はじめに
本番環境が停止した時、重要な3つの質問があります:何が起きたのか?いつ起きたのか?なぜ起きたのか?
実際には、答えは分散していることが多く、メトリクスは一箇所、トラフィックログは別の場所、変更履歴はさらに別の場所にあります。
もう一つの現実があります:外部システムへのエクスポートは通常選択的です。インシデント時に必要なシグナルがエクスポート対象として選択されていなかった場合、それは存在しません。
TR7のアプローチは明確です:エクスポート統合は重要ですが、調査がそれだけに依存すべきではありません。そのため、TR7は重要なシグナルをアプライアンス上に保持し、単一のタイムライン上で整合させます。
エクスポートのみでは不十分な理由
SIEM、ログサーバー、Prometheus/Grafanaプラットフォームは企業の可視性にとって価値があります。しかし、調査の成功は、必要な時に適切なデータが利用可能であることに依存します。
選択的収集は避けられない
コストとノイズのため、すべてのメトリクス/ログがエクスポートされるわけではありません。インシデント発生時、重要なシグナルが欠落している可能性があります。
データが分散すると相関が困難に
メトリクス、イベント、監査、トラフィックログが異なる場所にある場合、単一のタイムラインを構築するのに時間がかかります。
パイプライン自体がリスク領域
エージェント、ネットワーク、クォータ/制限、インデックス作成の問題がデータ損失を引き起こす可能性があります—特にインシデント時に。
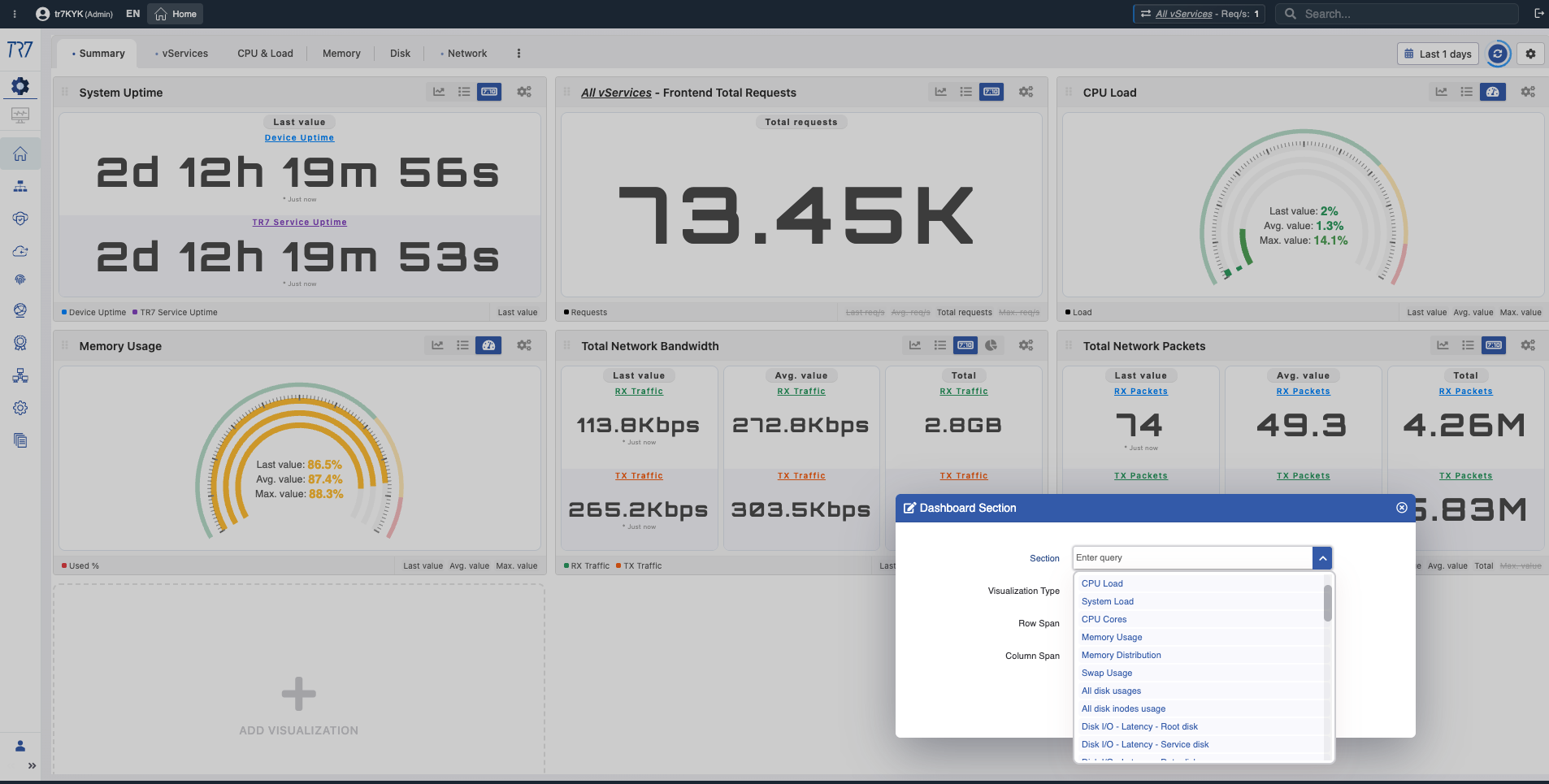
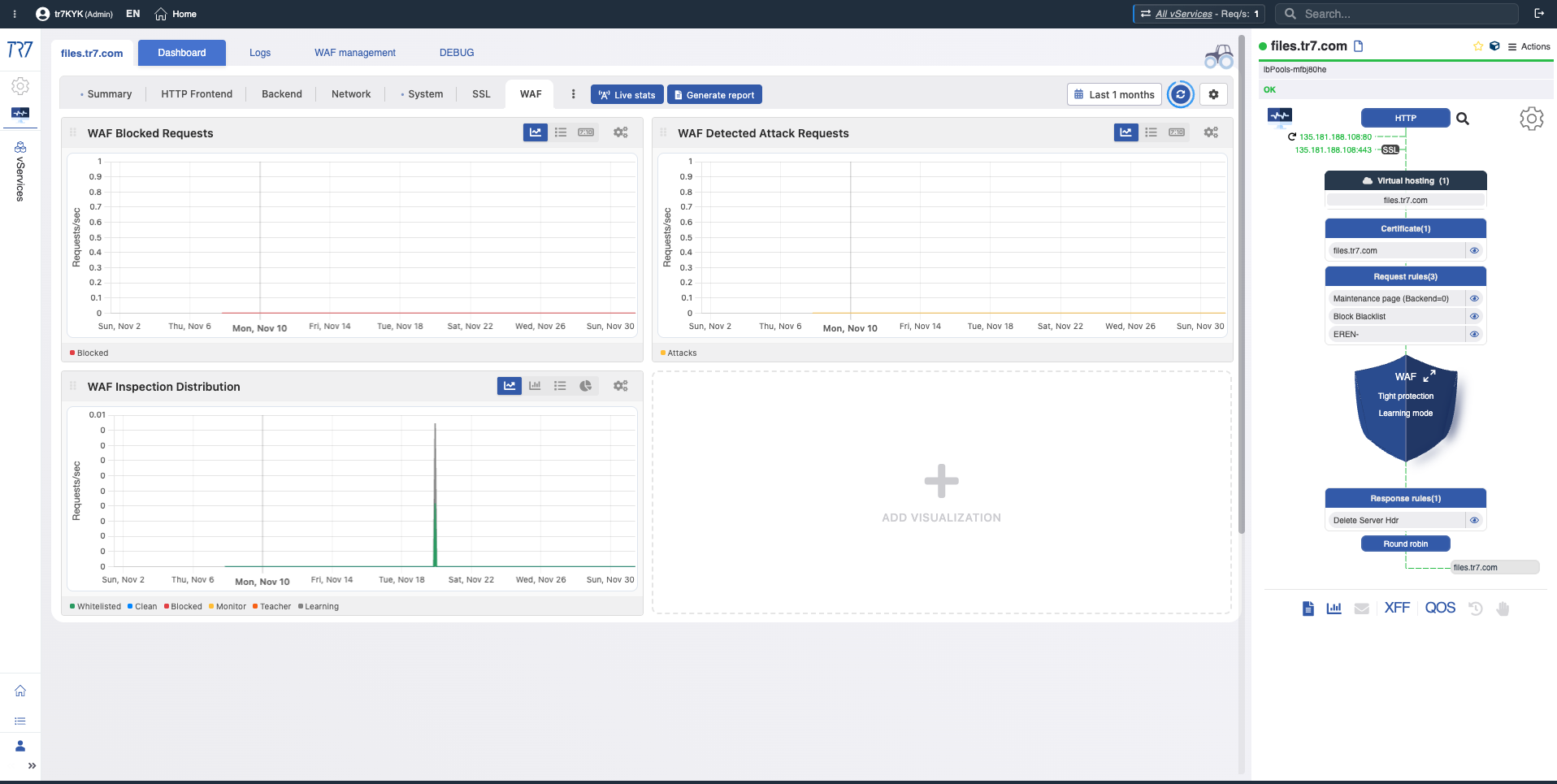
Dynamic Flow Panel:ランタイム可視性と迅速な開始点
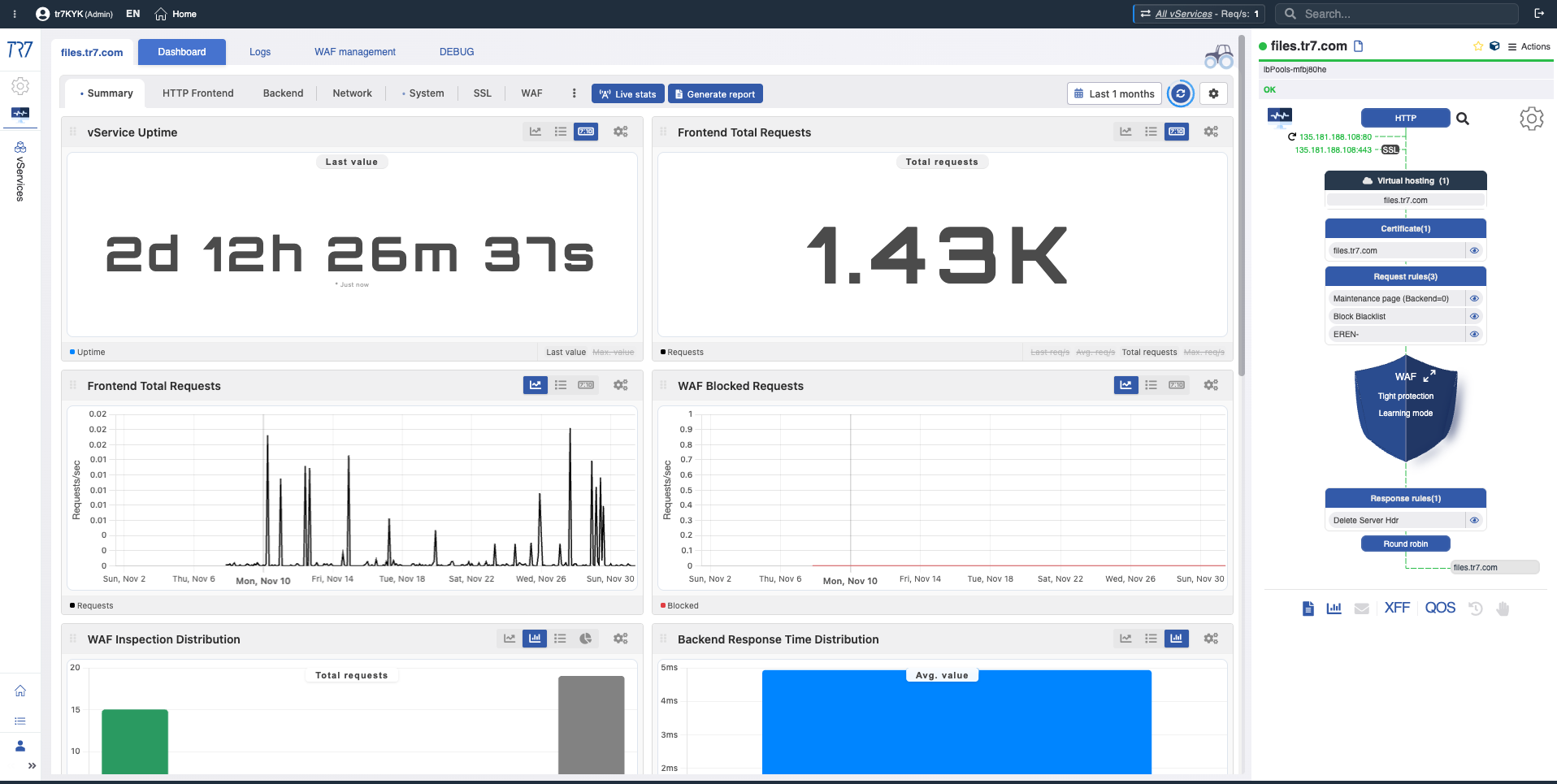
TR7のインターフェースでは、サービストポロジーをDynamic Flow Panelを通じてライブ(ランタイム)で監視できます。完全な制御 →
パネルはサービスのステータスを色で表示します。例えば、vServiceのIPを提供するインターフェースリンクがダウンすると、システムは警告を生成し、サービス名が緑から黄色に変わります。
これにより、オペレーターは何を調査すべきかをすぐに確認できます。トリアージが迅速に開始され、調査時間が短縮されます。
