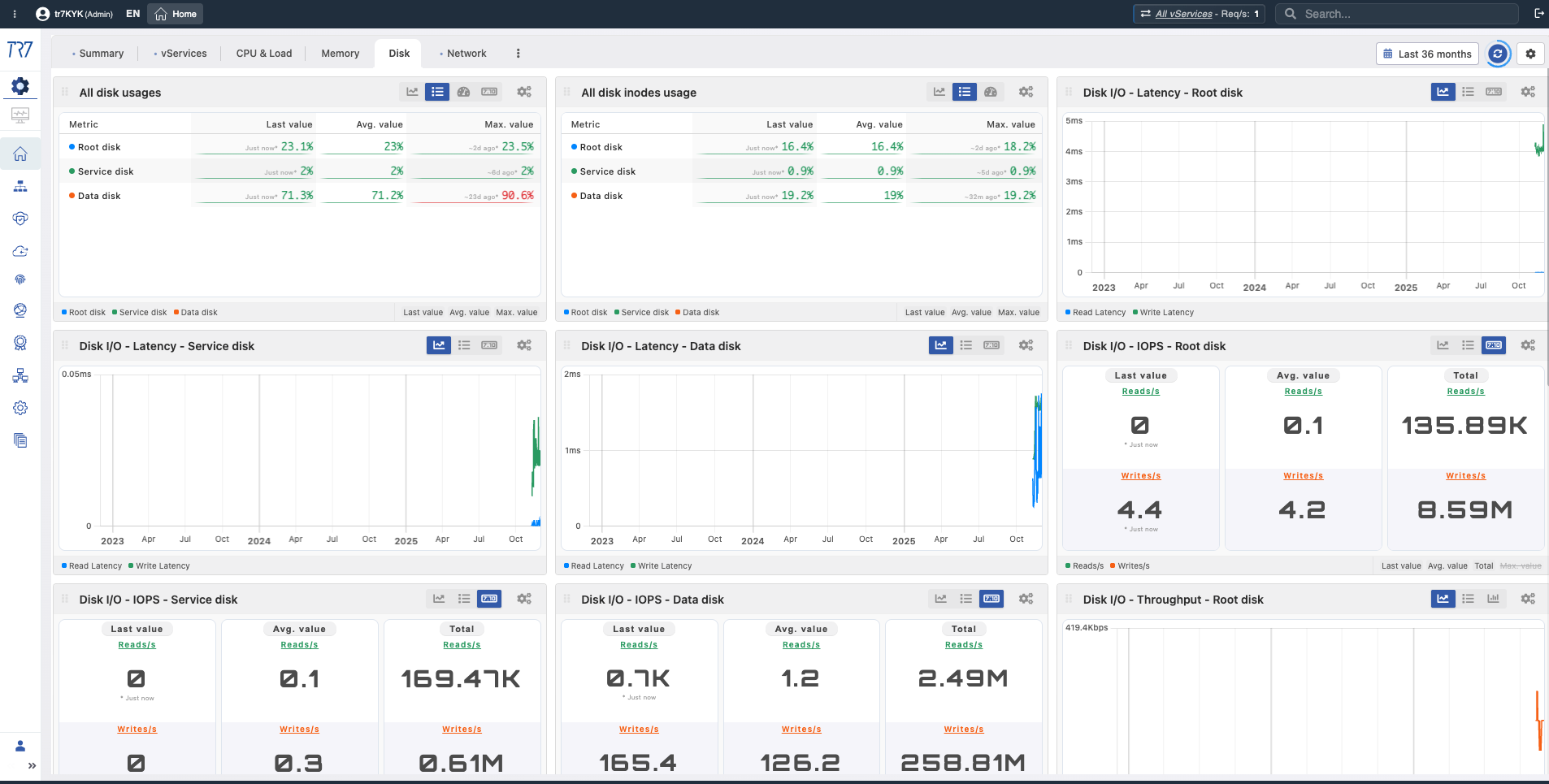
Disque et E/S : Utilisation, inode, latence, IOPS — l'écriture de journal ou les performances du cache sont-elles affectées ?
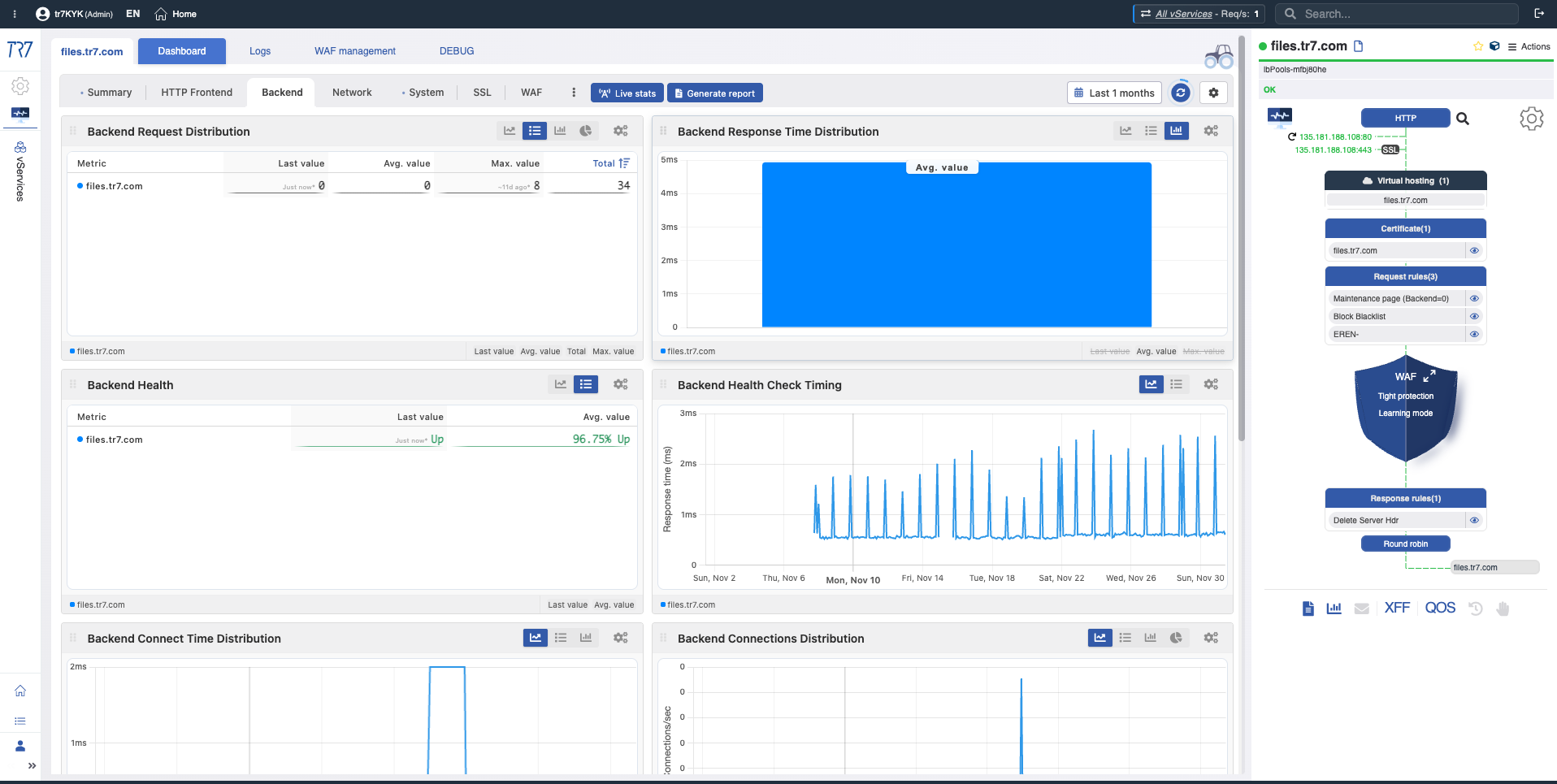
Service et backend : métriques de performance et de santé
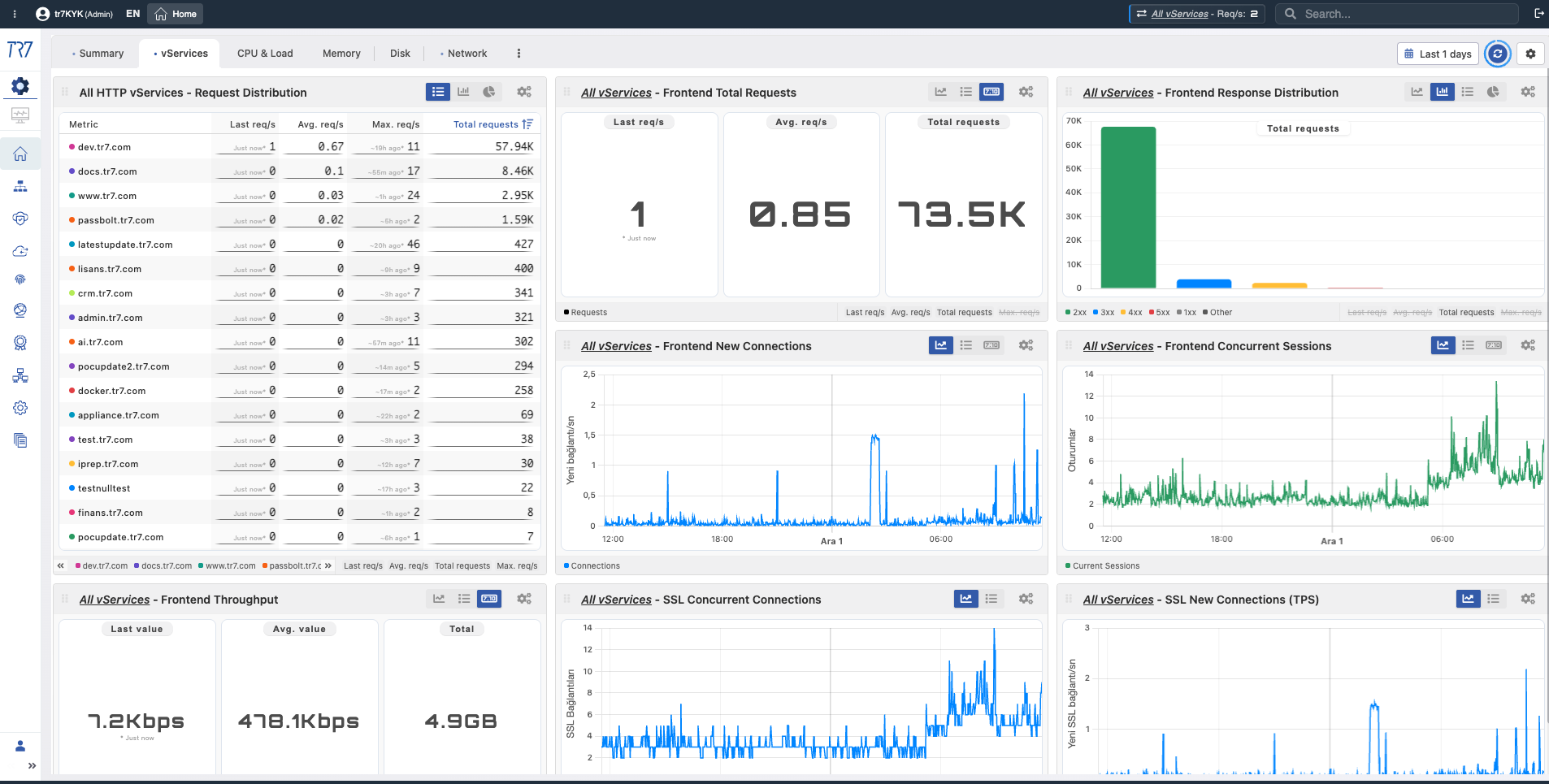
Après l'aperçu du système, descendez au niveau de la couche service. Distribution des requêtes de tous les vServices, codes de réponse, santé backend et topologie de service via le Dynamic Flow Panel — tout d'un coup d'œil. Chaque vService a son propre tableau de bord.
Aperçu vService : Distribution des requêtes et codes de réponse (2xx/3xx/4xx/5xx) sur tous les services — quel service présente des anomalies ?
