Üretimde bir sorun çıktığında üç soru öne çıkar: Ne oldu? Ne zaman oldu? Neden oldu?
Cevaplar çoğu zaman dağınıktır. Çünkü metrikler ayrı, trafik logları ayrı, değişiklik kayıtları ayrı yerlerde durur.
Bir diğer gerçek de şudur: Dış sistemlere genellikle sadece seçilen veriler gönderilir. Olay anında ihtiyaç duyduğunuz sinyal daha önce seçilmediyse, elinizde yoktur.
TR7’nin yaklaşımı net: Export entegrasyonları önemlidir, ama investigation tek başına onlara bağlı kalmamalı. Bu yüzden TR7, kritik sinyalleri cihaz üzerinde aynı zaman çizgisinde toplar.
Gönderilmeyen sinyal, görünmeyen risktir.
Neden sadece dışa export yeterli olmaz?
SIEM, log sunucuları, Prometheus/Grafana gibi platformlar kurumsal görünürlük için değerlidir. Ancak olay incelemesinin başarısı, doğru verinin o anda mevcut olmasına bağlıdır.
Seçici toplama kaçınılmazdır
Maliyet ve gürültü nedeniyle her metrik/log gönderilmez. Olay anında kritik sinyal yoksa inceleme yavaşlar.
Veri dağıldıkça korelasyon zorlaşır
Metrik, event, audit ve trafik logları farklı yerlerdeyse tek bir zaman çizelgesi kurmak daha uzun sürer.
Pipeline ek bir risk alanıdır
Agent, network, kota/limit veya indeksleme sorunları nedeniyle olay sırasında veri kaçabilir.
Investigation-Ready
Veri toplamak için değil, çözmek için zaman harca. TR7, kritik sinyalleri cihaz üzerinde hazır tutar.
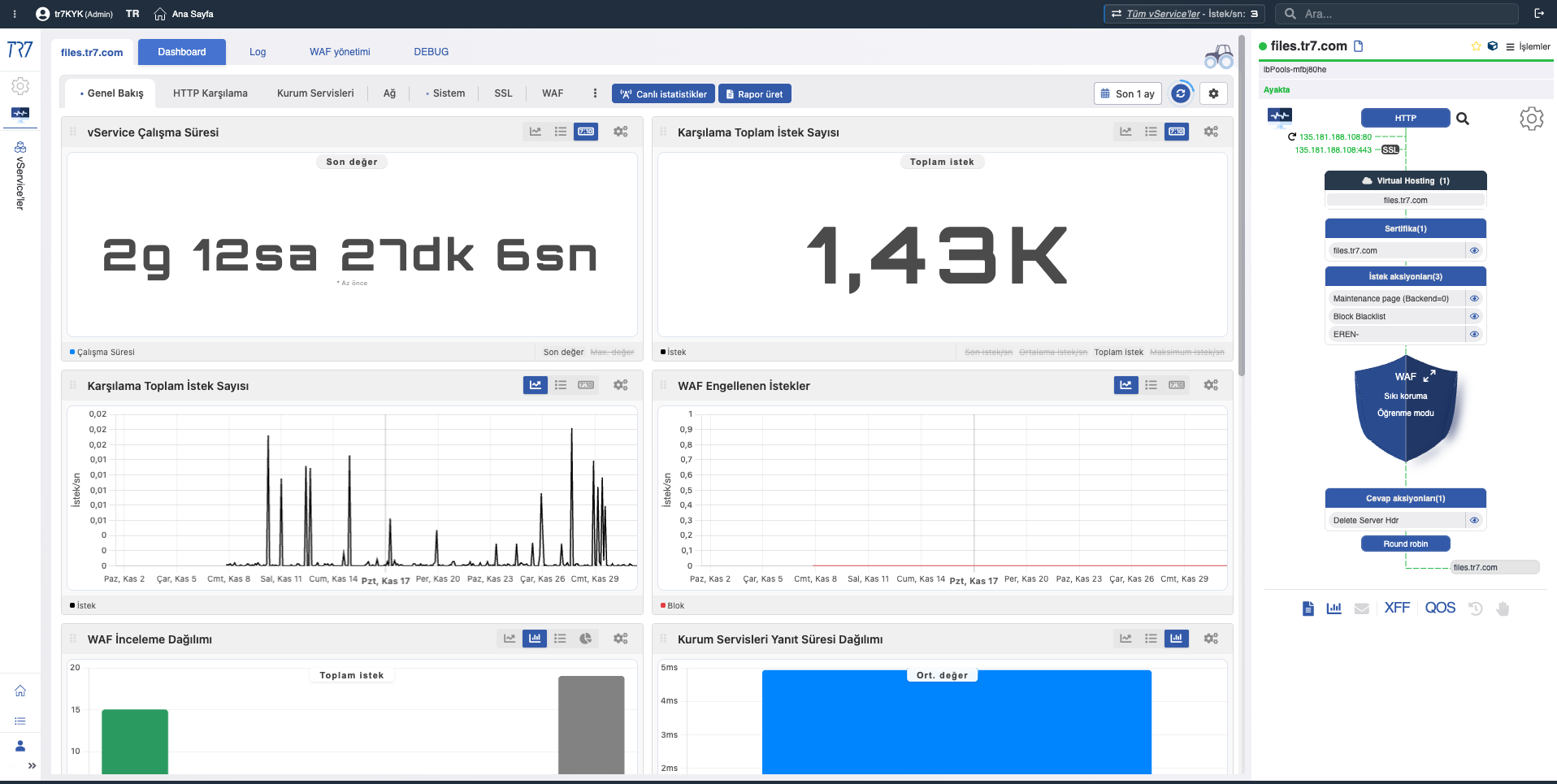
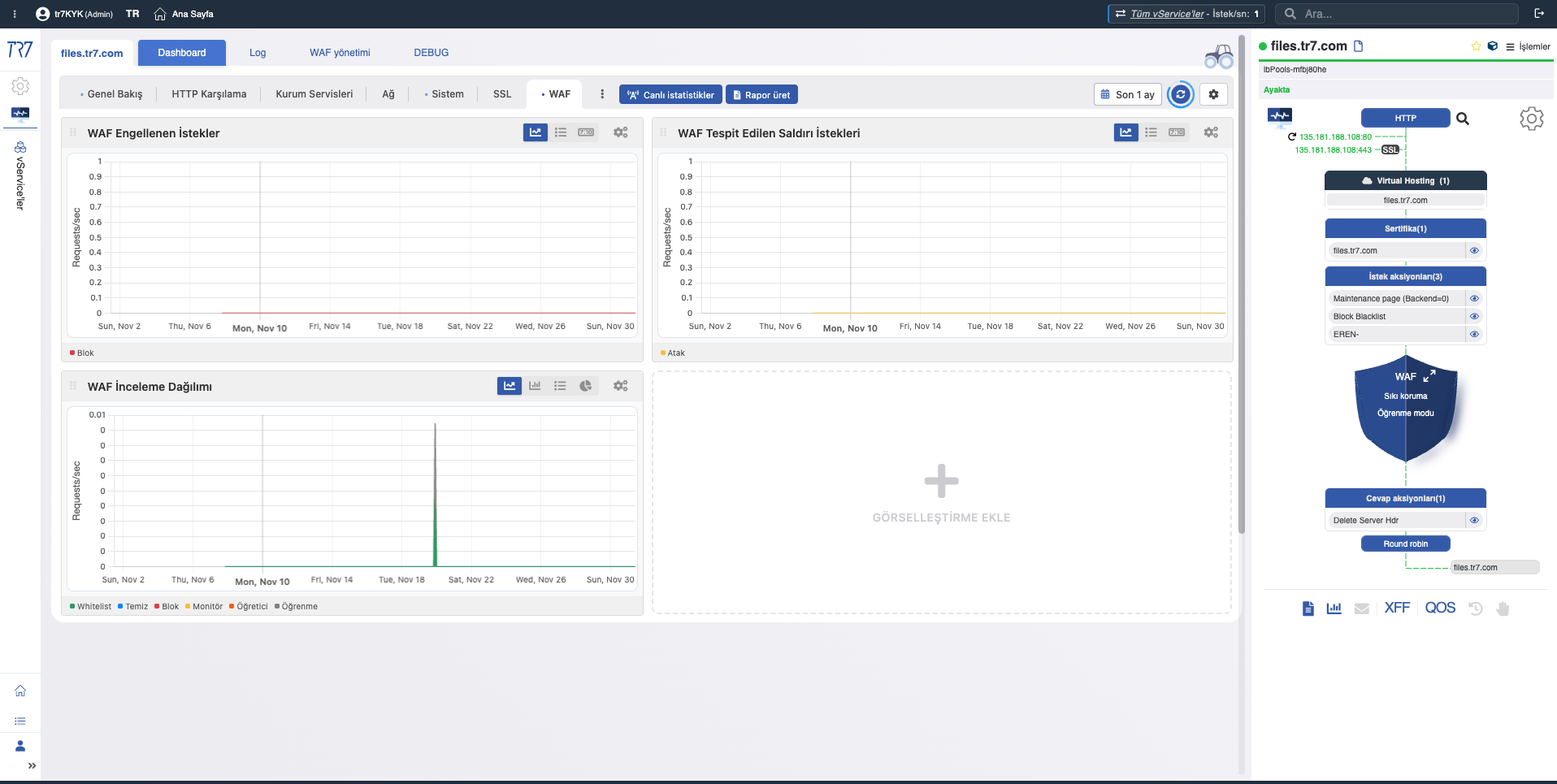
Dynamic Flow Panel: runtime görünürlük ve hızlı başlangıç noktası
TR7 arayüzünde servis topolojisi Dynamic Flow Panel üzerinden canlı (runtime) izlenebilir. Complete Control →
Panel, servislerin anlık durumunu renklerle gösterir. Örneğin servisin dinlediği IP’nin bağlı olduğu interface link’i düşerse sistem uyarı üretir ve servis adı yeşilden sarıya döner.