ステータスカラー
Flow Panelの色は、サービスのステータスを素早く読み取るのに役立ちます:
緑:正常
サービス接続とヘルスチェックが期待通りに動作しています。
- すべてのバックエンドが正常
- インターフェースリンクアップ
- ヘルスチェック合格
通常の監視
黄:注意
監視が必要な状態があります。
- インターフェースリンクダウン(サービスは動作可能)
- 1つのバックエンドヘルスチェック失敗
- リソースしきい値に接近
メトリクス + 通知 + 監査で簡単に確認
赤:クリティカル
サービスに影響する問題があります。
- バックエンドダウン
- vService到達不能
- 重大な設定エラー
迅速なトリアージ:メトリクス + イベント + 監査
調査シナリオの例
以下の例は、TR7における典型的な調査の進行を示します。
- 苦情:「アプリケーションが遅い」
- vServiceレスポンスタイムのトレンドを確認 → スパイクはあるか?
- バックエンドレスポンスタイムの分布を確認 → どのバックエンドが遅いか?
- ヘルスチェックと接続分布で検証
- 同じ時間枠の通知ログにリソースアラートはあるか?
- 監査証跡:最近の変更はあるか?
- 結果:LB層または特定のバックエンド—迅速に明確化
- 苦情:「フォーム送信が失敗する」
- WAFブロックメトリクスを確認 → スパイクはあるか?
- HTTP/WAFログからトリガーされたルールを特定
- リクエスト詳細から判断:誤検知か実際の攻撃か?
- 監査証跡:ルール/ポリシーの変更はあるか?
- 必要に応じてターゲットデバッグを使用し、関連トラフィックのみを検査
- 結果:ルールチューニングまたはセキュリティアクション—データで判断
デバイス概要:調査の開始点
インシデント調査は常にデバイス概要から始まります。CPU、メモリ、ディスク使用率、システム健全性—デバイスの全体的な状態を一目で評価します。時間範囲選択により遡及的forensicsが可能になります。
システムサマリー:アップタイム、総リクエスト数、CPU負荷、メモリ、帯域幅—インシデント時のデバイス状態を迅速に評価。
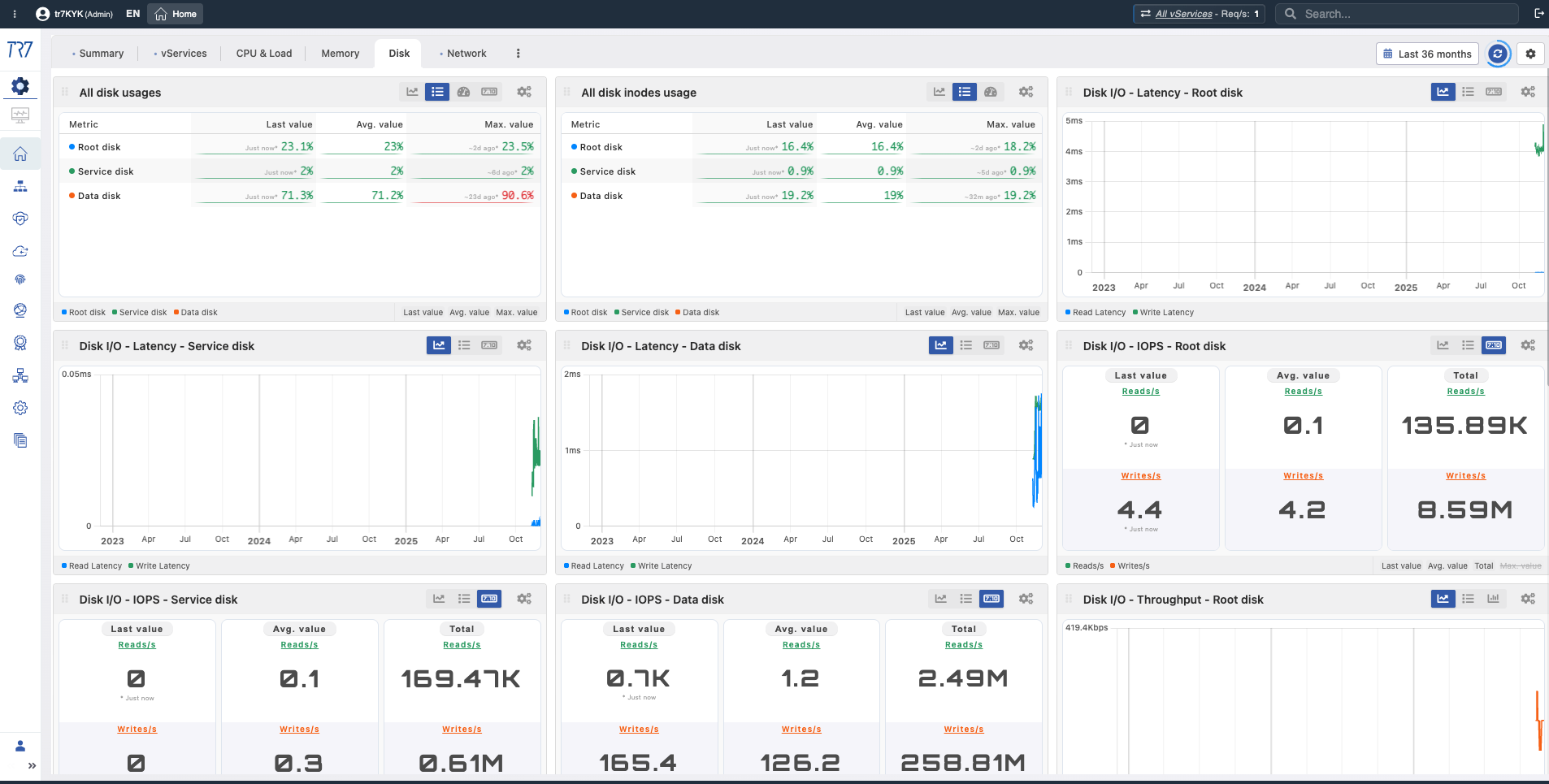
ディスク & I/O:使用率、inode、レイテンシ、IOPS—ログ書き込みやキャッシュパフォーマンスに影響は?