Résumé vService : Temps de fonctionnement, requêtes frontend, nombre de blocages WAF et Dynamic Flow Panel — état actuel du service.
Métriques personnalisables : Réutilisation SSL, compression, taux de succès du cache — ajouter les métriques nécessaires pour l'investigation.
Distributions backend : Quel backend est lent ? Lequel reçoit plus de requêtes ? Métriques de temps de réponse et de connexion.
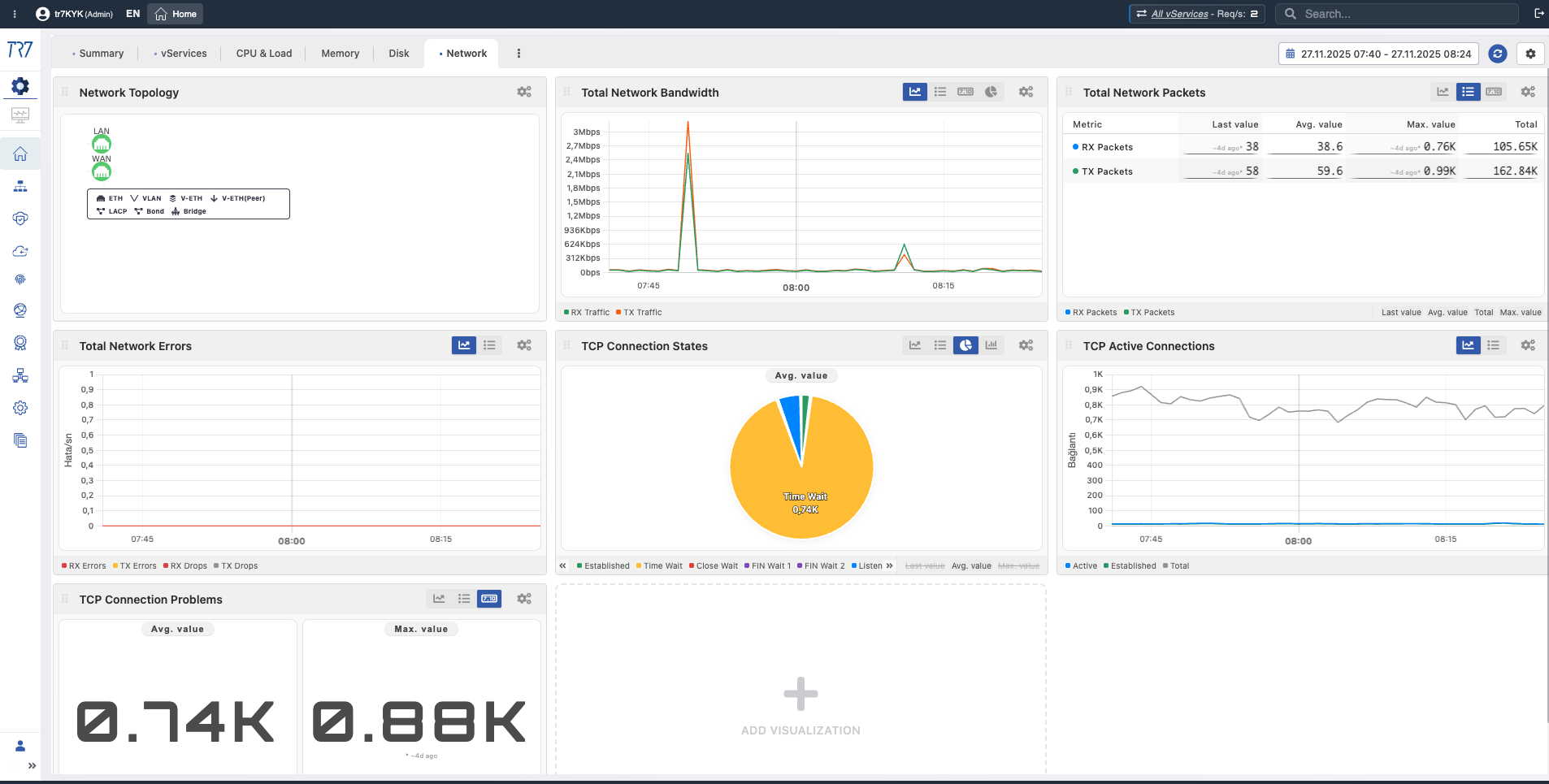
Réseau et interface : état de connexion et flux de trafic
Le problème est-il dans le service ou dans le réseau ? La topologie, la bande passante, la distribution de l'état TCP et les métriques d'interface répondent à cette question. Les changements d'état de liaison et les erreurs de paquets révèlent rapidement les problèmes de la couche réseau.