Bu sayede operatör neyi inceleyeceğini hemen görür. Triage daha hızlı başlar ve inceleme süresi kısalır.
Durum Renkleri
Flow Panel’deki renkler servis durumunu hızlı okumanız için kullanılır:
Yeşil: Normal
Servis bağlantıları ve sağlık kontrolleri beklenen şekilde çalışıyor.
Tüm backend’ler healthy
Interface link’leri up
Health-check’ler geçiyor
Rutin izleme
Sarı: Dikkat
Takip edilmesi gereken bir durum var.
Interface link down (servis çalışıyor olabilir)
Bir backend health-check başarısız
Kaynak eşiğine yaklaşma
Metrikler + notification + audit ile hızlı kontrol
Kırmızı: Kritik
Hizmeti etkileyen problem var.
Backend’ler down
vService erişilemiyor
Kritik konfig hatası
Hızlı triage: metrik + event + audit
Örnek Investigation Senaryoları
Aşağıdaki örnekler, TR7 üzerinde tipik bir incelemenin nasıl ilerlediğini gösterir.
Senaryo A: Gecikme (latency) artışı
Şikayet: 'Uygulama yavaşladı'
vService yanıt süresi trendine bak → spike var mı?
Backend yanıt süresi dağılımını kontrol et → yavaş backend hangisi?
Health-check ve bağlantı dağılımlarıyla doğrula
Notification kayıtlarında aynı zaman aralığında kaynak uyarısı var mı?
Audit trail: yakın zamanda değişiklik olmuş mu?
Sonuç: LB katmanı mı, belirli backend mi — hızlı netleşir
Senaryo B: WAF engellemeleri arttı
Şikayet: 'Form gönderilemiyor'
WAF blocked metriğine bak → spike var mı?
HTTP/WAF loglarından tetiklenen kuralı bul
İstek detayından false positive mi gerçek saldırı mı ayrıştır
Audit trail: kural/policy değişikliği var mı?
Gerekirse hedefli debug ile sadece ilgili trafiği incele
Sonuç: Kural tuning veya güvenlik aksiyonu — veriyle karar
Cihaz Genel Bakış: Investigation başlangıç noktası
Olay incelemesi her zaman cihaz genelinden başlar. CPU, bellek, disk kullanımı ve sistem sağlığı — ilk bakışta cihazın genel durumunu değerlendirin. Geriye dönük forensics için zaman aralığı seçilebilir.
Sistem Özeti: Uptime, toplam istek, CPU yükü, bellek, bant genişliği — olay anında cihazın genel durumunu hızlıca değerlendirin.
Disk & I/O: Doluluk, inode, gecikme, IOPS — log yazımı veya cache performansı etkileniyor mu?
Servis & Backend: Performans ve sağlık metrikleri
Sistem genelinden sonra servis katmanına inmek gerekir. Tüm vService'lerin istek dağılımı, yanıt kodları, backend sağlığı ve Dynamic Flow Panel ile servis topolojisi tek bakışta. Her vService için ayrı dashboard mevcuttur.
vService Genel Bakış: Tüm servislerin istek dağılımı ve yanıt kodları (2xx/3xx/4xx/5xx) — hangi serviste anomali var?
vService Özeti: Uptime, frontend istekleri, WAF engelleme sayısı ve Dynamic Flow Panel — servisin anlık durumu.
Özelleştirilebilir Metrikler: SSL reuse, sıkıştırma, cache hit oranı — investigation için gerekli metrikleri ekleyin.
Backend Dağılımları: Hangi backend yavaş? Hangi backend daha çok istek alıyor? Yanıt süresi ve bağlantı metrikleri.
Ağ & Interface: Bağlantı durumu ve trafik akışı
Sorun serviste mi yoksa ağda mı? Topoloji, bant genişliği, TCP state dağılımı ve interface metrikleri bu sorunun cevabını verir. Link durumu değişiklikleri ve paket hataları ağ katmanındaki sorunları hızlıca ortaya koyar.
Ağ Topolojisi: Bant genişliği, TCP state dağılımı — sorun ağda mı, serviste mi ayrımının ilk ipucu.
Interface Metrikleri: RX/TX bant genişliği, paket sayıları, hatalar — link performansı ve sağlığı.
vService Ağ: Servis bazında throughput ve bağlantı durumları — trafik paterni normal mi?
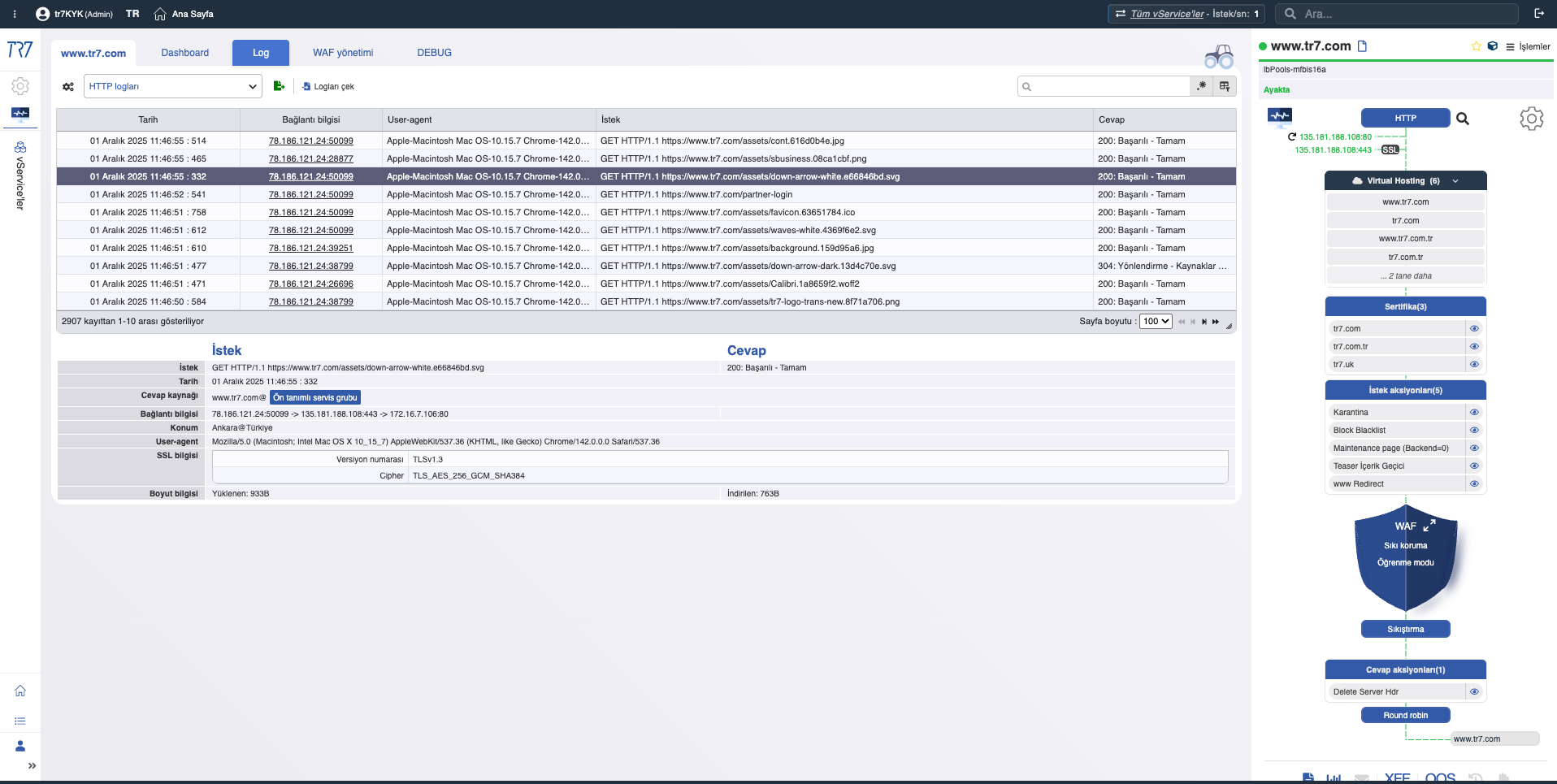
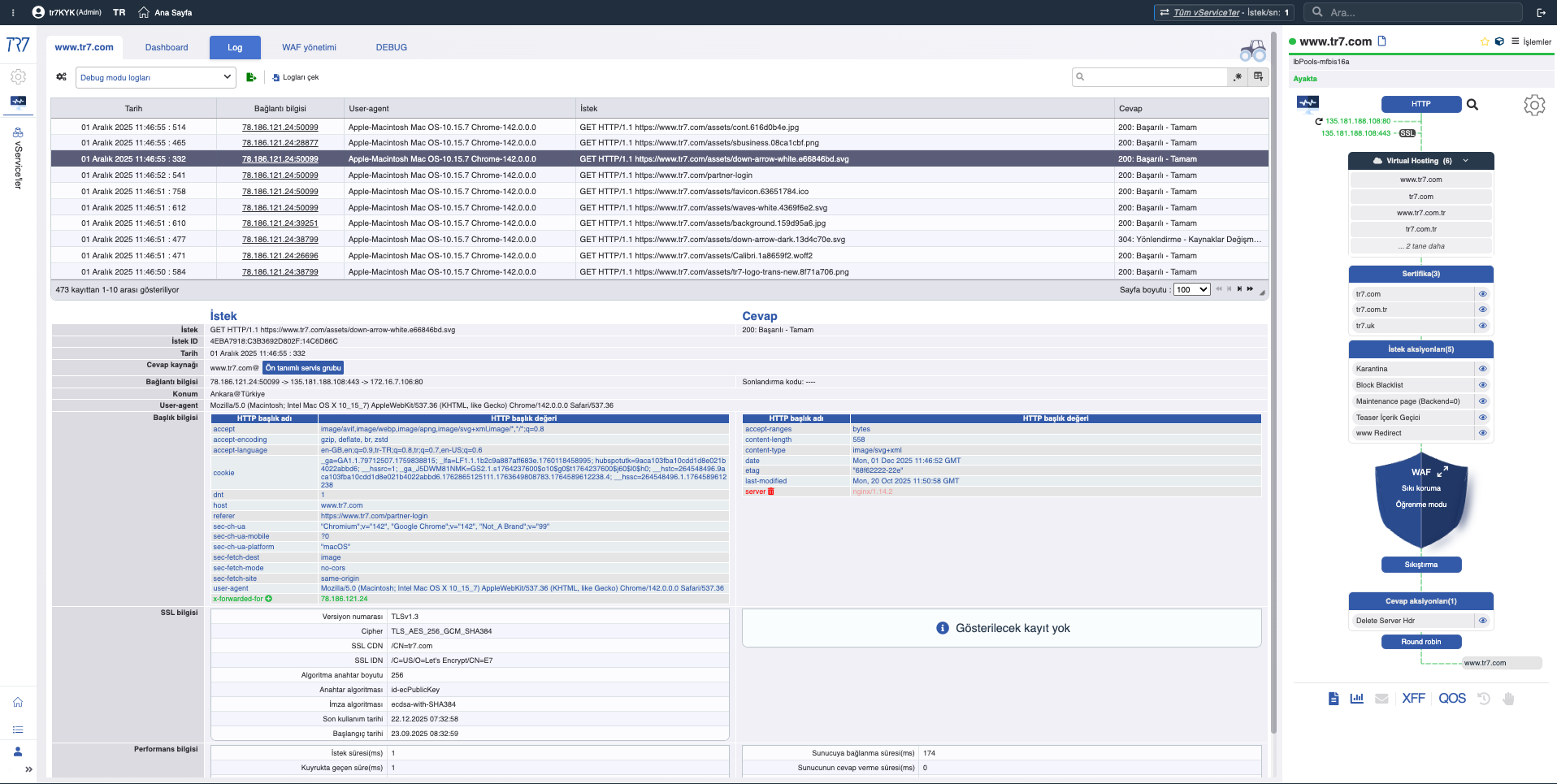
HTTP & WAF Logları: İstek bazlı inceleme
HTTP trafiği ve WAF olayları debug açmadan da görülebilir. Gerektiğinde hedefli debug ile sadece belirli host/path/header için tam detay alınır. Üretimi etkilemeden istek bazlı forensics yapılabilir.