サービスとバックエンド:パフォーマンスと健全性メトリクス
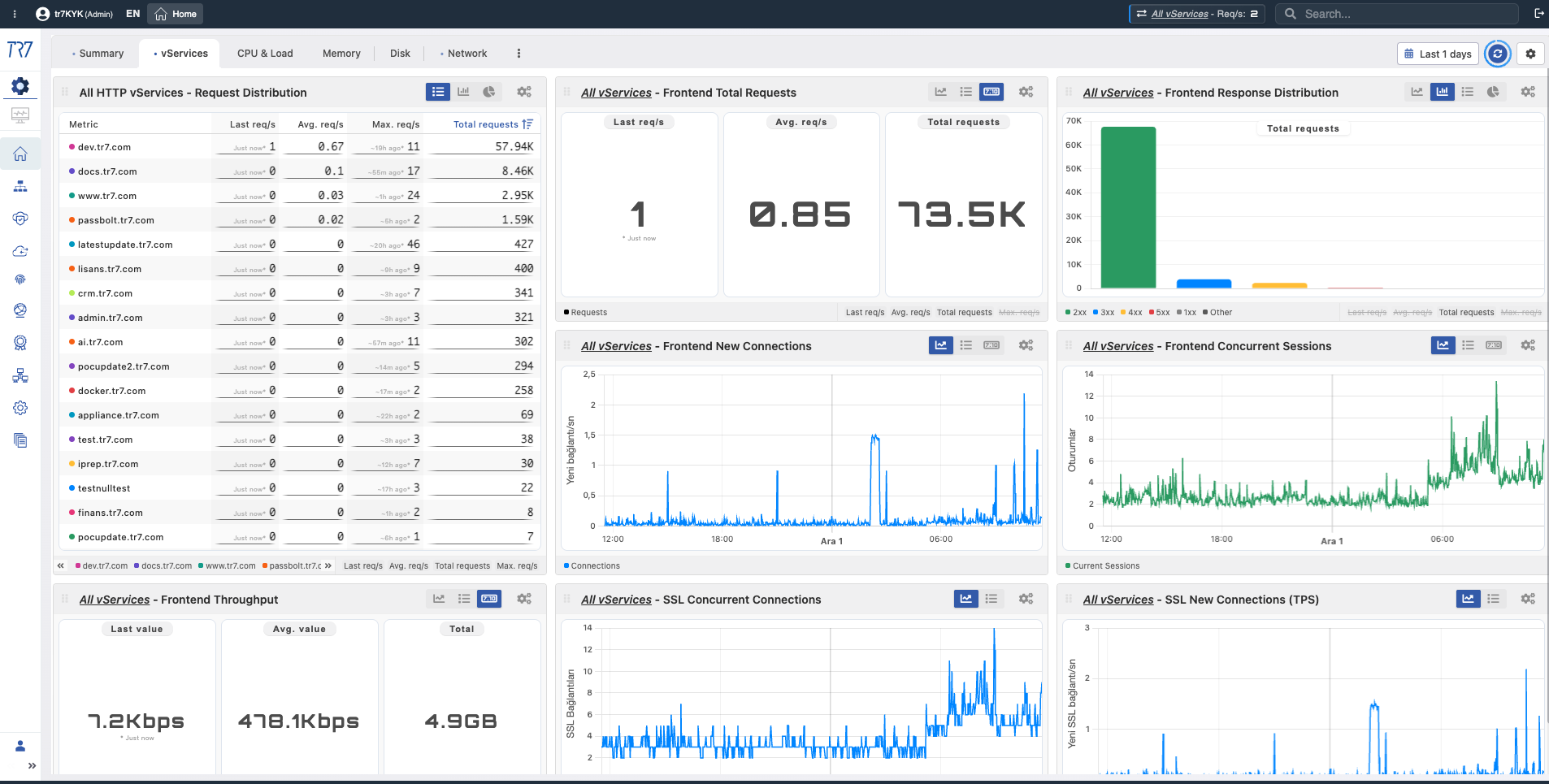
システム概要の後、サービス層にドリルダウンします。すべてのvServiceのリクエスト分布、レスポンスコード、バックエンド健全性、Dynamic Flow Panelによるサービストポロジー—すべて一目で。各vServiceには独自のダッシュボードがあります。
vService概要:すべてのサービスのリクエスト分布とレスポンスコード(2xx/3xx/4xx/5xx)—どのサービスに異常があるか?
vServiceサマリー:アップタイム、フロントエンドリクエスト、WAFブロック数、Dynamic Flow Panel—サービスの現在の状態。
カスタマイズ可能メトリクス:SSL再利用、圧縮、キャッシュヒット率—調査に必要なメトリクスを追加。
バックエンド分布:どのバックエンドが遅いか?どれが多くのリクエストを受けるか?レスポンスタイムと接続メトリクス。
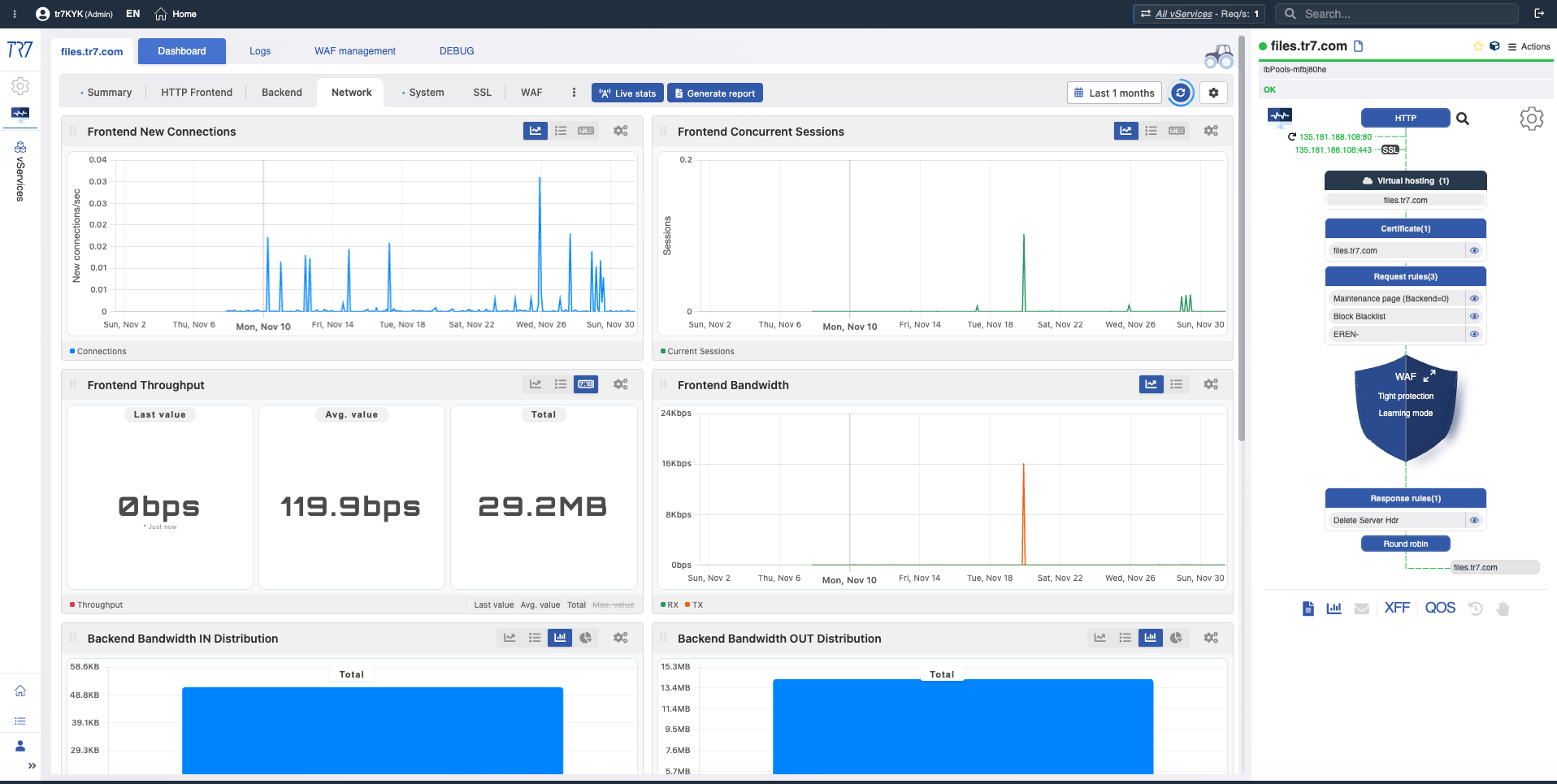
ネットワークとインターフェース:接続状態とトラフィックフロー
問題はサービスにあるのかネットワークにあるのか?トポロジー、帯域幅、TCP状態分布、インターフェースメトリクスがこの質問に答えます。リンク状態の変化とパケットエラーは、ネットワーク層の問題を迅速に明らかにします。
ネットワークトポロジー:帯域幅、TCP状態分布—サービス対ネットワーク問題の切り分けの最初の手がかり。
インターフェースメトリクス:RX/TX帯域幅、パケット数、エラー—リンクパフォーマンスと健全性。
vServiceネットワーク:サービスごとのスループットと接続状態—トラフィックパターンは正常か?