Topologie réseau : Bande passante, distribution de l'état TCP — premier indice pour séparer les problèmes de service et de réseau.
Métriques d'interface : Bande passante RX/TX, nombre de paquets, erreurs — performances et santé de la liaison.
Réseau vService : Débit et états de connexion par service — le modèle de trafic est-il normal ?
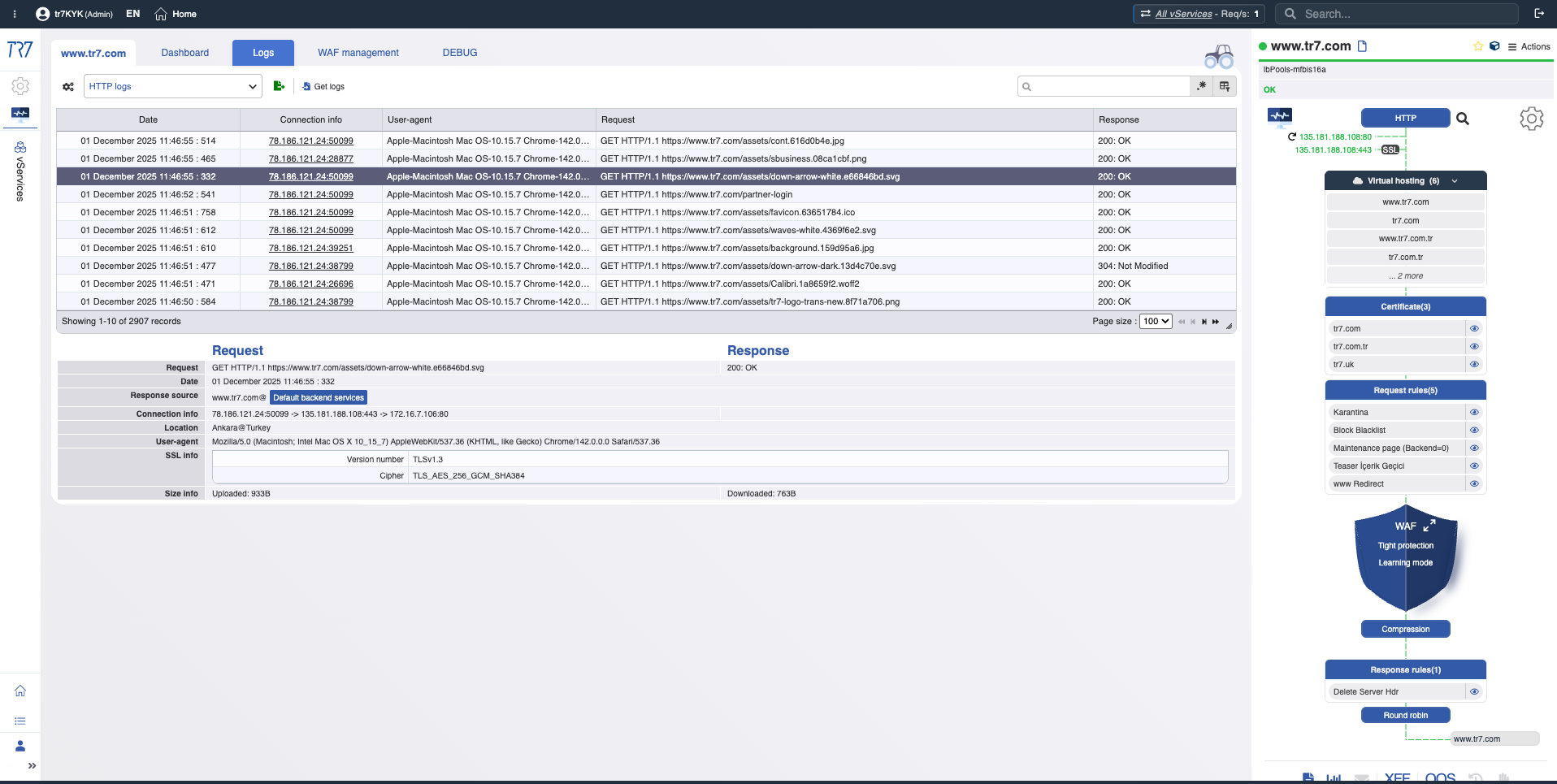
Journaux HTTP et WAF : investigation au niveau requête
Le trafic HTTP et les événements WAF sont visibles sans activer le débogage. Si nécessaire, le débogage ciblé capture les détails complets uniquement pour un host/path/header spécifique. Forensics au niveau requête sans impact sur la production.
Journaux HTTP : IP source, destination, code de réponse, taille, durée — visibilité de base même avec débogage désactivé.
Débogage ciblé : En-têtes et cookies complets pour le trafic pertinent uniquement — détails sans impact sur la production.
Journaux WAF : Règle déclenchée, détails de requête, analyse alimentée par IA — données pour l'évaluation des faux positifs.