HTTP Logları: Kaynak IP, hedef, yanıt kodu, boyut, süre — debug kapalıyken bile temel görünürlük.
Hedefli Debug: Sadece ilgili trafik için tam header ve cookie bilgileri — üretimi etkilemeden detay.
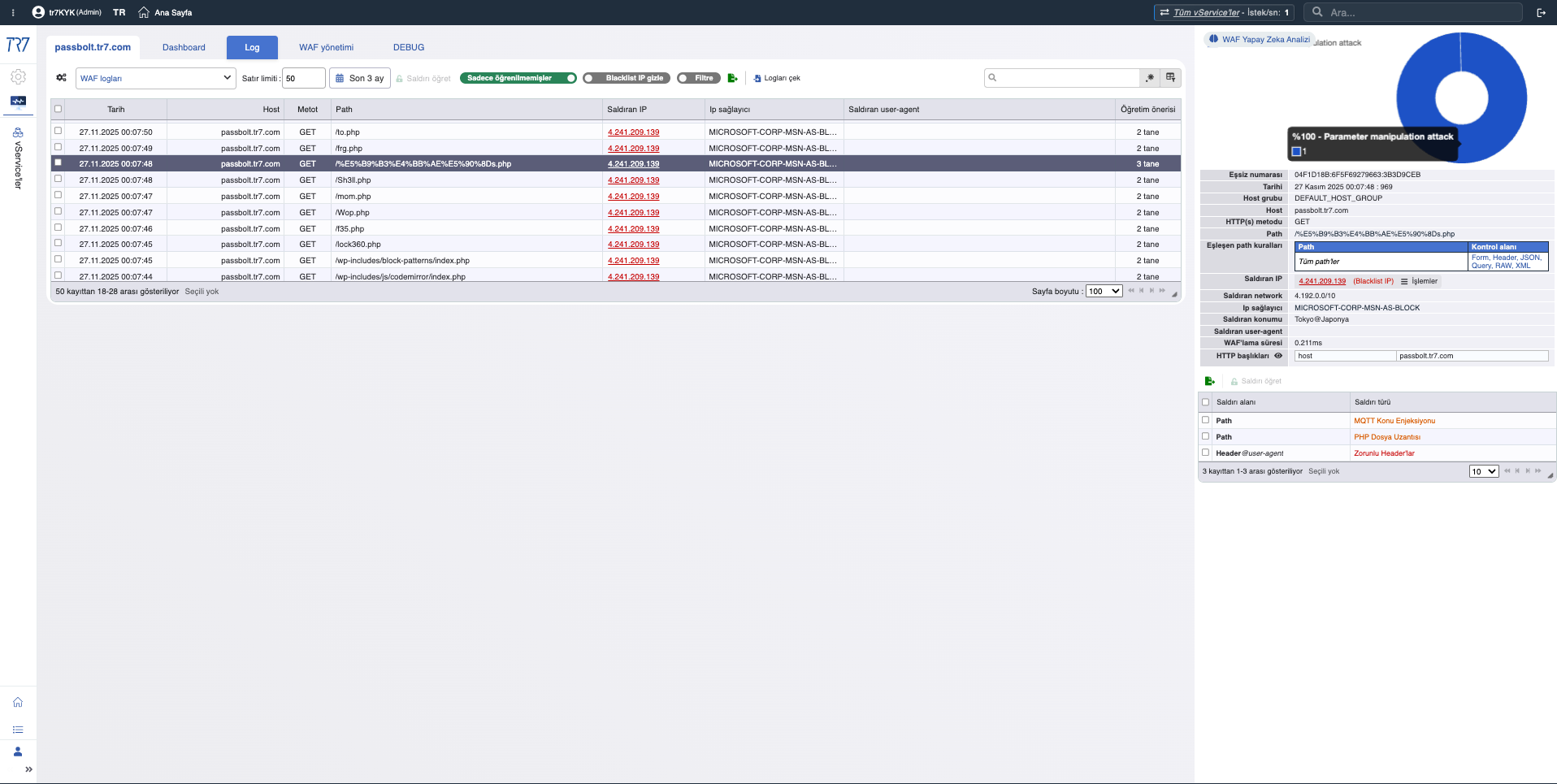
WAF Logları: Tetiklenen kural, istek detayı, AI destekli analiz — false positive değerlendirmesi için veri.
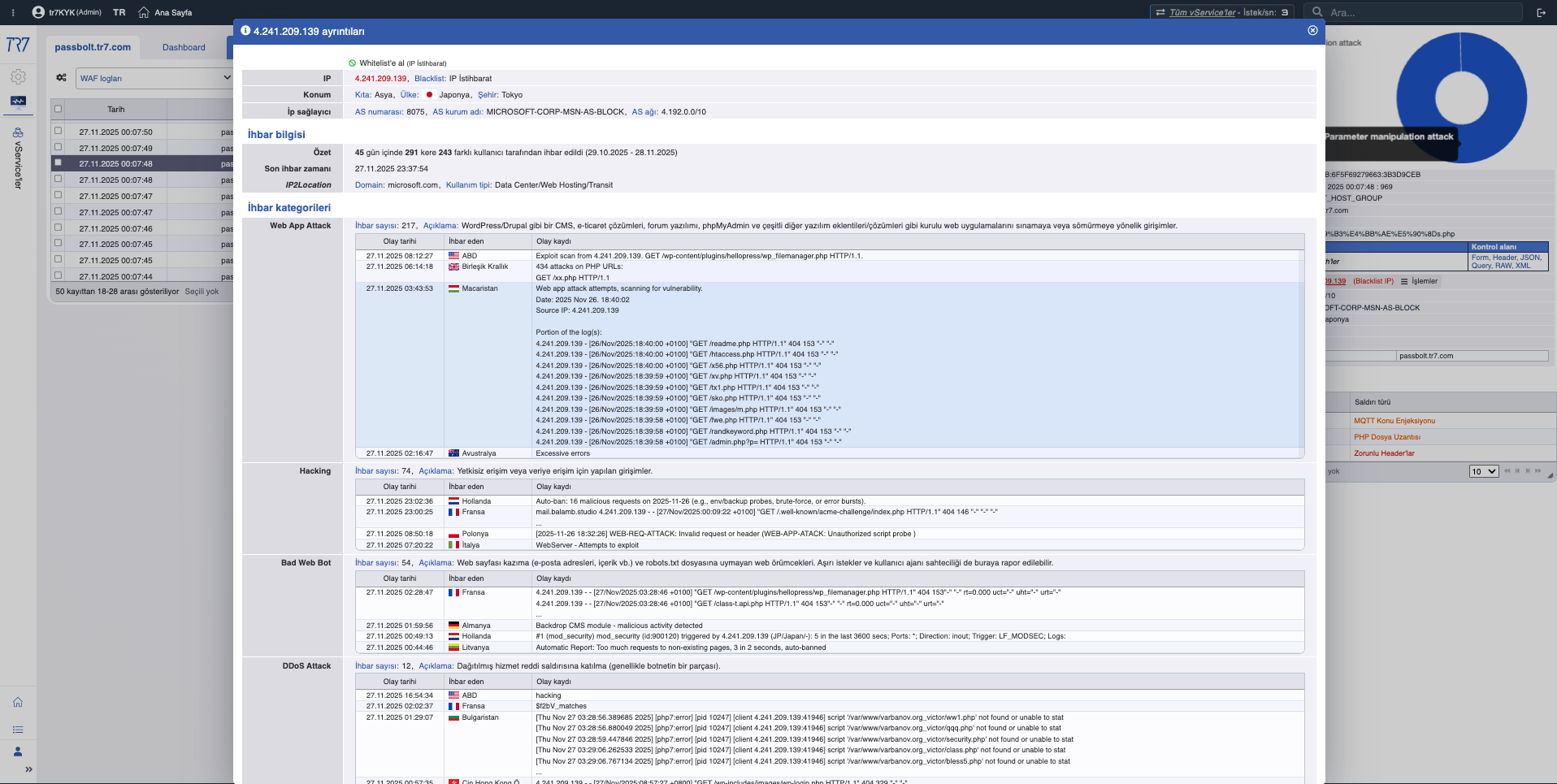
IP Intelligence & WAF: Tehdit profili
IP itibar skorları ve WAF metrikleri saldırgan profilini hızlıca ortaya koyar. False positive mi gerçek saldırı mı sorusunun ilk cevabı burada. Tehdit kategorileri (botnet, proxy, VPN, Tor) kaynak IP'nin niteliğini gösterir.