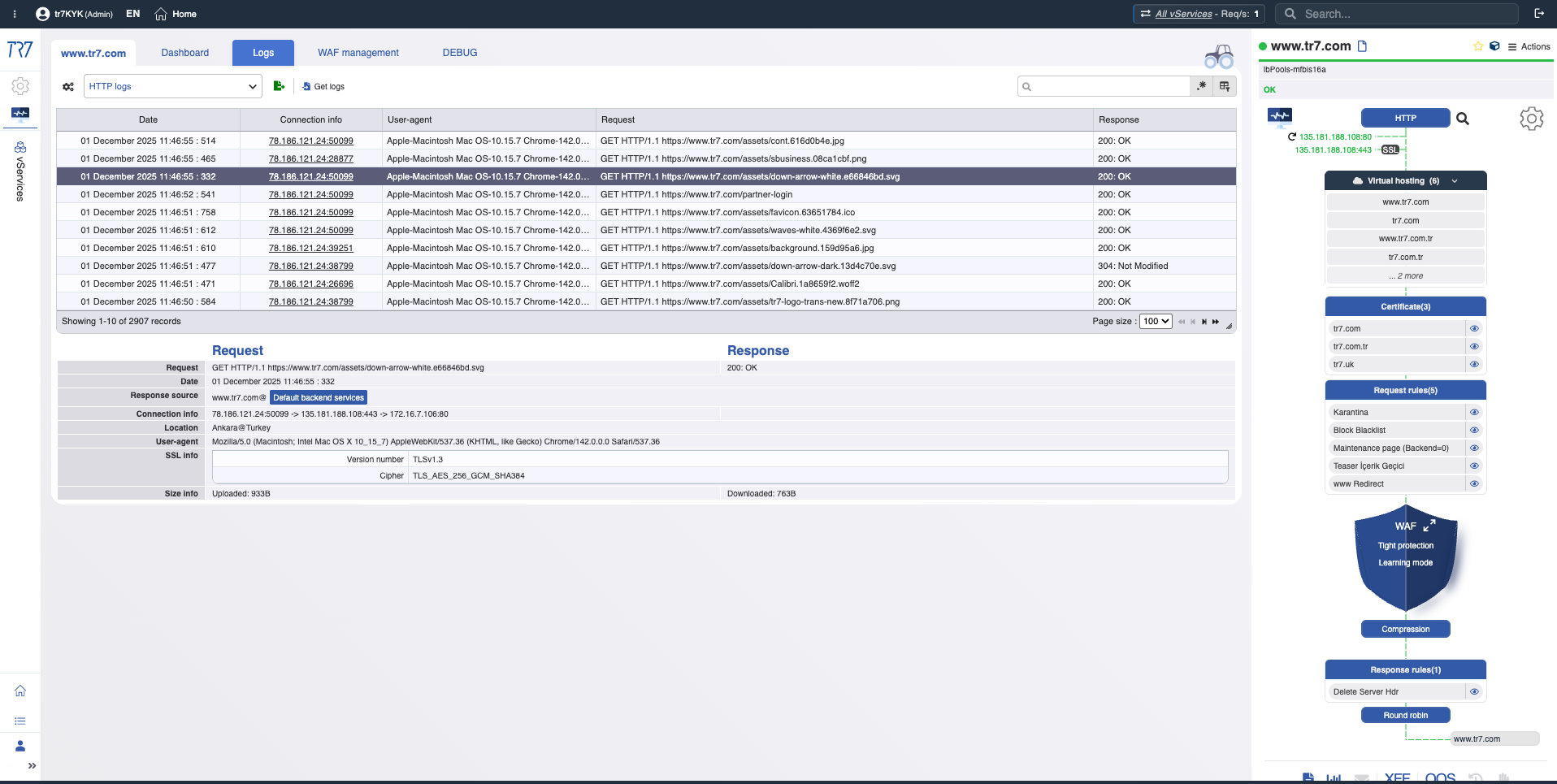
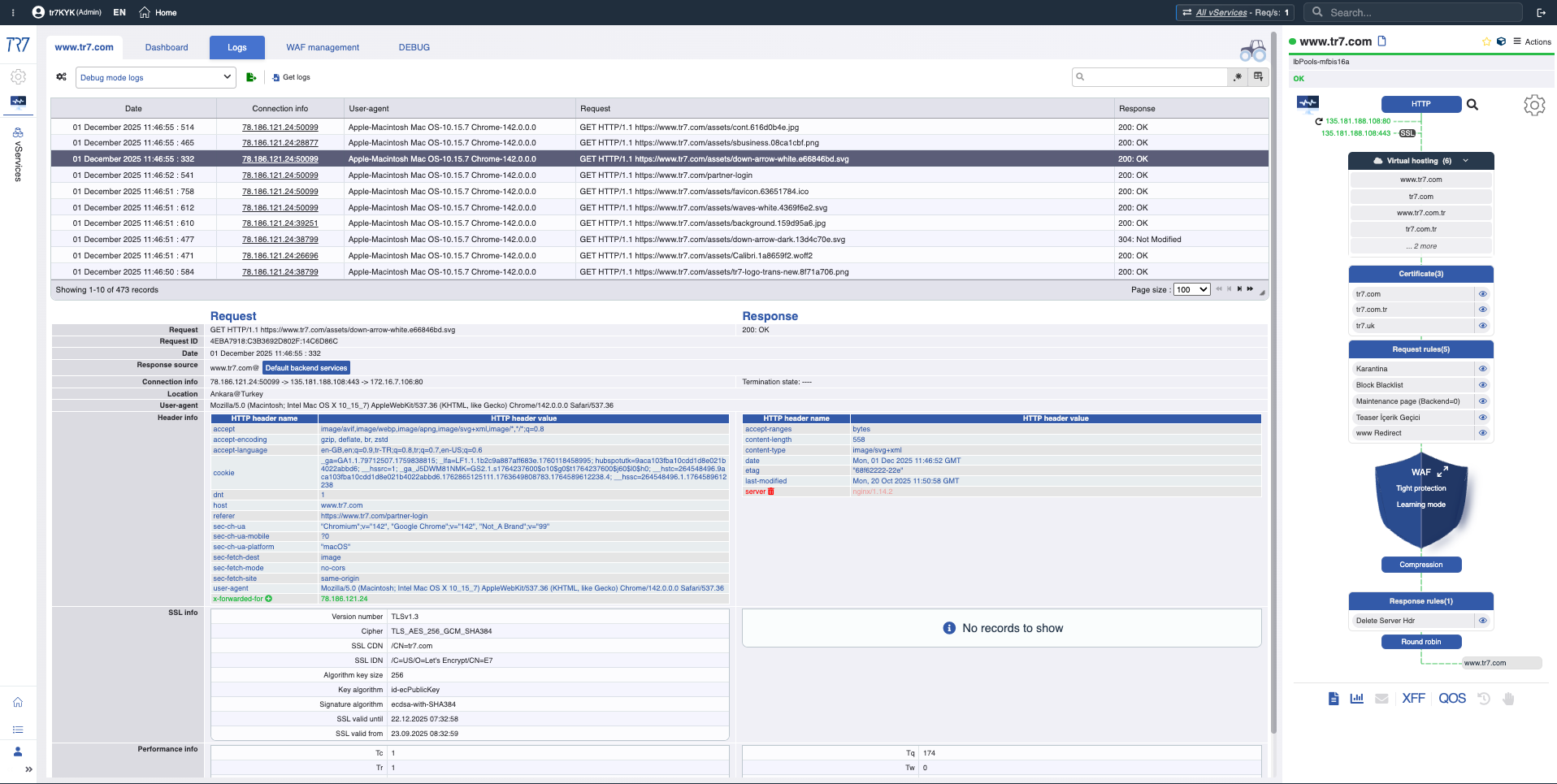
HTTPとWAFログ:リクエストレベルの調査
HTTPトラフィックとWAFイベントは、デバッグを有効にしなくても可視化されます。必要に応じて、ターゲットデバッグは特定のhost/path/headerのみの完全な詳細をキャプチャします。本番環境に影響を与えることなく、リクエストレベルのforensicsが可能です。
HTTPログ:送信元IP、宛先、レスポンスコード、サイズ、期間—デバッグオフでも基本的な可視性。
ターゲットデバッグ:関連トラフィックのみの完全なヘッダーとクッキー—本番環境に影響を与えずに詳細を取得。
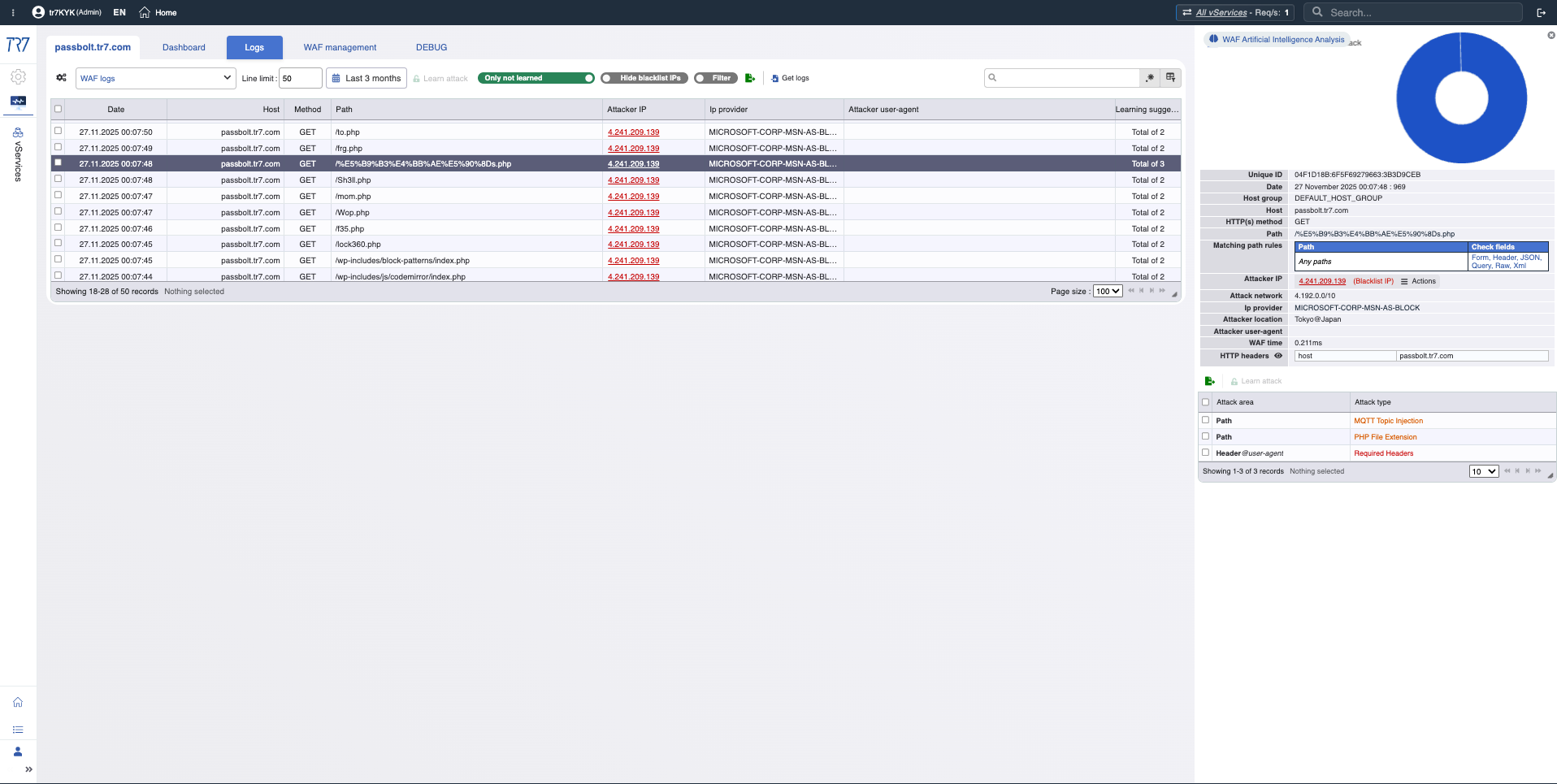
WAFログ:トリガーされたルール、リクエスト詳細、AI搭載分析—誤検知評価のためのデータ。
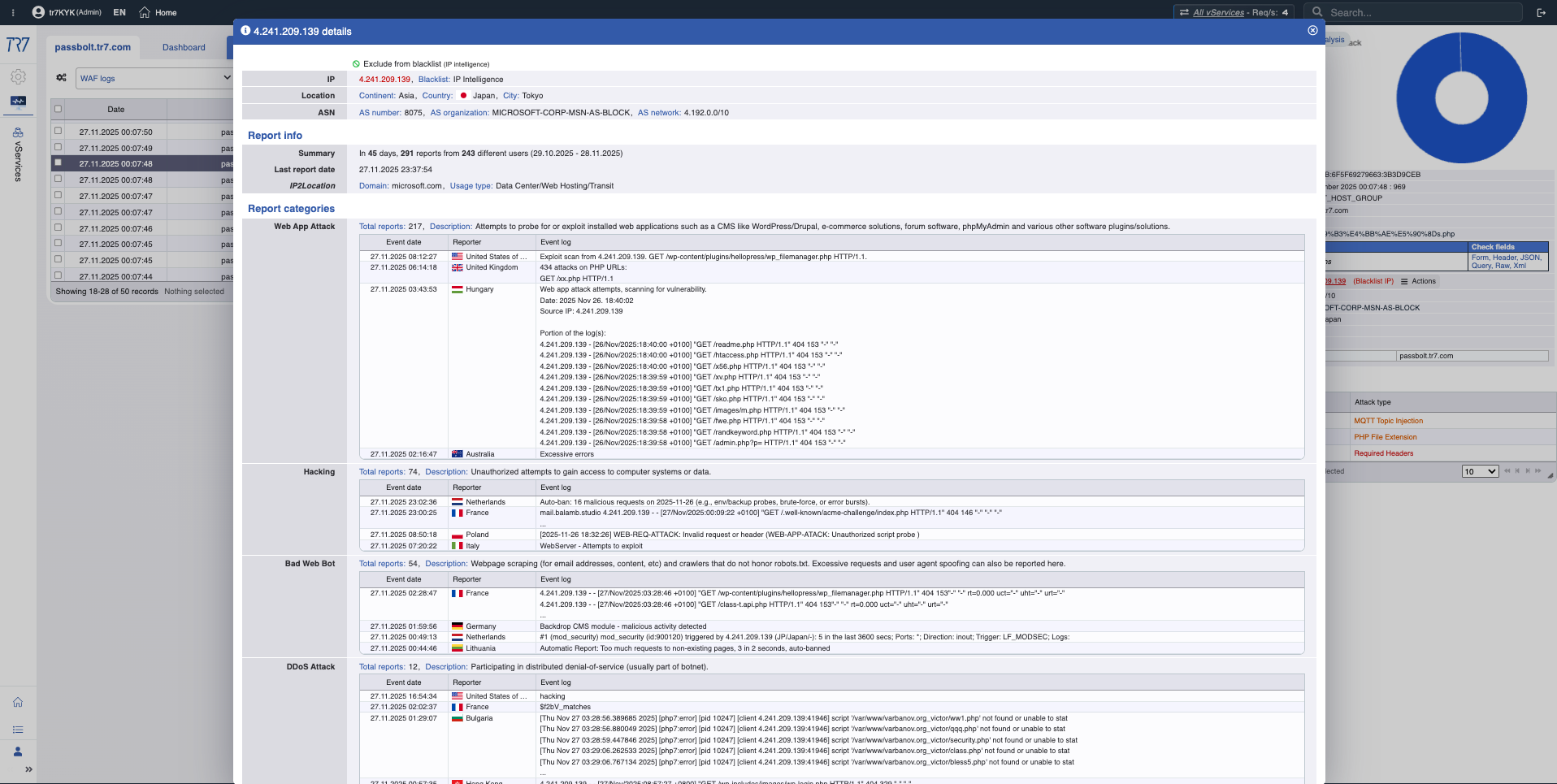
IPインテリジェンスとWAF:脅威プロファイル
IPレピュテーションスコアとWAFメトリクスは、攻撃者のプロファイルを迅速に明らかにします。「誤検知か実際の攻撃か?」の最初の答えはここにあります。脅威カテゴリー(ボットネット、プロキシ、VPN、Tor)は送信元IPの性質を示します。
IPインテリジェンス:レピュテーションスコア、脅威カテゴリー—攻撃者のプロファイルが迅速に明確になります。
WAFメトリクス:ブロック傾向、検査分布—セキュリティイベントの概要。
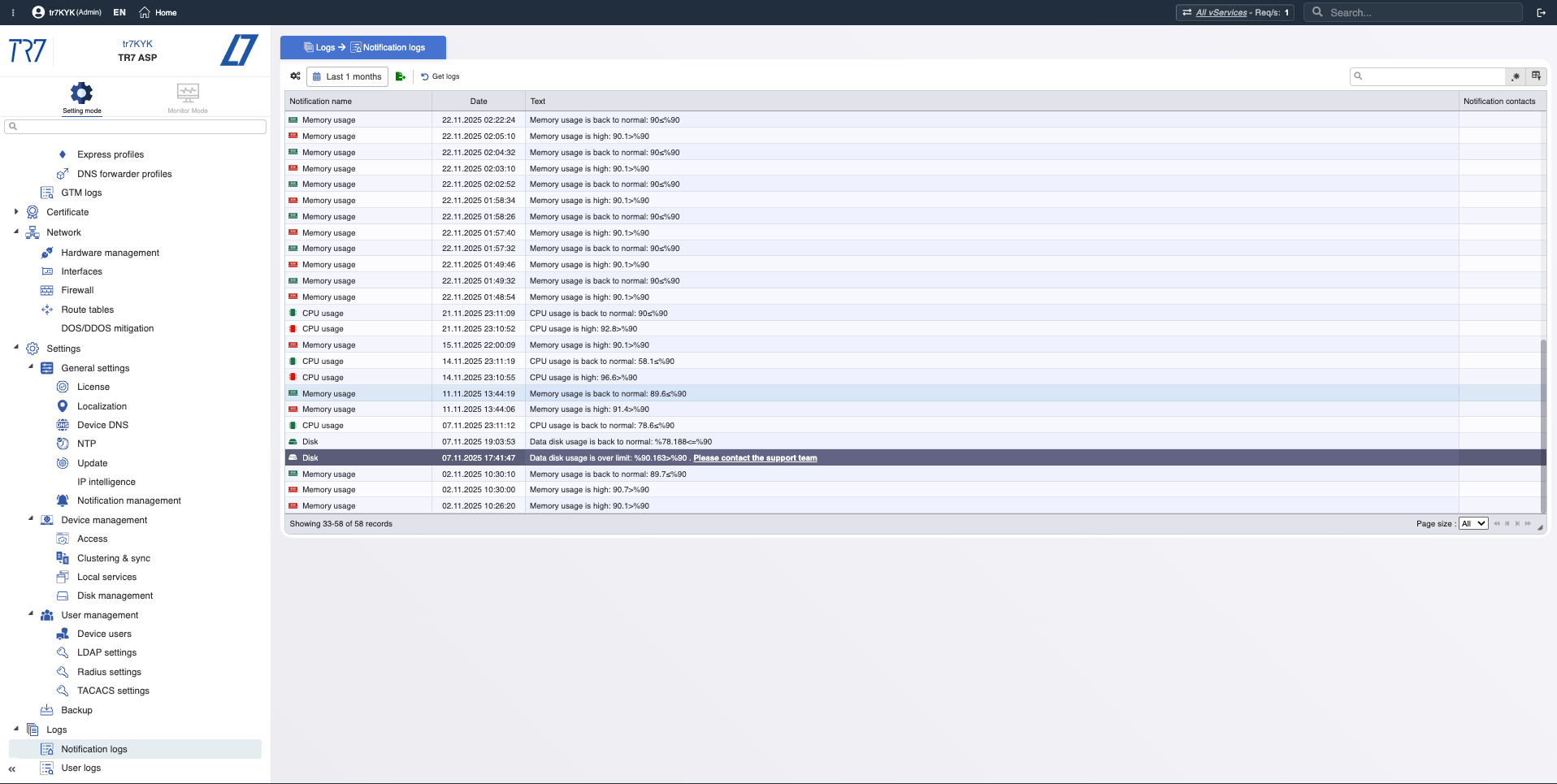
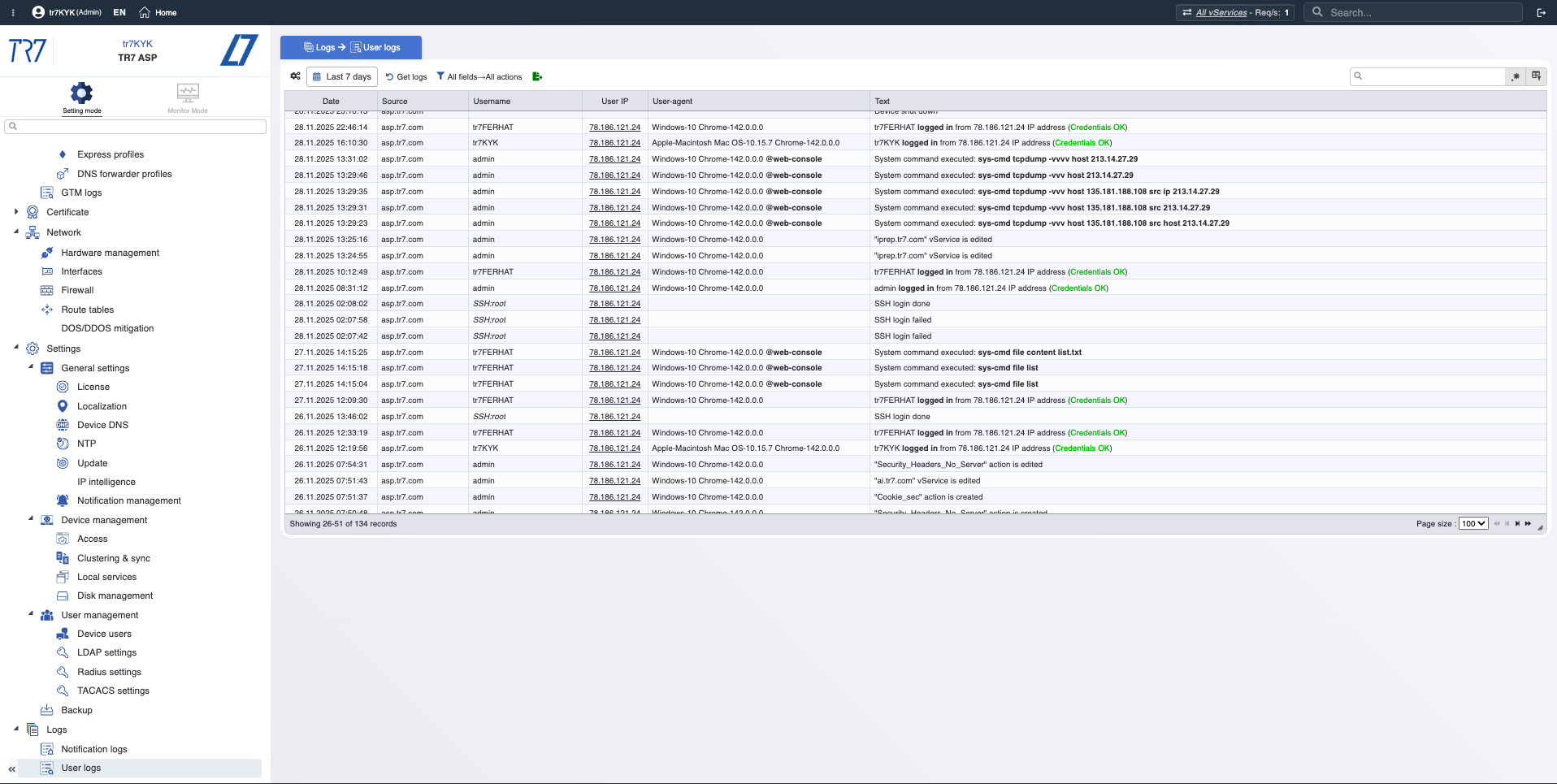
イベントタイムライン:通知と監査証跡
メトリクスだけでは不十分です。どのアラートが発火したか?誰が何をいつ変更したか?インシデント調査では、「どの変更が何に影響したか?」が重要です。TR7は通知/イベントレコードと監査証跡を一緒に保持し、この相関を高速化します。
通知タイプ:CPU、メモリ、ディスク、帯域幅、サービス状態—どのイベントが監視されているか?
通知履歴:トリガーされたアラートの時系列—インシデント時にどの警告が来たか?
監査証跡:誰が何をいつ変更したか?インシデントと変更を迅速に相関させるための証拠。
Webコンソール:仮説を検証
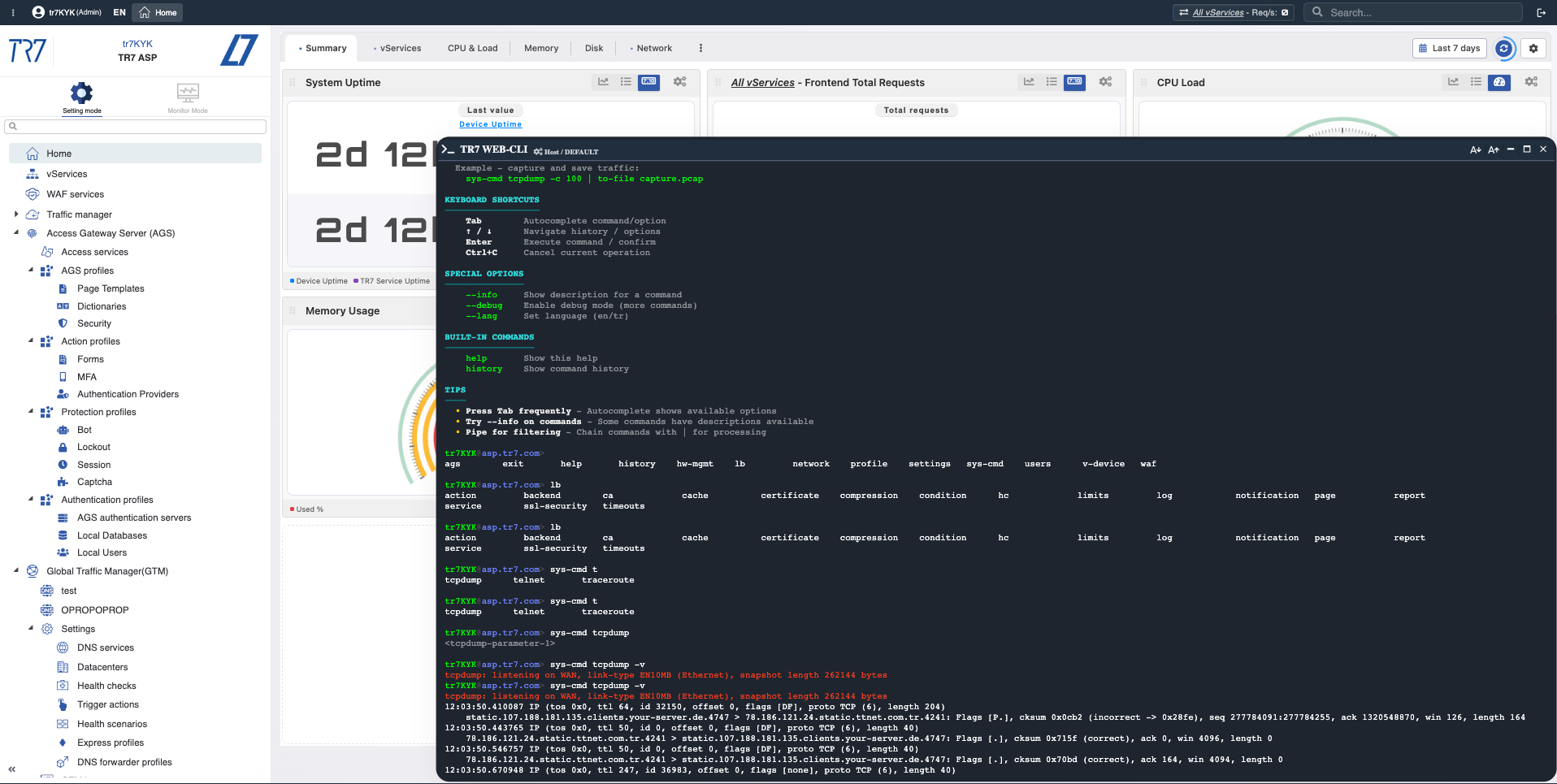
メトリクスは仮説を提供しますが、検証にはコマンドが必要な場合があります。Webコンソールからping、traceroute、curl、tcpdumpを実行できます。SSHは不要—結果は同じ画面に表示されます。
Webコンソール:WebUIから診断コマンド—バックエンド接続性、DNS、ルート検証を迅速に実行。
コマンド出力:結果が即座に表示—tcpdumpを使用したターゲットトラフィックキャプチャの例。
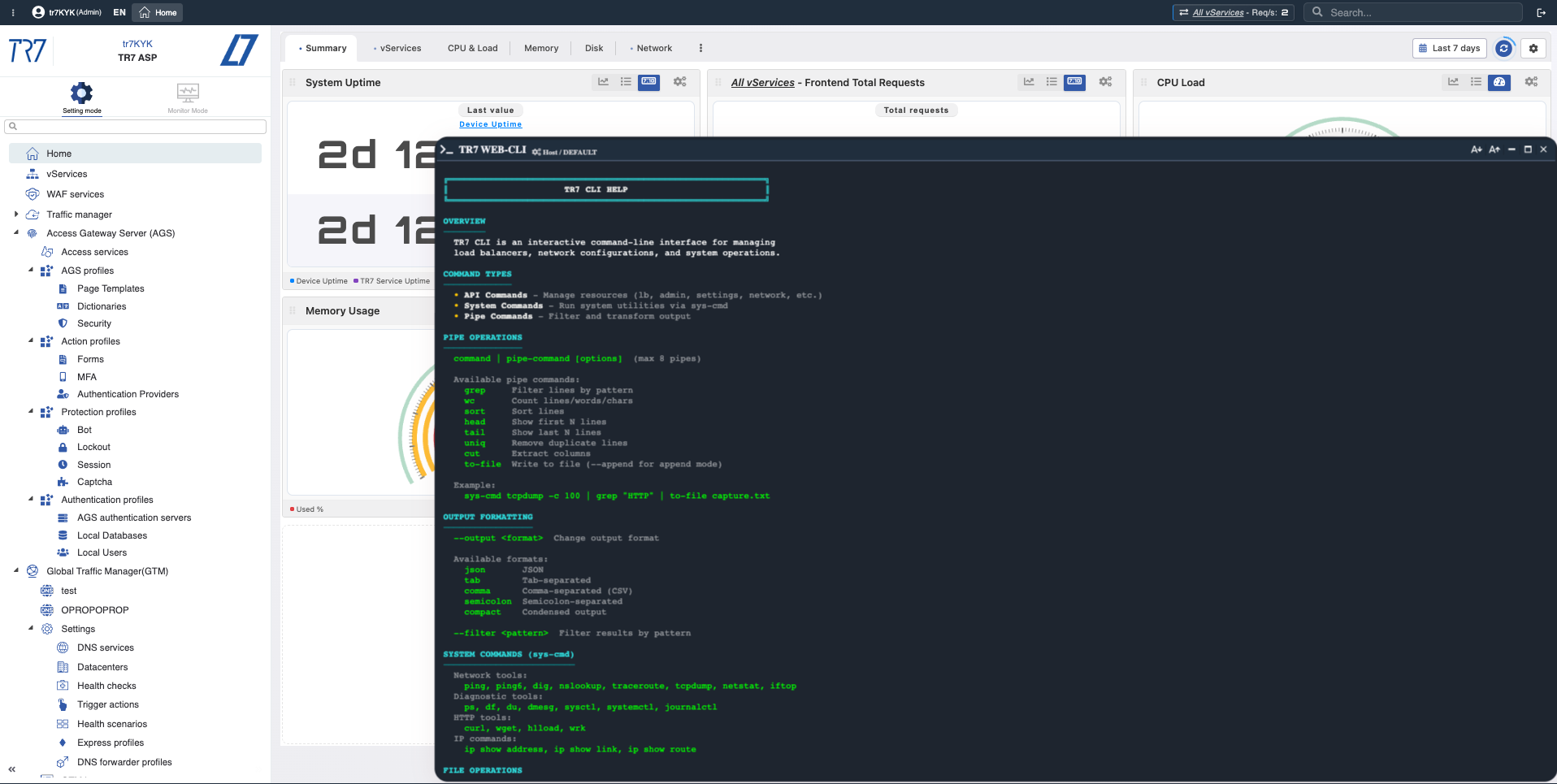
WebコンソールとTR7 CLI:UIからの即座の診断と証拠収集
TR7での調査はチャートで終わりません。Webコンソールは、本番環境でWebインターフェースから最も必要なシステムおよびネットワークコマンドを実行できます。SSHは不要です。TR7 CLIは同じ機能をコマンドラインにもたらします。出力フォーマット(JSON/CSV/tab)とパイプコマンドにより、調査手順を再現可能にします。
ネットワークチェック:ping、traceroute、dig、iftop
アプライアンスからバックエンド接続性、DNS解決、パス分析、リアルタイム帯域幅分布を検証します。
ターゲットトラフィックキャプチャ:tcpdump、ssldump
特定のhost/portのパケットをキャプチャします。TLSハンドシェイクを検査します。関連トラフィックのみをファイルに保存します。
バックエンドテスト:curl、wrk
ADCの視点からバックエンドのレスポンスコードと時間を測定します。必要に応じて制御された負荷テストを実行します。
システムステータス:netstat、ps、df、journalctl