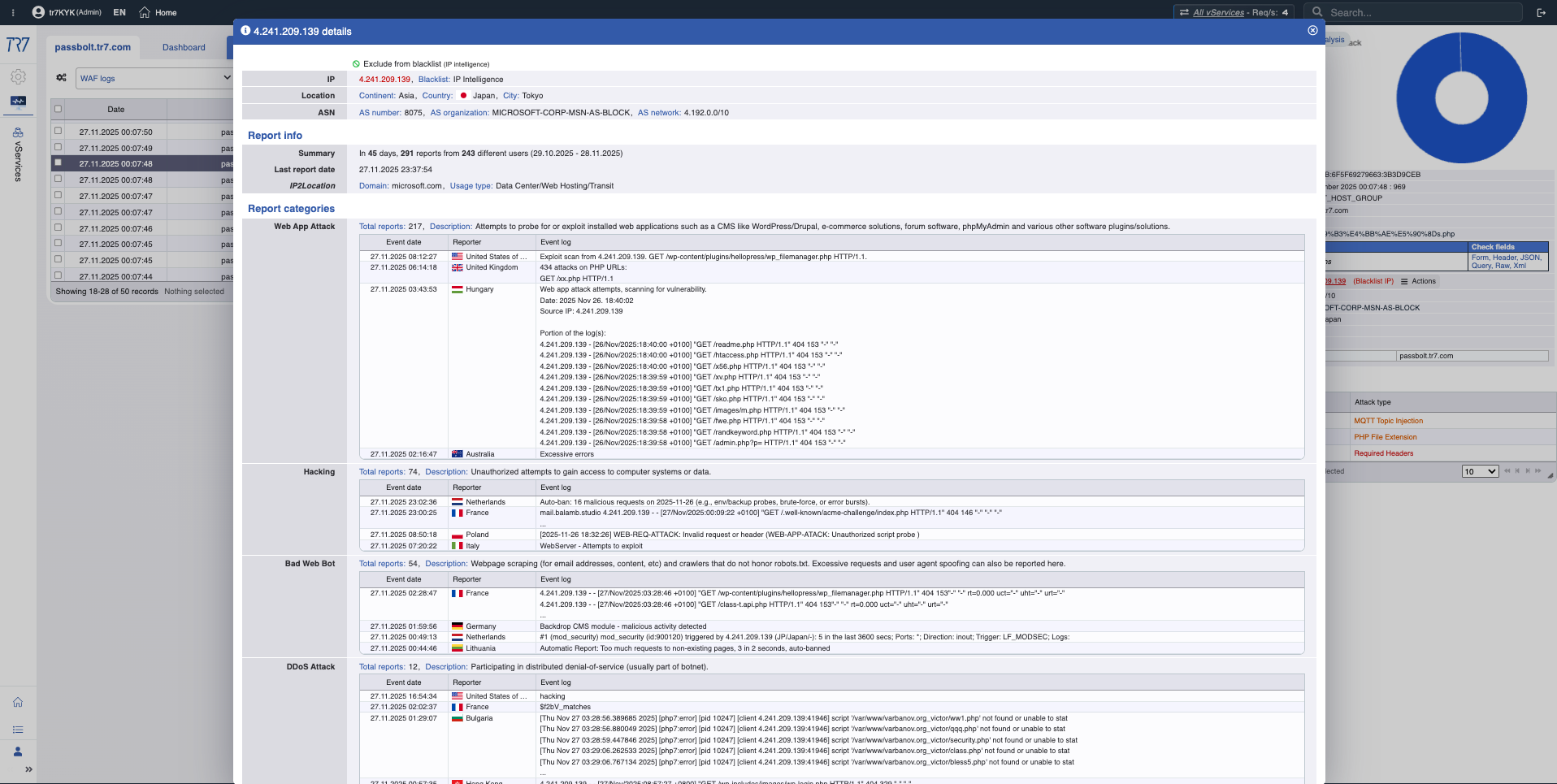
Intelligence IP et WAF : profil de menace
Les scores de réputation IP et les métriques WAF révèlent rapidement le profil de l'attaquant. La première réponse à 'faux positif ou attaque réelle ?' est ici. Les catégories de menaces (botnet, proxy, VPN, Tor) montrent la nature de l'IP source.
Intelligence IP : Score de réputation, catégories de menaces — le profil de l'attaquant devient rapidement clair.
Métriques WAF : Tendance de blocage, distribution d'inspection — aperçu des événements de sécurité.
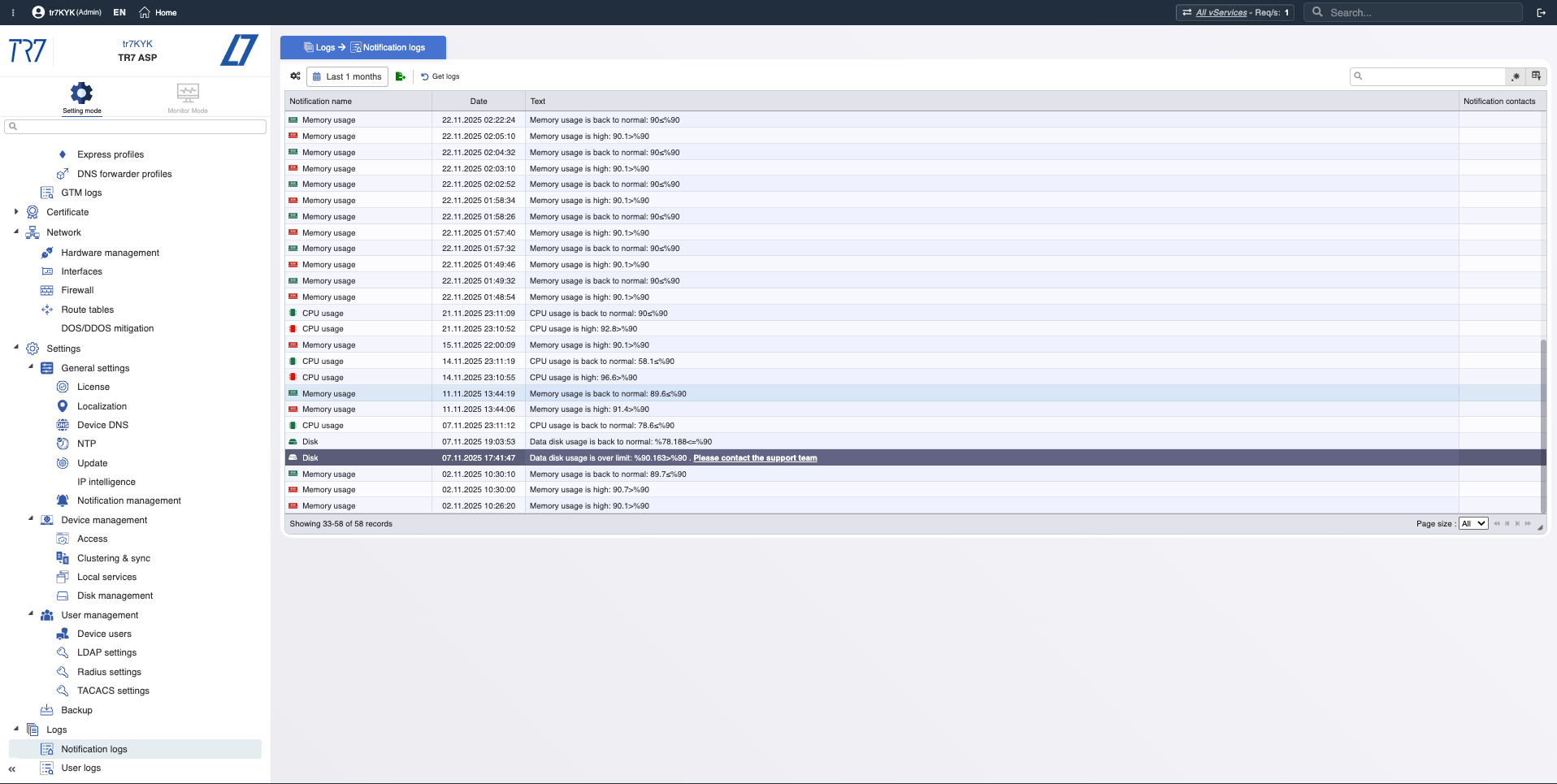
Chronologie des événements : notifications et piste d'audit
Les métriques seules ne suffisent pas. Quelles alertes ont été déclenchées ? Qui a changé quoi et quand ? Dans l'investigation d'incident, 'quel changement a affecté quoi ?' est critique. TR7 conserve ensemble les enregistrements de notification/événement et la piste d'audit, accélérant cette corrélation.
Types de notifications : CPU, mémoire, disque, bande passante, état du service — quels événements sont surveillés ?
Historique des notifications : Chronologie des alertes déclenchées — quels avertissements sont arrivés pendant l'incident ?
Piste d'audit : Qui a changé quoi, quand ? Preuve pour corréler rapidement les incidents avec les changements.