IP Intelligence: İtibar skoru, tehdit kategorileri — saldırgan profili hızlı netleşir.
WAF Metrikleri: Engelleme trendi, inceleme dağılımı — güvenlik olaylarının genel görünümü.
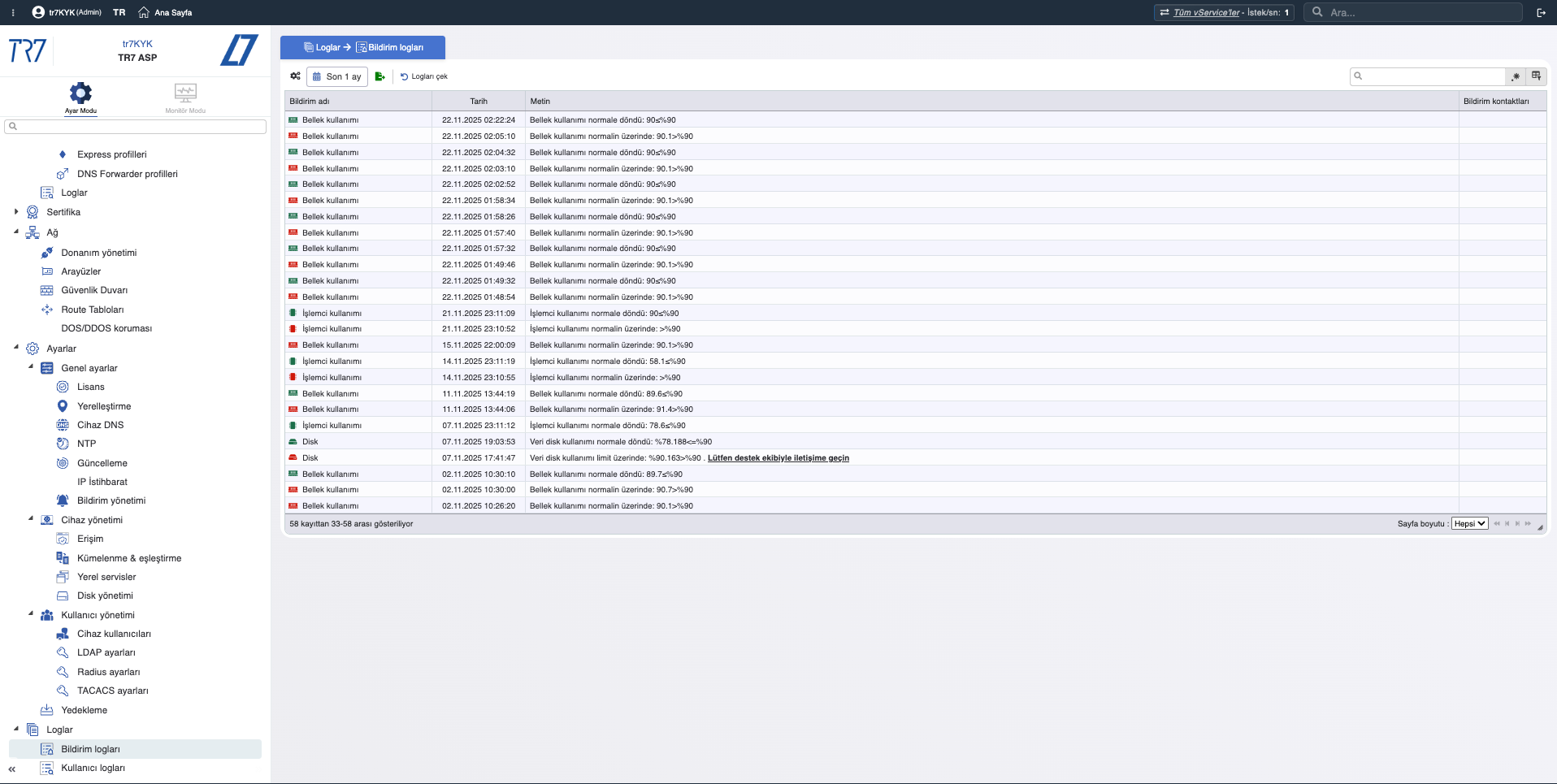
Olay Zaman Çizelgesi: Bildirimler ve audit trail
Metrikler tek başına yetmez. Hangi alarmlar tetiklendi? Kim ne zaman değişiklik yaptı? Olay incelemesinde 'hangi değişiklik neyi etkiledi?' sorusu kritiktir. TR7, notification/event kayıtlarını ve audit trail'i birlikte tutarak bu korelasyonu hızlandırır.
Bildirim Tipleri: CPU, bellek, disk, bandwidth, servis durumu — hangi olaylar izleniyor?
Bildirim Geçmişi: Tetiklenen alarmların kronolojisi — olay anında ne uyarısı geldi?
Audit Trail: Kim, ne zaman, ne değiştirdi? Olayla değişiklik ilişkisini hızlı kurmak için kanıt.
Web Console: Hipotezi doğrula
Metrikler bir hipotez verir, doğrulama için bazen komut gerekir. Web Console üzerinden ping, traceroute, curl, tcpdump gibi araçlar çalıştırılır. SSH bağlantısı gerekmez, sonuç aynı ekranda görülür.
Web Console: Teşhis komutları web arayüzünden — backend erişimi, DNS, rota doğrulaması hızlıca yapılır.
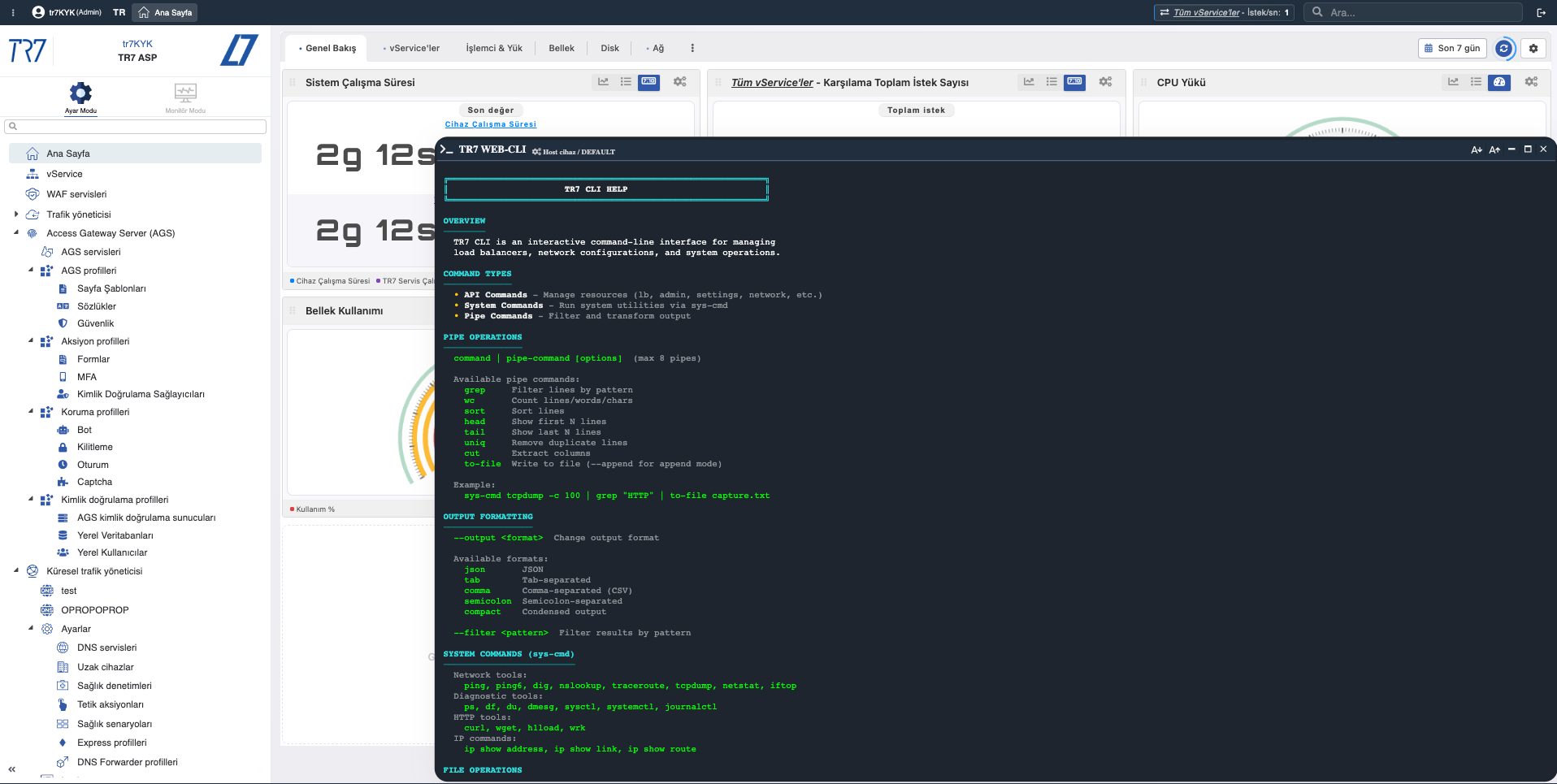
Web Console & TR7 CLI: UI'dan anlık teşhis ve kanıt toplama
TR7'de investigation sadece grafikte kalmaz. Web Console, üretimde en çok ihtiyaç duyulan sistem ve ağ komutlarını web arayüzü üzerinden çalıştırmayı sağlar. SSH bağlantısı gerekmez. TR7 CLI ise aynı işi komut satırı tarafına taşır; çıktı formatları (JSON/CSV/tab) ve pipe komutları ile inceleme adımlarını tekrar edilebilir hale getirir.