単一画面からTCP状態、プロセス、ディスク使用率、システムログを表示します。
Webコンソール:調査フローの例
Flow Panelで警告を発見しました。以下のフローは迅速なトリアージのための実践的な例です。
- メトリクスがタイムアウトを示す
- ping backend-ip → 到達可能か?
- curl -I http://backend:8080/health → レスポンスコードは何か?
- traceroute backend-ip → パス上に中断はあるか?
- 結果:ネットワークかアプリケーション—迅速に切り分け
- SSL接続エラーが存在
- ssldump -i wan0 host client-ip → ハンドシェイクをキャプチャ
- 証明書、プロトコル、暗号の不一致を特定
- 結果:クライアントまたはサーバー設定—パケットで証明
- リクエスト数が突然増加
- iftop -i wan0 → リアルタイムトップトーカーを確認
- netstat -an | grep ESTABLISHED | wc → 接続数
- tcpdump -c 1000 port 443 | to-file spike.pcap → サンプルキャプチャ
- 結果:DDoS、ボット、正当なトラフィック—データで判断
- アプリチームは問題を見ていない
- curl -w '%{time_total}' http://backend/api → ADCの視点からの時間
- wrk -t2 -c10 -d10s http://backend/api → 負荷下でテスト
- 結果:クライアント–ADC–バックエンドチェーン—差が明確に
メトリクスライブラリ:遡及的監視と分析チャート
以下の見出しは、TR7のインターフェースにおけるメトリクスチャートグループのタイトルです。各グループには、関連するメトリクスを遡及的に監視および分析できるチャートが含まれています。これらのチャートにより、インシデント中または後の特定の時間範囲を調査し、トレンドを確認し、異常を検出できます。
What?サービスへの時間経過に伴うHTTP/HTTPS総リクエスト数を表示します。
Why important?トラフィックスパイク、突然の減少、容量への影響を理解するための基本的な参照です。インシデント前後の比較が可能です。
What?時間経過に伴うHTTPレスポンスコードの分布(2xx成功、3xxリダイレクト、4xxクライアントエラー、5xxサーバーエラー)を表示します。
Why important?エラー率の増加を迅速に発見します。5xxスパイクはバックエンド問題を示す可能性があり、4xxスパイクはクライアント側または設定問題を示す可能性があります。
What?1秒あたりに開かれた新しいTCP接続を表示します。
Why important?突然の接続増加は、DDoS攻撃、ボット活動、クライアント側の再接続問題を示す可能性があります。
What?同時にアクティブなセッション数を表示します。
Why important?容量制限にどれだけ近づいているかを理解するのに役立ちます。セッション制限に近づくとパフォーマンス低下を引き起こす可能性があります。
What?サービスを通過する総データ量(ビット/秒またはバイト/秒)を表示します。
Why important?帯域幅使用率とトラフィック傾向を理解するために使用されます。スループット低下はネットワークまたはバックエンド問題を示す可能性があります。
What?同時にアクティブな暗号化TLS接続数を表示します。
Why important?SSL/TLS操作はCPU集約的です。このメトリクスは容量計画とパフォーマンス分析に重要です。
What?1秒あたりに実行されたTLSハンドシェイクを表示します。
Why important?突然のハンドシェイク率増加は、セッション再利用が機能していないか、クライアント側の問題を示す可能性があります。高いハンドシェイク率はCPU負荷を増加させます。
What?TLSセッション再利用率と統計を表示します。
Why important?低いセッション再利用は不必要なCPU使用とより高いレイテンシを引き起こします。このメトリクスはTLSパフォーマンス最適化をガイドします。