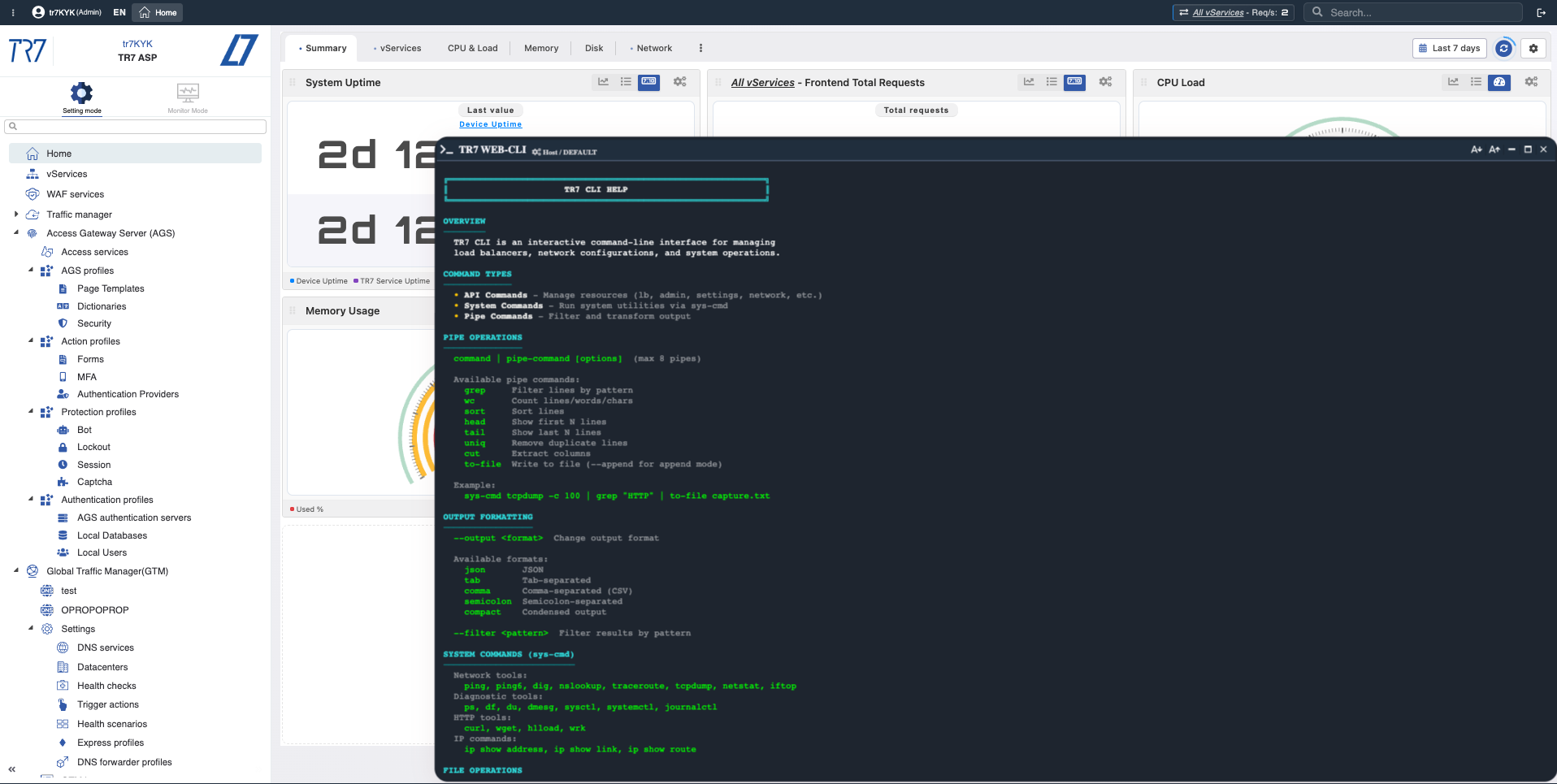
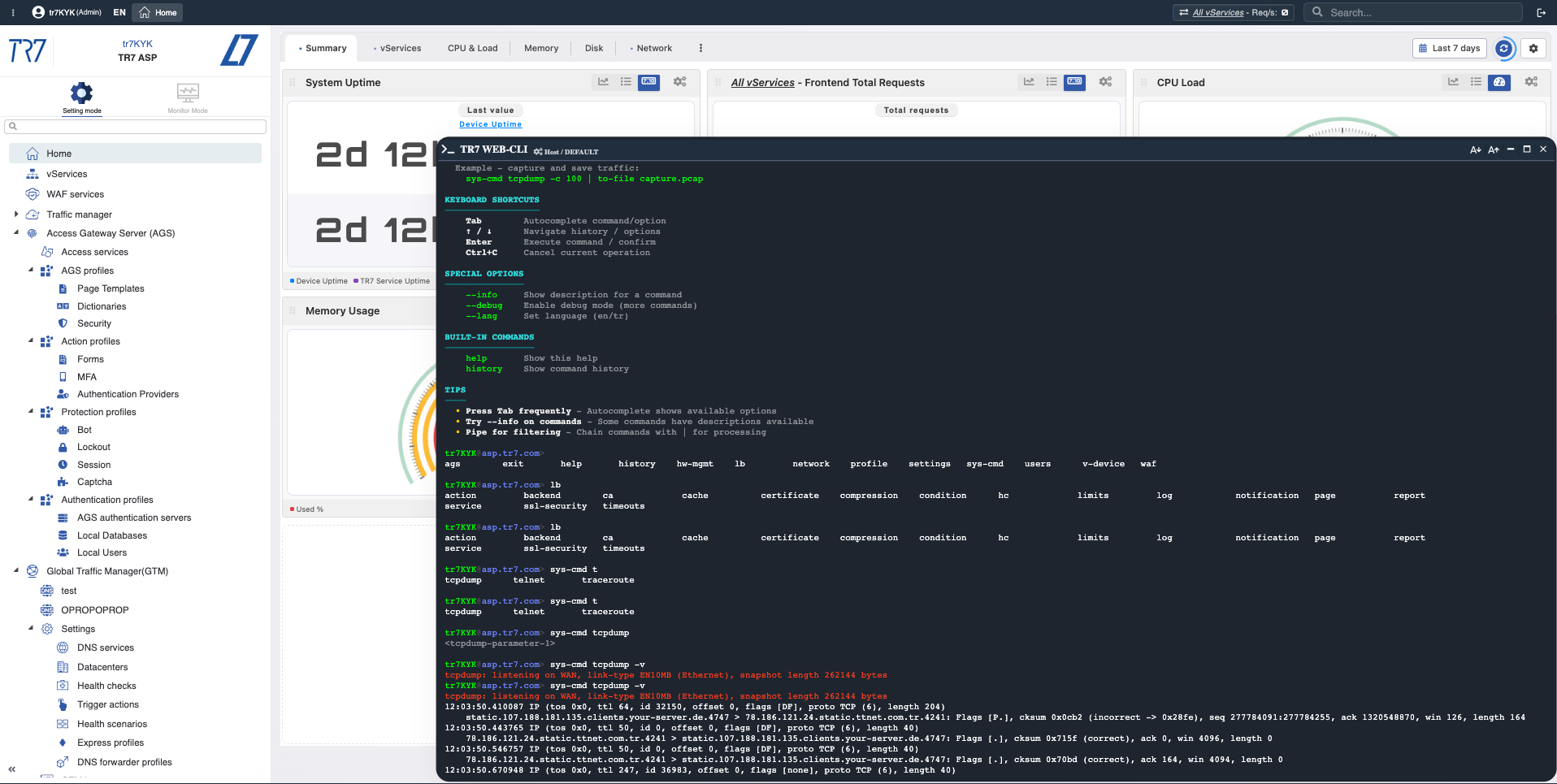
Console Web : vérifier l'hypothèse
Les métriques fournissent une hypothèse ; parfois des commandes sont nécessaires pour la vérification. Exécutez ping, traceroute, curl, tcpdump depuis la Console Web. Pas de SSH requis — les résultats apparaissent sur le même écran.
Console Web : Commandes de diagnostic depuis l'interface web — connectivité backend, DNS, vérification de route effectuée rapidement.
Sortie de commande : Résultats affichés instantanément — exemple de capture de trafic ciblé avec tcpdump.