Ağ kontrolü: ping, traceroute, dig, iftop
Backend erişimi, DNS çözümlemesi, yol analizi ve anlık bant genişliği dağılımını cihaz üzerinden doğrulayın.
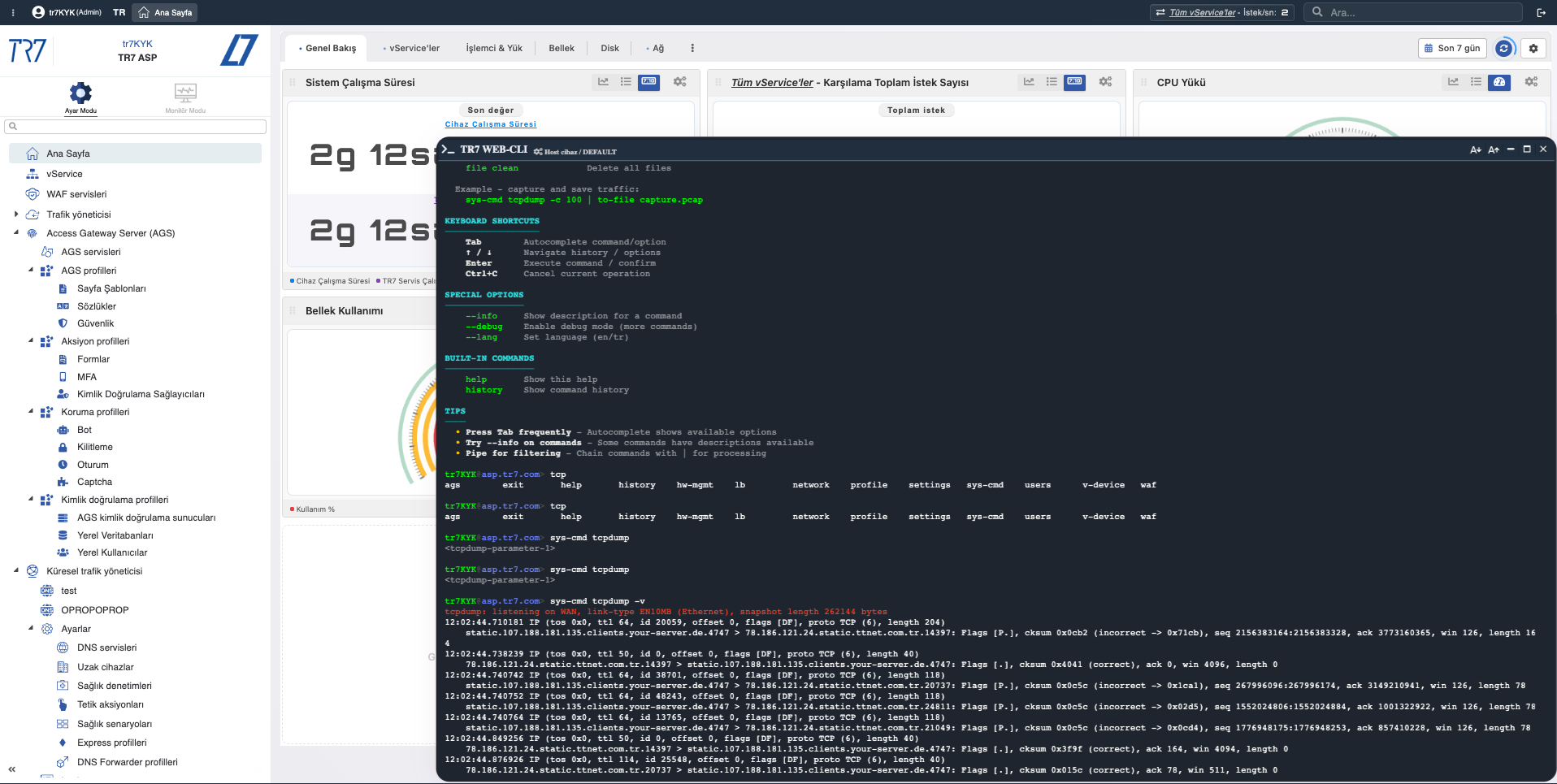
Hedefli trafik yakalama: tcpdump, ssldump
Belirli host/port için paket yakalayın. TLS handshake'i inceleyin. Sadece ilgili trafiği dosyaya alın.
Backend testi: curl, wrk
ADC'nin gördüğü açıdan backend'in yanıt kodunu ve süresini ölçün. Gerekirse kontrollü yük testi uygulayın.
Sistem durumu: netstat, ps, df, journalctl
TCP durumları, prosesler, disk kullanımı ve sistem logları gibi temel verileri tek ekrandan görüntüleyin.
Web Console: Örnek İnceleme Akışları
Flow Panel'de bir uyarı gördünüz. Aşağıdaki akışlar, hızlı ayrıştırma için pratik örneklerdir.
Backend timeout mu, ağ mı?
Metrikler timeout gösteriyor
ping backend-ip → erişim var mı?
curl -I http://backend:8080/health → yanıt kodu ne?
traceroute backend-ip → yol üzerinde kopma var mı?
Sertifika, protokol veya cipher uyumsuzluğunu tespit et
Sonuç: İstemci mi, sunucu konfigürasyonu mu — paketten kanıtla
Ani trafik artışı: saldırı mı, gerçek yük mü?
İstek sayısı aniden arttı
iftop -i wan0 → anlık konuşan uçları gör
netstat -an | grep ESTABLISHED | wc → bağlantı sayısı
tcpdump -c 1000 port 443 | to-file spike.pcap → örnek al
Sonuç: DDoS, bot veya meşru trafik — veri ile karar ver
Backend 'hızlı' ama kullanıcı 'yavaş' diyor
Uygulama ekibi sorun görmüyor
curl -w '%{time_total}' http://backend/api → ADC'nin gördüğü süre
wrk -t2 -c10 -d10s http://backend/api → yük altında test
Sonuç: İstemci–ADC–backend zincirinde fark nerede — netleşir
Debug açmak yerine debug'ı hedefle.
Metrik Kütüphanesi: Geriye Dönük İzleme ve Analiz Grafikleri
Aşağıdaki başlıklar, TR7 arayüzünde yer alan metrik grafiklerinin grup başlıklarıdır. Her grup, ilgili metriklerin geriye dönük olarak izlenip analiz edilebildiği grafikleri içerir. Bu grafikler sayesinde olay anında veya sonrasında belirli bir zaman aralığını inceleyebilir, trendleri görebilir ve anomalileri tespit edebilirsiniz.
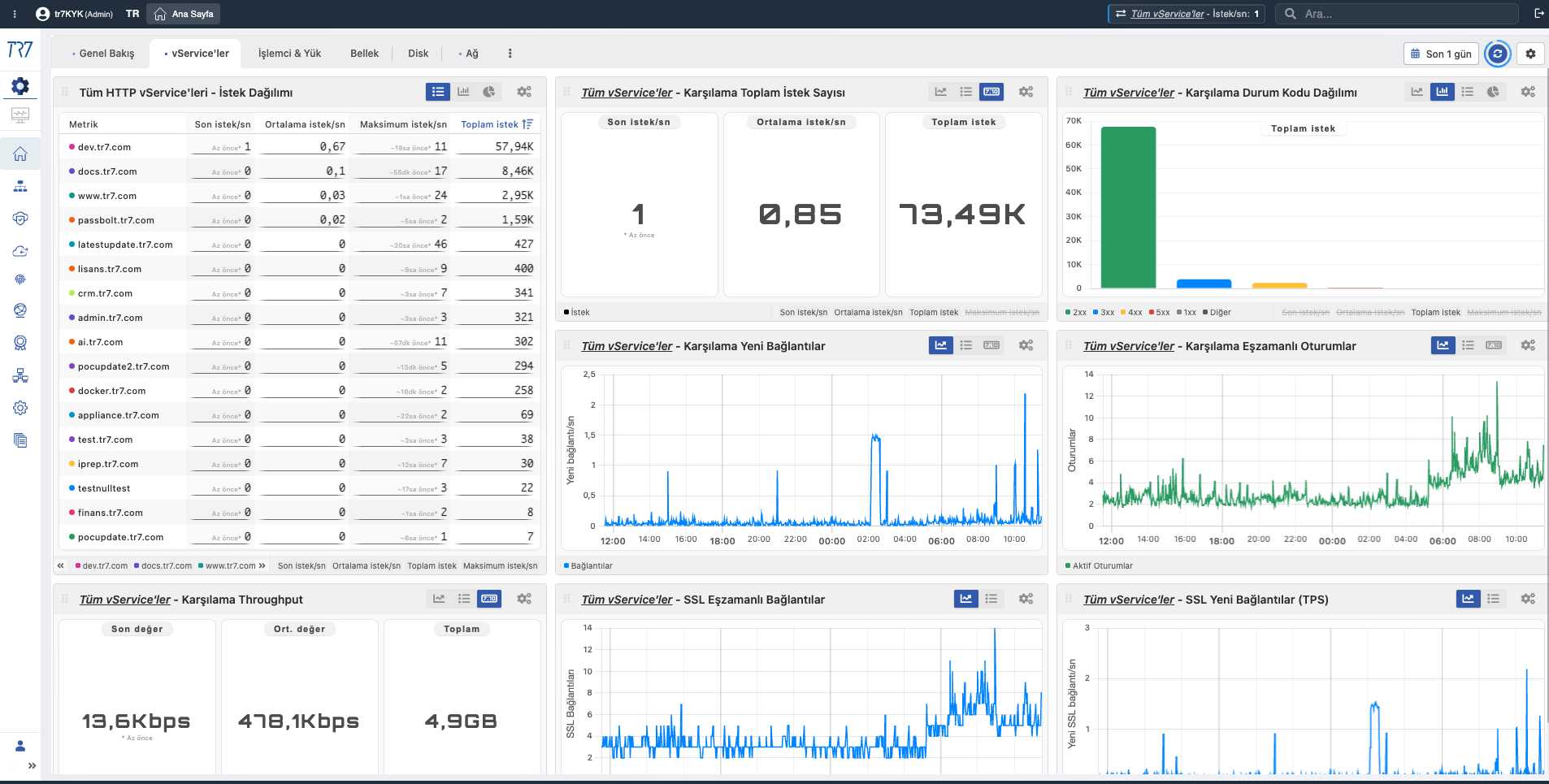
Karşılama Toplam İstek Sayısı
Total Requests
Ne?Servise gelen toplam HTTP/HTTPS istek sayısının zaman içindeki değişimini gösterir.