What?HTTPレスポンスの圧縮率と圧縮データ量を表示します。
Why important?圧縮は帯域幅を節約しますがCPUを使用します。このバランスを理解することはパフォーマンス最適化に重要です。
What?時間経過に伴うWeb Application Firewallによってブロックされたリクエスト数を表示します。
Why important?ブロックの突然の増加は攻撃の波または新しいルールによる誤検知を示す可能性があります。いずれの場合も調査が必要です。
What?WAFによって検出された攻撃試行の数とタイプを表示します。
Why important?脅威レベルと攻撃傾向を追跡できます。どの攻撃タイプが試行されているか、どのくらいの頻度かを理解することはセキュリティ戦略にとって価値があります。
What?WAFルールとカテゴリーのどの割合がトリガーされているかを表示します。
Why important?どのルールセットがアクティブで、どれが最も頻繁に発火するかを示します。ルールチューニングと最適化決定のための基本的なデータです。
What?サービスによって使用される受信および送信帯域幅を表示します。
Why important?リンク飽和とスループット変化を監視するために使用されます。帯域幅制限に近づくとパフォーマンス問題を引き起こす可能性があります。
What?サービスのキャッシュ動作、キャッシュへの書き込みとキャッシュからの読み取りデータを表示します。
Why important?キャッシングはバックエンド負荷を削減し、レスポンスタイムを改善します。キャッシュ動作の変化はパフォーマンスに直接影響します。
What?リクエストの何パーセントがキャッシュから提供されているかを表示します。
Why important?高いヒット率はバックエンド負荷を削減し、レスポンスタイムを短縮します。ヒット率の低下はキャッシュ設定またはコンテンツ変更の調査が必要です。
What?このサービスに起因するCPU使用率のパーセンテージを表示します。
Why important?単一のサービスがどれだけのCPUを消費しているかを確認できます。1つのサービスが過剰なCPUを使用すると、他のサービスに影響する可能性があります。
What?このサービスに起因するメモリ使用量を表示します。
Why important?サービスごとのメモリ消費を監視することで、メモリリークや過剰なリソース使用問題を検出するのに役立ちます。
What?サービスのメモリ使用量をパーセンテージで表示します。
Why important?トレンド分析と容量計画に使用されます。継続的に増加するメモリ使用量は問題の兆候である可能性があります。
What?サービスの最後の再起動からの経過時間を表示します。
Why important?サービスの再起動をインシデントタイムラインと関連付けることができます。予期しない再起動は調査が必要です。
What?受信リクエストがバックエンドサーバー間でどのように分配されているかを表示します。
Why important?不均衡な負荷分散を検出できます。バックエンドが不釣り合いに多いまたは少ないリクエストを受け取っている場合、設定または健全性の問題を示す可能性があります。
What?各バックエンドサーバーの平均レスポンスタイムを比較的に表示します。
Why important?遅いバックエンドを迅速に特定できます。1つのバックエンドのレスポンスタイムが他より著しく高い場合、そのサーバーに問題がある可能性があります。
What?各バックエンドサーバーのヘルスチェック結果と健全性ステータスを表示します。
Why important?どのバックエンドが健全、ダウン、または劣化しているかを即座に確認できます。
What?ヘルスチェックがどのくらいの頻度で実行されるか、そのレスポンスタイムを表示します。
Why important?ヘルスチェックタイミングの問題を検出できます。遅いヘルスチェックレスポンスは、問題のあるバックエンドの検出を遅らせる可能性があります。
What?バックエンドへの接続確立時間の分布を表示します。
Why important?ネットワーク遅延とTCP接続問題を検出するのに役立ちます。高い接続時間はネットワークまたはバックエンド側の問題を示します。