Console Web et CLI TR7 : diagnostics instantanés et collecte de preuves depuis l'interface
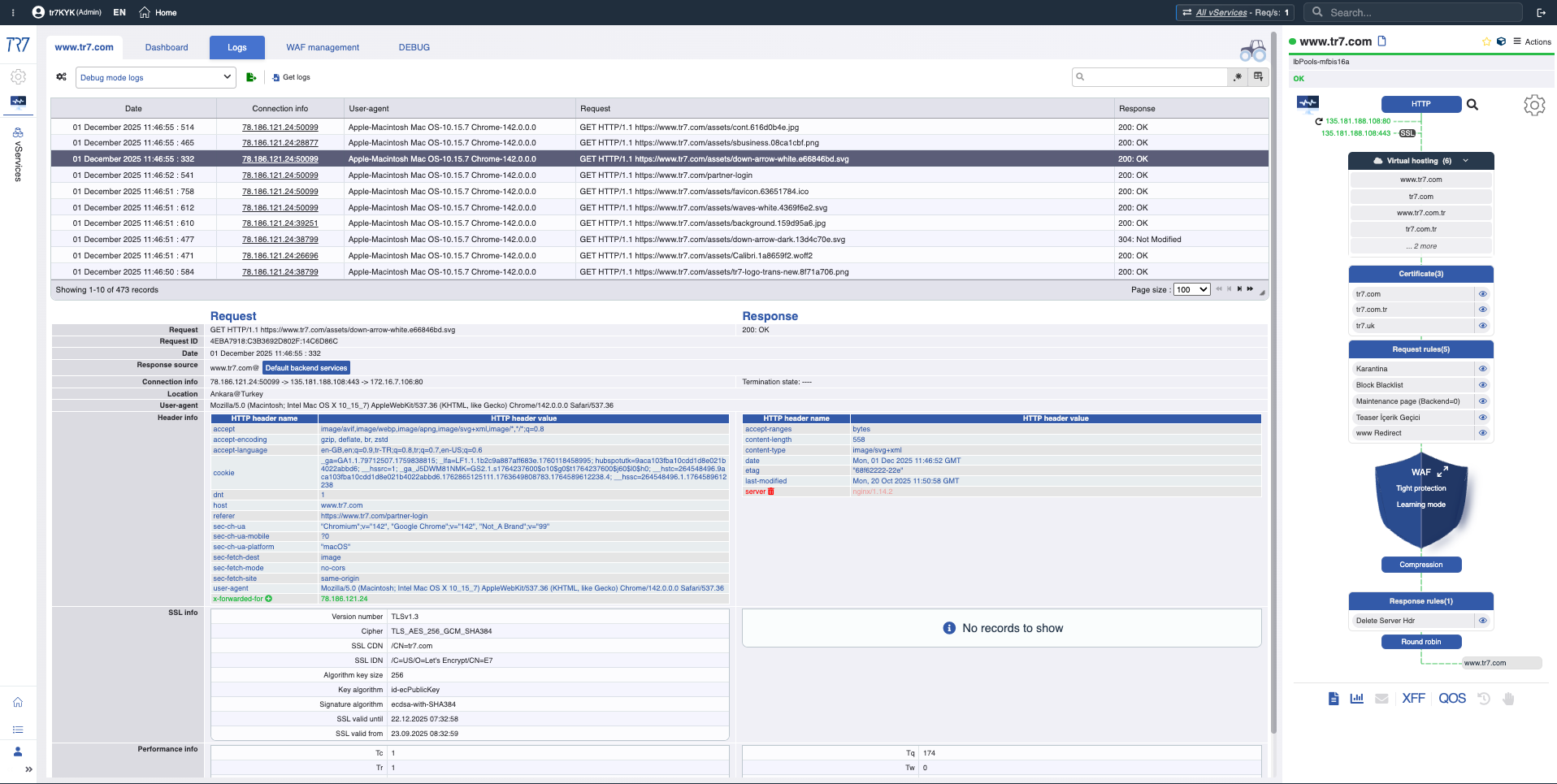
L'investigation sur TR7 ne s'arrête pas aux graphiques. La Console Web permet d'exécuter les commandes système et réseau les plus nécessaires depuis l'interface web en production. Pas de SSH requis. Le CLI TR7 apporte la même capacité à la ligne de commande ; les formats de sortie (JSON/CSV/tab) et les commandes pipe rendent les étapes d'investigation reproductibles.
Résultat : DDoS, bot ou trafic légitime — décider avec des données
Backend 'rapide' mais l'utilisateur dit 'lent'
L'équipe d'application ne voit aucun problème
curl -w '%{time_total}' http://backend/api → Temps du point de vue de l'ADC
wrk -t2 -c10 -d10s http://backend/api → Test sous charge
Résultat : Chaîne Client–ADC–backend — la différence devient claire
N'activez pas le débogage — ciblez-le.
Bibliothèque de métriques : surveillance rétrospective et graphiques d'analyse
Les titres ci-dessous sont les titres de groupes de graphiques de métriques dans l'interface de TR7. Chaque groupe contient des graphiques où les métriques associées peuvent être surveillées et analysées rétrospectivement. Ces graphiques vous permettent d'examiner des plages de temps spécifiques pendant ou après un incident, de voir les tendances et de détecter les anomalies.
Total de requêtes Frontend
Total de requêtes
What?Affiche le nombre total de requêtes HTTP/HTTPS vers le service au fil du temps.
Why important?Référence fondamentale pour comprendre les pics de trafic, les chutes soudaines et l'impact sur la capacité. Permet la comparaison avant/après incident.
Distribution des codes d'état Frontend
Distribution des codes d'état
What?Affiche la distribution des codes de réponse HTTP (2xx succès, 3xx redirection, 4xx erreur client, 5xx erreur serveur) au fil du temps.
Why important?Repérer rapidement les augmentations du taux d'erreur. Un pic 5xx peut indiquer des problèmes backend ; un pic 4xx peut indiquer des problèmes côté client ou de configuration.
Nouvelles connexions Frontend
Nouvelles connexions
What?Affiche les nouvelles connexions TCP ouvertes par seconde.
Why important?Une augmentation soudaine des connexions peut indiquer des attaques DDoS, une activité de bot ou des problèmes de reconnexion côté client.
Sessions concurrentes Frontend
Sessions concurrentes
What?Affiche le nombre de sessions actives simultanément.
Why important?Aide à comprendre à quel point vous êtes proche des limites de capacité. L'approche des limites de session peut causer une dégradation des performances.
Débit Frontend
Débit
What?Affiche le volume total de données passant par le service (bits/sec ou octets/sec).
Why important?Utilisé pour comprendre l'utilisation de la bande passante et les tendances de trafic. Les chutes de débit peuvent indiquer des problèmes réseau ou backend.
Connexions concurrentes SSL
Concurrence SSL
What?Affiche le nombre de connexions TLS chiffrées actives simultanément.
Why important?Les opérations SSL/TLS sont gourmandes en CPU ; cette métrique est critique pour la planification de capacité et l'analyse des performances.
Nouvelles connexions SSL (TPS)
TPS poignée de main TLS
What?Affiche les poignées de main TLS effectuées par seconde.
Why important?Une augmentation soudaine du taux de poignée de main peut indiquer que la réutilisation de session ne fonctionne pas ou des problèmes côté client. Des taux de poignée de main élevés augmentent la charge CPU.
Réutilisation de session SSL
Réutilisation de session SSL
What?Affiche le taux de réutilisation de session TLS et les statistiques.
Why important?Une faible réutilisation de session cause une utilisation CPU inutile et une latence plus élevée. Cette métrique guide l'optimisation des performances TLS.
Compression
Compression
What?Affiche le taux de compression de réponse HTTP et le volume de données compressées.
Why important?La compression économise la bande passante mais utilise du CPU. Comprendre cet équilibre est important pour l'optimisation des performances.
Requêtes bloquées WAF
Requêtes bloquées WAF
What?Affiche le nombre de requêtes bloquées par le Web Application Firewall au fil du temps.