Neden önemli?Trafik artışlarını, ani düşüşleri ve kapasite etkisini anlamak için temel referans noktasıdır. Bir olay öncesi ve sonrası karşılaştırma yapmanızı sağlar.
Karşılama Durum Kodu Dağılımı
Status Code Distribution
Ne?HTTP yanıt kodlarının (2xx başarılı, 3xx yönlendirme, 4xx istemci hatası, 5xx sunucu hatası) zaman içindeki dağılımını gösterir.
Neden önemli?Hata oranındaki artışları hızlıca fark etmenizi sağlar. 5xx artışı backend sorununa, 4xx artışı istemci tarafı veya konfigürasyon sorununa işaret edebilir.
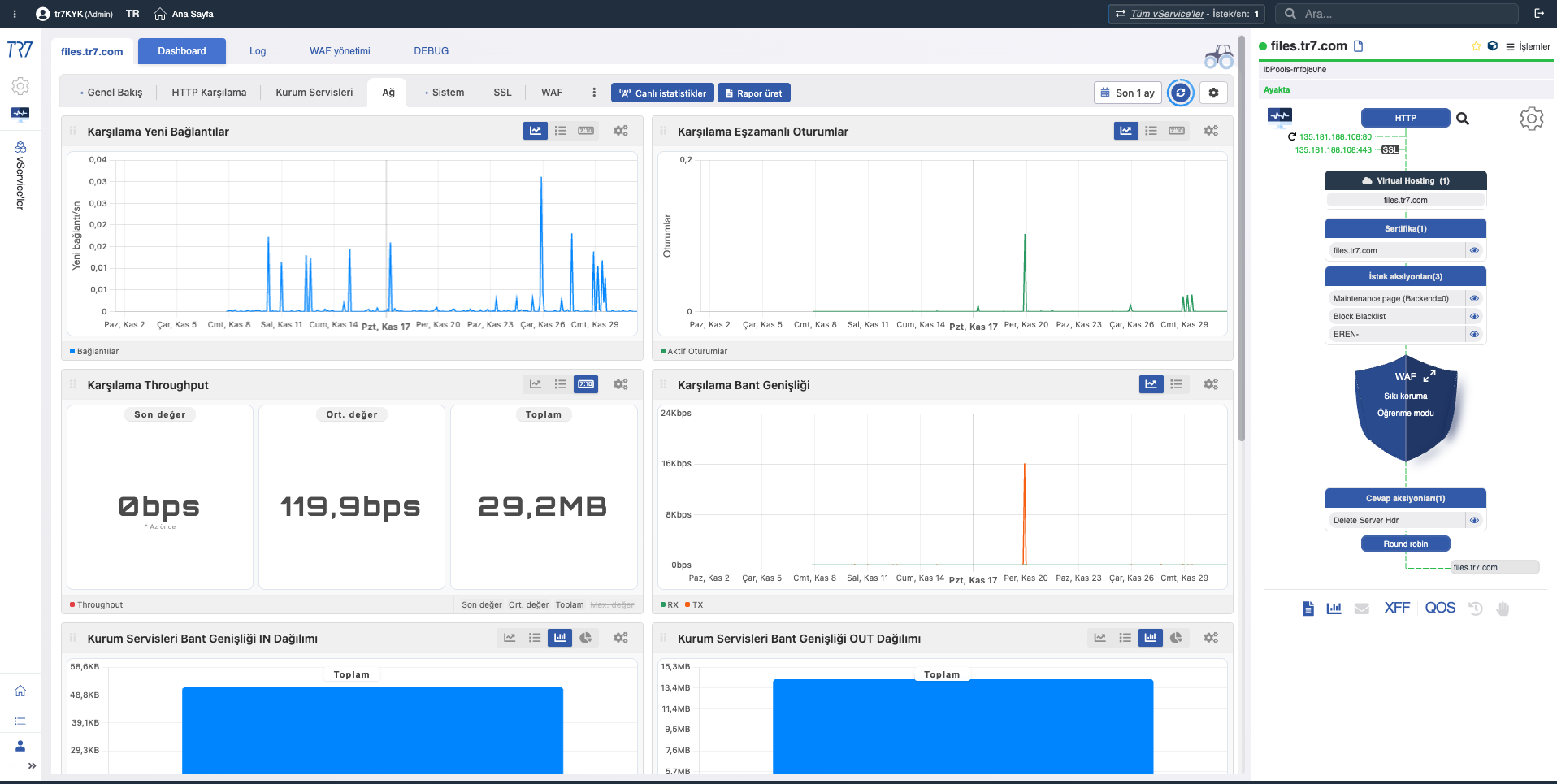
Karşılama Yeni Bağlantılar
New Connections
Ne?Saniyede açılan yeni TCP bağlantı sayısını gösterir.
Neden önemli?Ani bağlantı artışları DDoS saldırısına, bot aktivitesine veya istemci tarafı yeniden bağlanma sorunlarına işaret edebilir.
Karşılama Eşzamanlı Oturumlar
Concurrent Sessions
Ne?Aynı anda aktif olan oturum sayısını gösterir.
Neden önemli?Kapasite limitine ne kadar yaklaştığınızı anlamanızı sağlar. Oturum sayısı limitine yaklaşmak performans düşüşüne yol açabilir.
Karşılama Throughput
Throughput
Ne?Servis üzerinden geçen toplam veri hacmini (bit/saniye veya byte/saniye) gösterir.
Neden önemli?Bant genişliği kullanımını ve trafik trendlerini anlamak için kullanılır. Throughput düşüşü ağ veya backend sorunlarına işaret edebilir.
SSL Eşzamanlı Bağlantılar
SSL Concurrency
Ne?Aynı anda aktif olan şifreli TLS bağlantı sayısını gösterir.
Neden önemli?SSL/TLS işlemleri CPU yoğun olduğundan, bu metrik kapasite planlaması ve performans analizi için kritiktir.
SSL Yeni Bağlantılar (TPS)
TLS Handshake TPS
Ne?Saniyede gerçekleştirilen TLS handshake sayısını gösterir.
Neden önemli?Handshake oranındaki ani artış, session reuse'un çalışmadığına veya istemci tarafı sorunlara işaret edebilir. Yüksek handshake oranı CPU yükünü artırır.
SSL Oturum Yeniden Kullanımı
SSL Session Reuse
Ne?TLS oturumlarının yeniden kullanım oranını ve istatistiklerini gösterir.
Neden önemli?Düşük session reuse oranı gereksiz CPU kullanımına ve yüksek latency'ye neden olur. Bu metrik TLS performans optimizasyonu için yol göstericidir.
Sıkıştırma
Compression
Ne?HTTP yanıtlarının sıkıştırma oranını ve sıkıştırılan veri miktarını gösterir.
Neden önemli?Sıkıştırma bant genişliğinden tasarruf sağlarken CPU kullanır. Bu dengeyi anlamak performans optimizasyonu için önemlidir.
WAF Engellenen İstekler
WAF Blocked Requests
Ne?Web Application Firewall tarafından engellenen istek sayısının zaman içindeki değişimini gösterir.
Neden önemli?Engelleme sayısındaki ani artış bir saldırı dalgasına veya false positive üreten yeni bir kurala işaret edebilir. Her iki durumda da inceleme gerektirir.
WAF Tespit Edilen Saldırı İstekleri
WAF Detected Attacks
Ne?WAF tarafından tespit edilen saldırı girişimlerinin sayısını ve türlerini gösterir.
Neden önemli?Tehdit seviyesini ve saldırı trendlerini izlemenizi sağlar. Hangi saldırı türlerinin ne sıklıkla denendiğini anlamak güvenlik stratejisi için değerlidir.
WAF İnceleme Dağılımı
WAF Inspection Distribution
Ne?WAF kurallarının ve kategorilerinin ne oranda tetiklendiğini gösterir.
Neden önemli?Hangi kural setlerinin aktif olduğunu ve hangilerinin en çok çalıştığını gösterir. Kural tuning ve optimizasyon kararları için temel veridir.
Karşılama Bant Genişliği
Bandwidth
Ne?Servisin kullandığı gelen ve giden bant genişliğini gösterir.
Neden önemli?Link doygunluğunu ve throughput değişimlerini izlemek için kullanılır. Bant genişliği limitlerine yaklaşmak performans sorunlarına yol açabilir.
Karşılama Önbellek
Cache
Ne?Servisin önbellek davranışını, cache'e yazılan ve okunan veri miktarını gösterir.
Neden önemli?Önbellek kullanımı backend yükünü azaltır ve yanıt sürelerini iyileştirir. Cache davranışındaki değişiklikler performansı doğrudan etkiler.
Karşılama Önbellek Hit Oranı
Cache Hit Ratio
Ne?İsteklerin yüzde kaçının önbellekten karşılandığını gösterir.