What?バックエンド間のアクティブな接続の分布を表示します。
Why important?スティッキーセッションの動作と負荷分散を監視できます。1つのバックエンドに不釣り合いな接続蓄積はパフォーマンス問題を引き起こす可能性があります。
What?バックエンドへ向かうトラフィックの帯域幅分布を表示します。
Why important?どのバックエンドがどれだけのトラフィックを受信しているかを確認できます。過剰なトラフィックを受信しているバックエンドはボトルネックになる可能性があります。
What?バックエンドからのレスポンストラフィックの帯域幅分布を表示します。
Why important?バックエンドのレスポンスサイズとトラフィックパターンを理解するのに役立ちます。大きなレスポンスを生成するバックエンドは帯域幅計画に影響します。
What?バックエンド間のアクティブセッションの分布を表示します。
Why important?セッション永続性の動作とバックエンドごとのセッション密度を監視できます。
What?バックエンドにルーティングされるのを待っているリクエストのキュー状態を表示します。
Why important?キューの蓄積はバックエンド容量不足の早期シグナルです。キューが満杯になると、レスポンスタイムが増加します。
What?WANインターフェースを通過する総トラフィック量を表示します。
Why important?リンク容量にどれだけ近づいているかを確認できます。リンク飽和はパケット損失とレイテンシ増加を引き起こします。
What?1秒あたりに処理されたパケット(PPS)を表示します。
Why important?PPS異常はDDoS攻撃やネットワーク問題を示す可能性があります。帯域幅が低いのに高いPPSは小さなパケットのフラッドを示します。
What?ネットワークインターフェースの運用ステータス(アップ/ダウン)とリンク品質を表示します。
Why important?リンクステータスの変化を即座に検出できます。断続的なリンクダウンは接続問題を引き起こします。
What?インターフェースで発生するエラー(CRC、衝突、ドロップなど)を表示します。
Why important?インターフェースエラーは物理ケーブルの問題、MTU不一致、ハードウェア障害を示す可能性があります。
What?サブインターフェースとVLANのステータスを表示します。
Why important?複雑なネットワークトポロジーで各サブユニットのステータスを個別に監視できます。
What?デバイスの総CPU使用率のパーセンテージを表示します。
Why important?高いCPU使用率はすべてのサービスのパフォーマンスに影響します。一貫して高いCPUは容量増加または最適化が必要です。
What?CPUの動作温度を表示します。
Why important?高温はサーマルスロットリングとパフォーマンス低下を引き起こす可能性があります。過度の温度上昇はハードウェア障害のリスクを高めます。
What?デバイスが最後に起動されてからの経過時間を表示します。
Why important?予期しない再起動を検出できます。アップタイムがリセットされた場合、デバイスが再起動した理由を調査します。
What?1分、5分、15分のシステム負荷平均を表示します。
Why important?システムがどれだけビジーかを理解するのに役立ちます。負荷平均がCPU数を一貫して超える場合、システムは過負荷です。
What?システムによって使用される総メモリ量を表示します。
Why important?時間経過に伴うメモリ消費を追跡できます。継続的に増加するメモリ使用量はメモリリークを示す可能性があります。
What?新しいプロセスに利用可能なメモリ量を表示します。
Why important?利用可能メモリが少ないと、新しい接続とプロセスの開始を妨げる可能性があります。
What?総メモリの何パーセントが使用されているかを表示します。
Why important?容量計画としきい値ベースのアラートに使用されます。90%以上の使用率はクリティカルレベルです。