Why important?Une augmentation soudaine des blocages peut indiquer une vague d'attaque ou une nouvelle règle produisant des faux positifs. Dans les deux cas, une investigation est nécessaire.
Requêtes d'attaque détectées WAF
Attaques détectées WAF
What?Affiche le nombre et les types de tentatives d'attaque détectées par le WAF.
Why important?Permet de suivre le niveau de menace et les tendances d'attaque. Comprendre quels types d'attaque sont tentés et à quelle fréquence est précieux pour la stratégie de sécurité.
Distribution d'inspection WAF
Distribution d'inspection WAF
What?Affiche quelle proportion de règles et catégories WAF sont déclenchées.
Why important?Montre quels ensembles de règles sont actifs et lesquels se déclenchent le plus souvent. Données fondamentales pour les décisions d'ajustement et d'optimisation de règles.
Bande passante Frontend
Bande passante
What?Affiche la bande passante entrante et sortante utilisée par le service.
Why important?Utilisé pour surveiller la saturation de liaison et les changements de débit. L'approche des limites de bande passante peut causer des problèmes de performances.
Cache Frontend
Cache
What?Affiche le comportement du cache du service, les données écrites dans et lues depuis le cache.
Why important?La mise en cache réduit la charge backend et améliore les temps de réponse. Les changements de comportement du cache affectent directement les performances.
Taux de succès du cache Frontend
Taux de succès du cache
What?Affiche quel pourcentage de requêtes sont servies depuis le cache.
Why important?Un taux de succès élevé réduit la charge backend et raccourcit les temps de réponse. Les chutes de taux de succès nécessitent d'investiguer la configuration du cache ou les changements de contenu.
Utilisation CPU vService
Utilisation CPU vService
What?Affiche le pourcentage d'utilisation CPU attribué à ce service.
Why important?Permet de voir combien de CPU un seul service consomme. Un service utilisant un CPU excessif peut affecter les autres.
Utilisation mémoire vService
Utilisation mémoire vService
What?Affiche l'utilisation mémoire attribuée à ce service.
Why important?La surveillance de la consommation mémoire par service aide à détecter les fuites mémoire ou les problèmes d'utilisation excessive de ressources.
% Utilisation mémoire vService
% Mémoire vService
What?Affiche l'utilisation mémoire du service en pourcentage.
Why important?Utilisé pour l'analyse de tendance et la planification de capacité. Une utilisation mémoire en augmentation continue peut signaler un problème.
Temps de fonctionnement vService
Temps de fonctionnement vService
What?Affiche le temps écoulé depuis le dernier redémarrage du service.
Why important?Permet de corréler les redémarrages de service avec les chronologies d'incident. Les redémarrages inattendus nécessitent une investigation.
Distribution des requêtes Backend
Distribution des requêtes Backend
What?Affiche comment les requêtes entrantes sont distribuées entre les serveurs backend.
Why important?Permet de détecter une distribution de charge déséquilibrée. Un backend recevant de manière disproportionnée plus ou moins de requêtes peut indiquer des problèmes de configuration ou de santé.
Distribution du temps de réponse Backend
Distribution du temps de réponse Backend
What?Affiche comparativement le temps de réponse moyen de chaque serveur backend.
Why important?Permet d'identifier rapidement les backends lents. Si le temps de réponse d'un backend est significativement plus élevé que les autres, il peut y avoir un problème avec ce serveur.
Santé Backend
Santé Backend
What?Affiche les résultats de vérification de santé et l'état de santé pour chaque serveur backend.
Why important?Permet de voir instantanément quels backends sont sains, en panne ou dégradés.
Timing de vérification de santé Backend
Timing de vérification de santé
What?Affiche à quelle fréquence les vérifications de santé s'exécutent et leurs temps de réponse.
Why important?Permet de détecter les problèmes de timing de vérification de santé. Des réponses de vérification de santé lentes peuvent retarder la détection d'un backend problématique.
Distribution du temps de connexion Backend
Distribution du temps de connexion
What?Affiche la distribution du temps d'établissement de connexion aux backends.
Why important?Aide à détecter les retards réseau et les problèmes de connexion TCP. Un temps de connexion élevé indique des problèmes réseau ou côté backend.
Distribution des connexions Backend
Distribution des connexions
What?Affiche la distribution des connexions actives entre les backends.
Why important?Permet de surveiller le comportement de session sticky et l'équilibrage de charge. Une accumulation disproportionnée de connexions sur un backend peut causer des problèmes de performances.
Distribution de bande passante IN Backend
Distribution de bande passante IN
What?Affiche la distribution de bande passante du trafic allant vers les backends.
Why important?Permet de voir quels backends reçoivent combien de trafic. Un backend recevant un trafic excessif peut devenir un goulot d'étranglement.
Distribution de bande passante OUT Backend
Distribution de bande passante OUT
What?Affiche la distribution de bande passante du trafic de réponse depuis les backends.
Why important?Aide à comprendre les tailles de réponse backend et les modèles de trafic. Les backends produisant de grandes réponses affectent la planification de bande passante.
Distribution des sessions Backend
Distribution des sessions
What?Affiche la distribution des sessions actives entre les backends.
Why important?Permet de surveiller le comportement de persistance de session et la densité de session par backend.
Distribution de file d'attente Backend
Distribution de file d'attente
What?Affiche l'état de file d'attente des requêtes en attente d'être routées vers les backends.
Why important?L'accumulation de file d'attente est un signal précoce de capacité backend insuffisante. À mesure que les files d'attente se remplissent, les temps de réponse augmentent.
Bande passante réseau - WAN
Bande passante WAN
What?Affiche le volume total de trafic passant par l'interface WAN.
Why important?Permet de voir à quel point vous êtes proche de la capacité de liaison. La saturation de liaison cause des pertes de paquets et une augmentation de latence.
Paquets réseau - WAN
Paquets WAN
What?Affiche les paquets traités par seconde (PPS).
Why important?Les anomalies PPS peuvent indiquer des attaques DDoS ou des problèmes réseau. Un PPS élevé avec une faible bande passante indique une inondation de petits paquets.
État réseau - WAN
État WAN
What?Affiche l'état opérationnel de l'interface réseau (up/down) et la qualité de liaison.
Why important?Permet de détecter instantanément les changements d'état de liaison. Les liaisons intermittentes en panne causent des problèmes de connectivité.
Erreurs d'interface réseau
Erreurs d'interface
What?Affiche les erreurs se produisant sur l'interface (CRC, collision, drop, etc.).
Why important?Les erreurs d'interface peuvent indiquer des problèmes de câble physique, des non-concordances MTU ou des défaillances matérielles.
Unités d'interface (WAN)
Unités d'interface
What?Affiche l'état des sous-interfaces et VLANs.
Why important?Permet de surveiller l'état de chaque sous-unité séparément dans des topologies réseau complexes.
Utilisation CPU de l'appareil
CPU de l'appareilCPU système
What?Affiche le pourcentage total d'utilisation CPU de l'appareil.
Why important?Une utilisation CPU élevée affecte les performances de tous les services. Un CPU constamment élevé nécessite une augmentation de capacité ou une optimisation.
Température CPU de l'appareil
Température CPU
What?Affiche la température de fonctionnement du CPU.
Why important?Une température élevée peut causer une limitation thermique et une dégradation des performances. Une augmentation excessive de température accroît le risque de défaillance matérielle.
Temps de fonctionnement système
Temps de fonctionnement système
What?Affiche le temps écoulé depuis le dernier démarrage de l'appareil.
Why important?Permet de détecter les redémarrages inattendus. Si le temps de fonctionnement a été réinitialisé, investiguer pourquoi l'appareil a redémarré.
Charge système
Charge systèmeMoyenne de charge
What?Affiche les moyennes de charge système sur 1, 5 et 15 minutes.
Why important?Aide à comprendre à quel point le système est occupé. Si la moyenne de charge dépasse constamment le nombre de CPU, le système est surchargé.