Neden önemli?Yüksek hit oranı backend yükünü azaltır ve yanıt sürelerini kısaltır. Hit oranındaki düşüş cache konfigürasyonunu veya içerik değişikliklerini incelemeyi gerektirir.
vService İşlemci Kullanımı
vService CPU Usage
Ne?Bu servise atfedilen CPU kullanım yüzdesini gösterir.
Neden önemli?Tek bir servisin ne kadar CPU tükettiğini görmenizi sağlar. Bir servisin aşırı CPU kullanması diğer servisleri etkileyebilir.
vService Bellek Kullanımı
vService Memory Usage
Ne?Bu servise atfedilen bellek kullanımını gösterir.
Neden önemli?Servis bazlı bellek tüketimini izlemek memory leak veya aşırı kaynak kullanımı sorunlarını tespit etmeye yardımcı olur.
vService Bellek Kullanım %
vService Memory %
Ne?Servisin bellek kullanımını yüzde olarak gösterir.
Neden önemli?Trend analizi ve kapasite planlaması için kullanılır. Bellek kullanımının sürekli artması bir sorunun habercisi olabilir.
vService Çalışma Süresi
vService Uptime
Ne?Servisin son yeniden başlatılmasından bu yana geçen süreyi gösterir.
Neden önemli?Servis restart'larını olay zaman çizelgesiyle ilişkilendirmenizi sağlar. Beklenmedik restart'lar inceleme gerektirir.
Kurum Servisleri İstek Dağılımı
Backend Request Distribution
Ne?Gelen isteklerin backend sunucular arasında nasıl dağıtıldığını gösterir.
Neden önemli?Dengesiz yük dağılımını tespit etmenizi sağlar. Bir backend'in orantısız fazla veya az istek alması konfigürasyon veya sağlık sorununa işaret edebilir.
Kurum Servisleri Yanıt Süresi Dağılımı
Backend Response Time Distribution
Ne?Her backend sunucunun ortalama yanıt süresini karşılaştırmalı olarak gösterir.
Neden önemli?Yavaş backend'i hızlıca tespit etmenizi sağlar. Bir backend'in yanıt süresi diğerlerinden belirgin şekilde yüksekse, o sunucuda sorun olabilir.
Kurum Servisleri Sağlığı
Backend Health
Ne?Her backend sunucunun health-check sonuçlarını ve sağlık durumunu gösterir.
Neden önemli?Hangi backend'lerin healthy, hangi backend'lerin down veya degraded durumda olduğunu anında görmenizi sağlar.
Kurum Servisleri Sağlık Kontrolü Zamanlaması
Health Check Timing
Ne?Health-check'lerin ne sıklıkla yapıldığını ve yanıt sürelerini gösterir.
Neden önemli?Health-check timing sorunlarını tespit etmenizi sağlar. Yavaş health-check yanıtları sorunlu bir backend'in geç tespit edilmesine neden olabilir.
Kurum Servisleri Bağlantı Süresi Dağılımı
Connection Time Distribution
Ne?Backend'lere bağlantı kurma süresinin dağılımını gösterir.
Neden önemli?Ağ gecikmelerini ve TCP bağlantı sorunlarını tespit etmenize yardımcı olur. Yüksek bağlantı süresi ağ veya backend tarafında sorun olduğuna işaret eder.
Kurum Servisleri Bağlantı Dağılımı
Connection Distribution
Ne?Aktif bağlantıların backend'ler arasındaki dağılımını gösterir.
Neden önemli?Sticky session davranışını ve yük dengesini izlemenizi sağlar. Bir backend'de orantısız bağlantı birikimi performans sorunlarına yol açabilir.
Kurum Servisleri Bant Genişliği IN Dağılımı
Bandwidth IN Distribution
Ne?Backend'lere giden trafiğin bant genişliği dağılımını gösterir.
Neden önemli?Hangi backend'lerin ne kadar trafik aldığını görmenizi sağlar. Aşırı trafik alan bir backend darboğaz oluşturabilir.
Kurum Servisleri Bant Genişliği OUT Dağılımı
Bandwidth OUT Distribution
Ne?Backend'lerden gelen yanıt trafiğinin bant genişliği dağılımını gösterir.
Neden önemli?Backend yanıt boyutlarını ve trafik paternlerini anlamanızı sağlar. Büyük yanıtlar üreten backend'ler bant genişliği planlamasını etkiler.
Kurum Servisleri Oturum Dağılımı
Session Distribution
Ne?Aktif oturumların backend'ler arasındaki dağılımını gösterir.
Neden önemli?Session persistence davranışını ve backend başına oturum yoğunluğunu izlemenizi sağlar.
Kurum Servisleri Kuyruk Dağılımı
Queue Distribution
Ne?Backend'lere yönlendirilmeyi bekleyen isteklerin kuyruk durumunu gösterir.
Neden önemli?Kuyruk birikimi backend kapasitesinin yetersiz kaldığının erken sinyalidir. Kuyruklar dolmaya başladığında yanıt süreleri uzar.
Ağ Bant Genişliği - WAN
WAN Bandwidth
Ne?WAN arayüzünden geçen toplam trafik hacmini gösterir.
Neden önemli?Link kapasitesine ne kadar yaklaştığınızı görmenizi sağlar. Link doygunluğu paket kaybına ve latency artışına neden olur.
Ağ Paketleri - WAN
WAN Packets
Ne?Saniyede işlenen paket sayısını (PPS) gösterir.
Neden önemli?PPS anomalileri DDoS saldırılarına veya ağ sorunlarına işaret edebilir. Yüksek PPS düşük bant genişliğiyle birlikte small-packet flood'a işaret eder.
Ağ Durumu - WAN
WAN Status
Ne?Ağ arayüzünün operasyonel durumunu (up/down) ve link kalitesini gösterir.
Neden önemli?Link durumu değişikliklerini anında tespit etmenizi sağlar. Aralıklı link down'lar bağlantı sorunlarına neden olur.
Ağ Arayüzü Hataları
Interface Errors
Ne?Arayüzde meydana gelen hataları (CRC, collision, drop vb.) gösterir.
Neden önemli?Interface hataları fiziksel kablo sorunlarına, MTU uyumsuzluklarına veya donanım arızalarına işaret edebilir.
Arayüz Birinimleri (WAN)
Interface Units
Ne?Alt arayüzlerin ve VLAN'ların durumunu gösterir.
Neden önemli?Karmaşık ağ topolojilerinde her alt birimin durumunu ayrı ayrı izlemenizi sağlar.
Cihaz İşlemci Kullanımı
Device CPUSystem CPU
Ne?Cihazın toplam CPU kullanım yüzdesini gösterir.
Neden önemli?Yüksek CPU kullanımı tüm servislerin performansını etkiler. CPU'nun sürekli yüksek olması kapasite artırımı veya optimizasyon gerektirir.
Cihaz İşlemci Sıcaklığı
CPU Temperature
Ne?CPU'nun çalışma sıcaklığını gösterir.
Neden önemli?Yüksek sıcaklık termal throttling'e ve performans düşüşüne neden olabilir. Aşırı sıcaklık donanım arızası riskini artırır.
Sistem Çalışma Süresi
System Uptime
Ne?Cihazın son başlatılmasından bu yana geçen süreyi gösterir.
Neden önemli?Beklenmedik yeniden başlatmaları tespit etmenizi sağlar. Uptime sıfırlandıysa neden yeniden başlatıldığını araştırmak gerekir.
Sistem Yükü
System LoadLoad Average
Ne?1, 5 ve 15 dakikalık sistem yük ortalamalarını gösterir.
Neden önemli?Sistemin ne kadar meşgul olduğunu anlamanızı sağlar. Load average CPU sayısından sürekli yüksekse sistem aşırı yük altındadır.
Toplam Bellek Kullanımı
Total Memory Usage
Ne?Sistemin kullandığı toplam bellek miktarını gösterir.
Neden önemli?Bellek tüketiminin zaman içindeki değişimini izlemenizi sağlar. Sürekli artan bellek kullanımı memory leak'e işaret edebilir.
Kullanılabilir Bellek
Available Memory
Ne?Yeni işlemler için kullanılabilir bellek miktarını gösterir.
Neden önemli?Düşük kullanılabilir bellek yeni bağlantıların ve işlemlerin başlatılamamasına neden olabilir.
Bellek Kullanım Oranı
Memory Usage %
Ne?Toplam belleğin yüzde kaçının kullanıldığını gösterir.
Neden önemli?Kapasite planlaması ve eşik tabanlı uyarılar için kullanılır. %90 üzeri kullanım kritik seviyedir.
Swap Kullanımı
Swap Usage
Ne?Disk üzerindeki swap alanının kullanımını gösterir.
Neden önemli?Swap kullanımı fiziksel belleğin yetersiz kaldığının göstergesidir. Aktif swap kullanımı ciddi performans düşüşüne neden olur.