What?ディスク上のスワップスペースの使用量を表示します。
Why important?スワップ使用は物理メモリが不十分であることを示します。アクティブなスワップ使用は著しいパフォーマンス低下を引き起こします。
What?使用済みディスクスペースの量を表示します。
Why important?ディスク充填率を監視できます。ディスクが満杯になると、ログ書き込みが停止し、システムが不安定になる可能性があります。
What?総ディスク容量を表示します。
Why important?容量計画と成長トレンド分析の参照点です。
What?ディスク容量の何パーセントが使用されているかを表示します。
Why important?90%以上は警告、95%以上はクリティカルレベルです。ディスク充満はログローテーションとアーカイブ計画が必要です。
What?ファイルシステムのinode使用量を表示します。
Why important?ディスクスペースが空いていても、inodeが枯渇すると新しいファイルを作成できません。多数の小さなファイルを持つシステムにとって重要です。
What?1秒あたりのディスク読み取り操作と速度を表示します。
Why important?高い読み取りI/Oはディスクボトルネックを示す可能性があります。特に非SSDシステムで重要です。
What?1秒あたりのディスク書き込み操作と速度を表示します。
Why important?ログと監査の書き込みは継続的にディスクI/Oを生成します。書き込み速度が低下すると、ログ損失のリスクが発生します。
What?ディスク操作の平均完了時間を表示します。
Why important?高いI/Oレイテンシはディスクパフォーマンス低下の早期シグナルです。レイテンシ増加は全体的なシステムパフォーマンスに影響します。
What?システム上の総TCP接続数を表示します。
Why important?接続制限に近づいているかどうかを確認できます。接続制限を超えると、新しい接続が拒否されます。
What?アクティブにデータを転送している接続数を表示します。
Why important?実際のワークロードの指標です。確立済み接続数は容量に直接関連します。
What?TIME_WAIT状態で待機している接続数を表示します。
Why important?高いTIME_WAIT数はポート枯渇リスクを示します。短命な接続と高トラフィックがTIME_WAIT蓄積を引き起こします。
What?CLOSE_WAIT状態で待機している接続数を表示します。
Why important?高いCLOSE_WAIT数はアプリケーションが接続を適切にクローズしていないことを示します。これは通常、アプリケーション側のバグです。
What?TCPパケットの再送信数を表示します。
Why important?再送信の増加はネットワーク品質の問題、パケット損失、輻輳を示します。高い再送信率はレイテンシ増加とスループット低下を引き起こします。
What?すべてのvServiceの総リクエスト数を1つのチャートに表示します。
Why important?デバイス全体の総トラフィック量とトレンドを理解できます。容量計画と全体的な負荷評価の基本的な参照です。
What?すべてのvServiceの総アクティブ接続数を表示します。
Why important?デバイス全体の接続圧力と接続テーブル使用率を監視できます。接続テーブル制限に近づくと、新しい接続が拒否される可能性があります。
まとめ
TR7の主張は「より多くのチャート」ではなく、ADC/WAF層を調査対応型にすることです。vService/バックエンド/インターフェースメトリクス、イベント/通知レコード、監査証跡、HTTP/WAF可視性が単一のタイムライン上で結合され、遡及的forensicsとターゲットデバッグが根本原因分析を加速します。
エクスポート統合は価値があります。しかし、重要な瞬間に「送信されなかったので存在しない」というリスクを最小限に抑えるため、証拠の連鎖は常に製品内でアクセス可能である必要があります。
これらおよび類似の機能—データシートには表示されず、デモでは把握しにくいが、実際の運用品質を定義する詳細—は、TR7を評価するほぼすべての組織が切り替えを決定する主な理由です。