Utilisation totale de mémoire
Utilisation totale de mémoire
What?Affiche la quantité totale de mémoire utilisée par le système.
Why important?Permet de suivre la consommation mémoire au fil du temps. Une utilisation mémoire en augmentation continue peut indiquer une fuite mémoire.
Mémoire disponible
Mémoire disponible
What?Affiche la quantité de mémoire disponible pour les nouveaux processus.
Why important?Une mémoire disponible faible peut empêcher le démarrage de nouvelles connexions et processus.
Ratio d'utilisation de mémoire
% Utilisation mémoire
What?Affiche quel pourcentage de la mémoire totale est utilisé.
Why important?Utilisé pour la planification de capacité et les alertes basées sur des seuils. Une utilisation supérieure à 90% est un niveau critique.
Utilisation du swap
Utilisation du swap
What?Affiche l'utilisation de l'espace de swap sur disque.
Why important?L'utilisation du swap indique que la mémoire physique est insuffisante. Une utilisation active du swap cause une dégradation significative des performances.
Utilisation du disque
Utilisation du disque
What?Affiche la quantité d'espace disque utilisé.
Why important?Permet de surveiller le taux de remplissage du disque. Si le disque se remplit, l'écriture de journal peut s'arrêter et le système peut devenir instable.
Capacité du disque
Capacité du disque
What?Affiche la capacité totale du disque.
Why important?Point de référence pour la planification de capacité et l'analyse des tendances de croissance.
Ratio d'utilisation du disque
% Utilisation du disque
What?Affiche quel pourcentage de la capacité disque est utilisé.
Why important?Au-dessus de 90% est un avertissement, au-dessus de 95% est un niveau critique. Le remplissage du disque nécessite une planification de rotation et d'archivage de journal.
Utilisation des inodes du disque
Utilisation des inodes
What?Affiche l'utilisation des inodes du système de fichiers.
Why important?Même avec de l'espace disque libre, si les inodes sont épuisés, de nouveaux fichiers ne peuvent pas être créés. Critique pour les systèmes avec de nombreux petits fichiers.
Lecture E/S disque
Lecture E/S disque
What?Affiche les opérations de lecture disque par seconde et la vitesse.
Why important?Une E/S de lecture élevée peut indiquer un goulot d'étranglement disque. Particulièrement important pour les systèmes non-SSD.
Écriture E/S disque
Écriture E/S disque
What?Affiche les opérations d'écriture disque par seconde et la vitesse.
Why important?L'écriture de journal et d'audit génère constamment des E/S disque. Si la vitesse d'écriture diminue, un risque de perte de journal se produit.
Latence E/S disque
Latence E/S
What?Affiche le temps moyen de complétion des opérations disque.
Why important?Une latence E/S élevée est un signal précoce de dégradation des performances disque. L'augmentation de latence affecte les performances globales du système.
Nombre de connexions TCP
Connexions TCP
What?Affiche le nombre total de connexions TCP sur le système.
Why important?Permet de voir si vous approchez des limites de connexion. Si la limite de connexion est dépassée, les nouvelles connexions sont rejetées.
TCP Established
Connexions établies
What?Affiche le nombre de connexions transférant activement des données.
Why important?Indicateur de charge de travail réelle. Le nombre de connexions établies est directement lié à la capacité.
TCP TIME_WAIT
TIME_WAIT
What?Affiche le nombre de connexions en attente dans l'état TIME_WAIT.
Why important?Un nombre TIME_WAIT élevé indique un risque d'épuisement de port. Les connexions courtes et le trafic intense causent une accumulation TIME_WAIT.
TCP CLOSE_WAIT
CLOSE_WAIT
What?Affiche le nombre de connexions en attente dans l'état CLOSE_WAIT.
Why important?Un nombre CLOSE_WAIT élevé indique que l'application ne ferme pas correctement les connexions. C'est généralement un bug côté application.
Retransmission TCP
Retransmissions
What?Affiche le nombre de retransmissions de paquets TCP.
Why important?L'augmentation de retransmission indique des problèmes de qualité réseau, des pertes de paquets ou une congestion. Un taux de retransmission élevé cause une augmentation de latence et une baisse de débit.
Total de requêtes vService
Total de requêtes vService
What?Affiche le nombre total de requêtes pour tous les vServices dans un seul graphique.
Why important?Permet de comprendre le volume de trafic total et les tendances sur l'appareil. Référence fondamentale pour la planification de capacité et l'évaluation de charge globale.
Total de connexions vService
Total de connexions vService
What?Affiche le nombre total de connexions actives pour tous les vServices.
Why important?Permet de surveiller la pression de connexion et l'utilisation de la table de connexions sur l'appareil. L'approche des limites de table de connexions peut causer le rejet de nouvelles connexions.
Intégrations : disponibles, mais l'investigation n'en dépend pas
TR7 peut s'intégrer à l'écosystème de surveillance et de gestion de journaux de votre organisation. La différence critique : l'investigation d'incident ne dépend pas uniquement des pipelines externes. Les systèmes externes ajoutent de la valeur ; les enregistrements sur l'appliance servent de référence fondamentale.
Questions fréquemment posées
L'objectif est d'avoir les données nécessaires à l'investigation toujours prêtes sur l'appliance. L'exportation externe et l'archivage centralisé sont pris en charge. Cependant, le succès de l'investigation ne dépend pas uniquement de la configuration d'exportation.
L'objectif n'est pas de tout regarder tout le temps. Les catégories, la recherche et le filtrage vous permettent d'atteindre rapidement le bon signal lorsque nécessaire.
L'objectif de la Console Web n'est pas un accès non restreint mais des diagnostics contrôlés. Lorsqu'elle est utilisée avec une autorisation appropriée et des runbooks, elle raccourcit le temps d'investigation.
Il est en temps réel. Les états de service sont surveillés au runtime et les changements sont immédiatement reflétés comme des changements de couleur. De plus, des enregistrements de métriques et d'événements rétrospectifs sont conservés.
Le débogage normal capture généralement tout le trafic et nécessite un filtrage par la suite. Le débogage ciblé capture les enregistrements uniquement pour un host, port, path ou header spécifique dès le départ. Cela réduit le bruit, accélère l'investigation et minimise l'impact sur la production.
TR7 prend en charge l'exportation Prometheus et le transfert de journaux SIEM. Les intégrations conservent leur valeur. La différence : les données nécessaires à l'investigation ne dépendent pas uniquement des systèmes externes — elles sont aussi prêtes sur l'appliance.
La période de rétention est configurable. Ce qui compte, c'est que les actions utilisateur et les changements de configuration sont conservés sur la même chronologie que les métriques et les enregistrements d'événements.
Le détail est une préparation, pas une complexité. Même dans les petites équipes, atteindre rapidement les bonnes données lors d'un incident fait gagner du temps. La structure catégorisée et les fonctionnalités de recherche facilitent la concentration uniquement sur les données nécessaires.
Conclusion
L'affirmation de TR7 n'est pas 'plus de graphiques' — c'est de rendre la couche ADC/WAF prête pour l'investigation. Les métriques vService/backend/interface, les enregistrements d'événements/notifications, la piste d'audit et la visibilité HTTP/WAF se combinent sur une chronologie unique ; la forensics rétrospective et le débogage ciblé accélèrent l'analyse des causes profondes.
Les intégrations d'exportation sont précieuses ; mais pour minimiser le risque 'n'a pas été envoyé, donc n'existe pas' pendant les moments critiques, la chaîne de preuves doit rester accessible à l'intérieur du produit en permanence.
Ces capacités et d'autres similaires — des détails qui n'apparaissent pas sur les fiches techniques, sont difficiles à saisir dans les démos, mais définissent la qualité opérationnelle en pratique — sont la raison principale pour laquelle presque toutes les organisations qui évaluent TR7 décident de faire le changement.