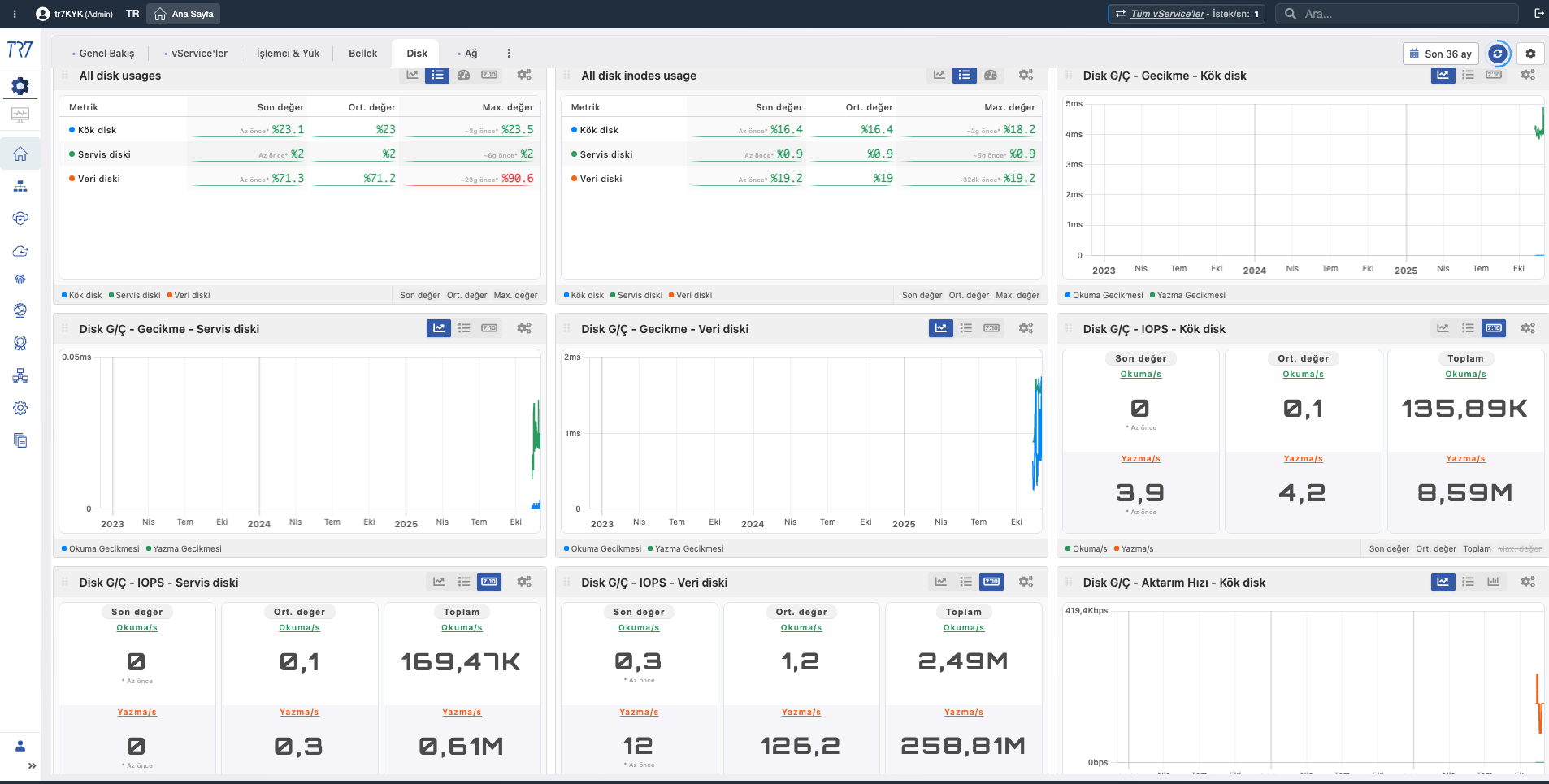
Disk Kullanımı
Disk Usage
Ne?Kullanılan disk alanı miktarını gösterir.
Neden önemli?Disk doluluk oranını izlemenizi sağlar. Disk dolarsa log yazımı durabilir ve sistem kararsız hale gelebilir.
Disk Kapasitesi
Disk Capacity
Ne?Toplam disk kapasitesini gösterir.
Neden önemli?Kapasite planlaması ve büyüme trendi analizi için referans noktasıdır.
Disk Kullanım Oranı
Disk Usage %
Ne?Disk kapasitesinin yüzde kaçının kullanıldığını gösterir.
Neden önemli?%90 üzeri doluluk uyarı, %95 üzeri kritik seviyedir. Disk doluluğu log rotasyonu ve arşivleme planlaması gerektirir.
Disk Inode Kullanımı
Inode Usage
Ne?Dosya sistemi inode kullanımını gösterir.
Neden önemli?Disk alanı boş olsa bile inode'lar tükenirse yeni dosya oluşturulamaz. Çok sayıda küçük dosya içeren sistemlerde kritiktir.
Disk I/O Okuma
Disk Read I/O
Ne?Saniyedeki disk okuma işlem sayısını ve hızını gösterir.
Neden önemli?Yüksek okuma I/O'su disk darboğazına işaret edebilir. SSD olmayan sistemlerde özellikle dikkat edilmelidir.
Disk I/O Yazma
Disk Write I/O
Ne?Saniyedeki disk yazma işlem sayısını ve hızını gösterir.
Neden önemli?Log ve audit yazımı sürekli disk I/O üretir. Yazma hızı düşerse log kaybı riski oluşabilir.
Disk I/O Latency
I/O Latency
Ne?Disk işlemlerinin ortalama tamamlanma süresini gösterir.
Neden önemli?Yüksek I/O latency'si disk performans bozulmasının erken sinyalidir. Latency artışı tüm sistem performansını etkiler.
TCP Bağlantı Sayısı
TCP Connections
Ne?Sistemdeki toplam TCP bağlantı sayısını gösterir.
Neden önemli?Bağlantı limitine yaklaşıp yaklaşmadığınızı görmenizi sağlar. Bağlantı limiti aşılırsa yeni bağlantılar reddedilir.
TCP Established
Established Connections
Ne?Aktif olarak veri transferi yapan bağlantı sayısını gösterir.
Neden önemli?Gerçek iş yükünün göstergesidir. Established bağlantı sayısı kapasiteyle doğrudan ilişkilidir.
TCP TIME_WAIT
TIME_WAIT
Ne?TIME_WAIT state'inde bekleyen bağlantı sayısını gösterir.
Neden önemli?Yüksek TIME_WAIT sayısı port tükenmesi riskine işaret eder. Kısa ömürlü bağlantılar ve yoğun trafik TIME_WAIT birikimine neden olur.
TCP CLOSE_WAIT
CLOSE_WAIT
Ne?CLOSE_WAIT state'inde bekleyen bağlantı sayısını gösterir.
Neden önemli?Yüksek CLOSE_WAIT sayısı uygulamanın bağlantıları düzgün kapatmadığına işaret eder. Bu genellikle uygulama tarafında bir bug'dır.
TCP Retransmit
Retransmissions
Ne?TCP paketlerinin yeniden iletim (retransmission) sayısını gösterir.
Neden önemli?Retransmission artışı ağ kalitesi sorunlarına, paket kaybına veya congestion'a işaret eder. Yüksek retransmission oranı latency artışına ve throughput düşüşüne neden olur.
vService Toplam İstek
Total vService Requests
Ne?Tüm vService'lerin toplam istek sayısını tek bir grafikte gösterir.
Neden önemli?Cihaz genelindeki toplam trafik hacmini ve trendini anlamanızı sağlar. Kapasite planlaması ve genel yük değerlendirmesi için temel referanstır.
vService Toplam Bağlantı
Total vService Connections
Ne?Tüm vService'lerin toplam aktif bağlantı sayısını gösterir.
Neden önemli?Cihaz genelindeki bağlantı baskısını ve connection table kullanımını izlemenizi sağlar. Connection table limitine yaklaşmak yeni bağlantıların reddedilmesine neden olabilir.
Entegrasyonlar: var, ama inceleme onlara bağlı kalmaz
TR7, kurumunuzun izleme ve log yönetim ekosistemiyle entegre olabilir. Kritik fark şudur: Olay incelemesi sadece harici pipeline’a bağlı kalmaz. Dış sistemler ek değer sağlar; cihaz üzerindeki kayıtlar ise temel referans olur.
Sıkça Sorulan Sorular
Amaç, investigation için gerekli verinin cihaz üzerinde her zaman hazır olmasıdır. Dışa export ve merkezi arşivleme yapılabilir. Ancak inceleme başarısı sadece export konfigürasyonuna bağlı kalmaz.
Amaç her an her şeye bakmak değildir. Kategoriler, arama ve filtreleme ile ihtiyaç anında doğru sinyale hızlı ulaşırsınız.
Web Console'un hedefi serbest erişim değil, kontrollü teşhistir. Doğru yetkilendirme ve runbook ile kullanıldığında inceleme süresini kısaltır.
Gerçek zamanlıdır. Servis durumları runtime'da izlenir ve değişiklikler anında renk değişimi ile yansır. Ayrıca geçmişe dönük metrik ve event kayıtları da tutulur.
Normal debug genellikle tüm trafiği yakalar ve sonra filtreleme gerektirir. Hedefli debug ise baştan belirli host, port, path veya header için kayıt alır. Bu sayede gürültü azalır, inceleme hızlanır ve üretim yükü daha az etkilenir.
TR7, Prometheus export ve SIEM log gönderimi destekler. Entegrasyonlar değerini korur. Fark şudur: investigation için gerekli veri sadece dış sisteme bağlı kalmaz, cihaz üzerinde de hazır durur.
Saklama süresi yapılandırılabilir. Önemli olan, kullanıcı hareketleri ve konfig değişikliklerinin metrikler ve event kayıtlarıyla aynı zaman çizgisinde tutulmasıdır.
Detay, karmaşıklık değil hazırlıktır. Küçük ekiplerde de olay anında doğru veriye hızlı ulaşmak zaman kazandırır. Kategorize yapı ve arama özellikleri, sadece ihtiyaç duyulan veriye odaklanmayı kolaylaştırır.
Sonuç
TR7'nin iddiası 'daha çok grafik' değil; ADC/WAF katmanını investigation-ready hale getirmektir. vService/backend/interface metrikleri, event/notification kayıtları, audit trail ve HTTP/WAF görünürlüğü tek zaman çizgisinde birleşir; geriye dönük forensics ve hedefli debug ile kök neden analizi hızlanır.
Export entegrasyonları değerlidir; ancak kritik anlarda 'gönderilmediği için yok' riskini sıfıra yaklaştırmak için kanıt zincirinin ürünün içinde, her zaman erişilebilir olması gerekir.
Bu ve benzeri özellikler — datasheet'lerde karşılığı olmayan, demo'larda anlaşılması zor olan, ancak pratikte operasyonel kaliteyi belirleyen detaylar — TR7'yi değerlendiren kurumların neredeyse tamamının geçiş kararı almasının temel nedenidir.