Enviar Telemetría No Es Suficiente: ADC Listo para Investigación, Análisis Forense Retroactivo y Cadena de Evidencia
Métricas en el appliance + registros de eventos + auditoría + visibilidad de tráfico para investigación retroactiva y análisis de causa raíz más rápido
CategoríaOperaciones y Observabilidad
PublicadoDecember 1, 2025
Tiempo de Lectura14 min de lectura
AutorEquipo de Ingeniería TR7
Temas
ADCWAFObservabilidadAnálisis ForenseAuditoríaDebugVisibilidad en Tiempo Real
Introducción
Cuando producción falla, tres preguntas importan: ¿Qué pasó? ¿Cuándo pasó? ¿Por qué pasó?
En la práctica, las respuestas frecuentemente están dispersas—métricas en un lugar, logs de tráfico en otro, e historial de cambios en otro lugar.
Hay otra realidad: las exportaciones a sistemas externos son típicamente selectivas. Si la señal que necesita durante un incidente nunca fue seleccionada para exportación, no la tendrá.
El enfoque de TR7 es claro: las integraciones de exportación importan, pero la investigación no debería depender únicamente de ellas. Por eso TR7 mantiene señales críticas en el appliance, alineadas en una sola línea de tiempo.
Una señal que no se captura es un riesgo que permanece invisible.
¿Por qué solo exportar no es suficiente?
Las plataformas SIEM, servidores de logs y Prometheus/Grafana son valiosas para visibilidad empresarial. Sin embargo, el éxito de la investigación depende de tener los datos correctos disponibles cuando los necesita.
La recolección selectiva es inevitable
El costo y el ruido significan que no todas las métricas/logs se exportan. Cuando ocurre un incidente, la señal crítica puede faltar.
La correlación se dificulta cuando los datos se dispersan
Cuando métricas, eventos, auditoría y logs de tráfico están en diferentes lugares, construir una sola línea de tiempo toma más tiempo.
El pipeline es otra área de riesgo
Problemas de agente, red, cuota/límite o indexación pueden causar pérdida de datos—especialmente durante incidentes.
Listo para Investigación
Dedique tiempo a resolver, no a recolectar datos. TR7 mantiene señales críticas listas en el appliance.
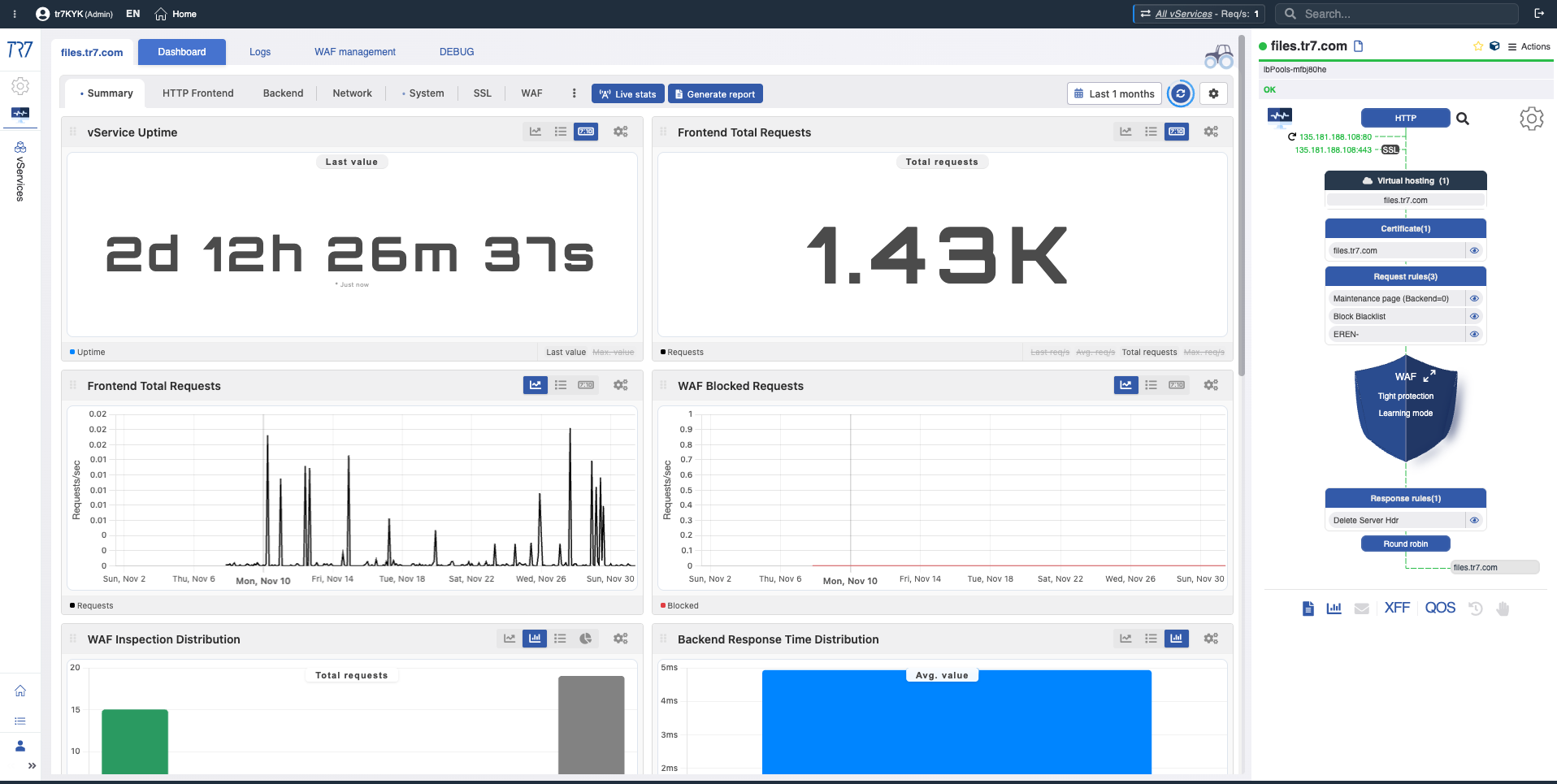
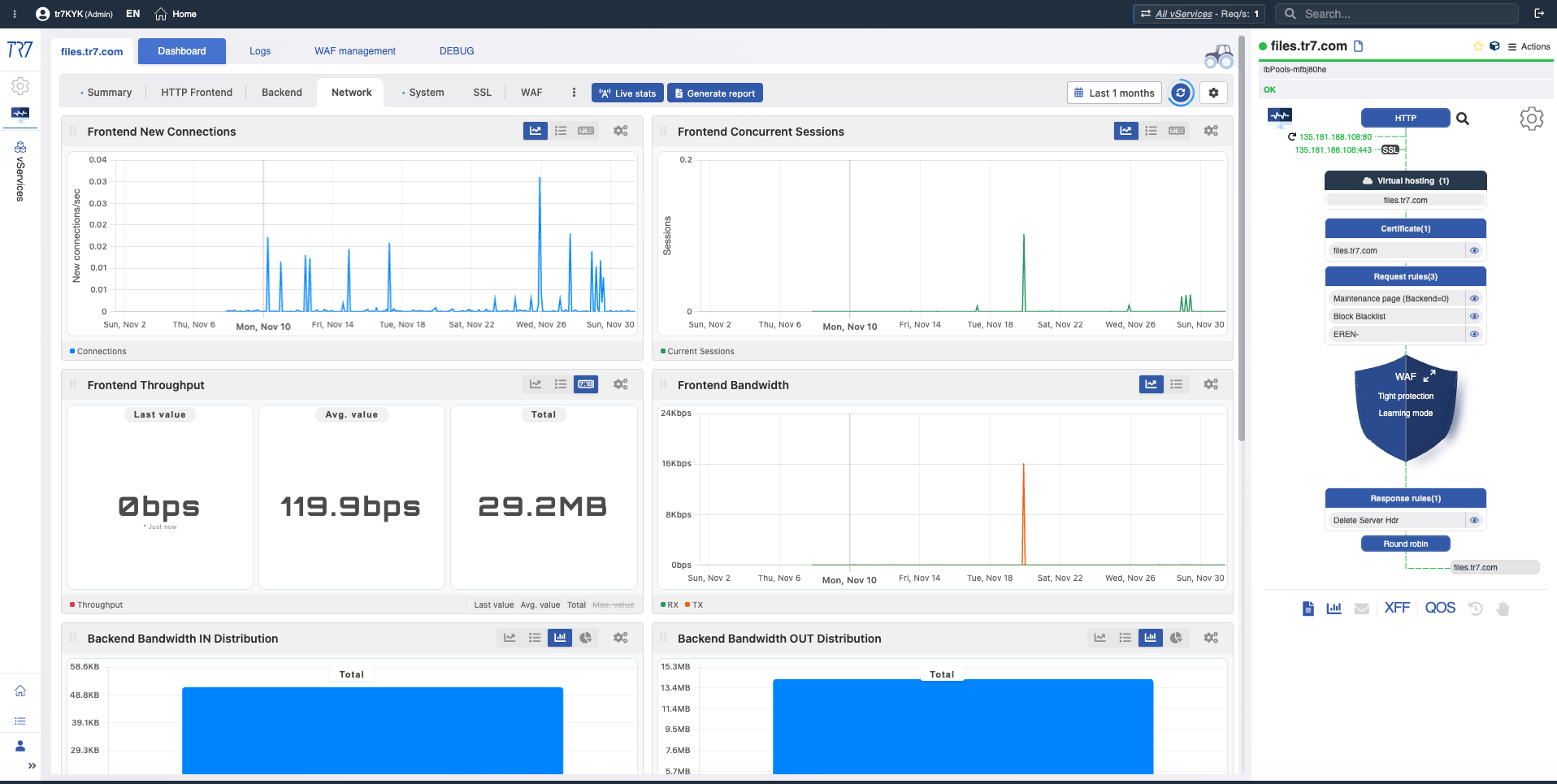
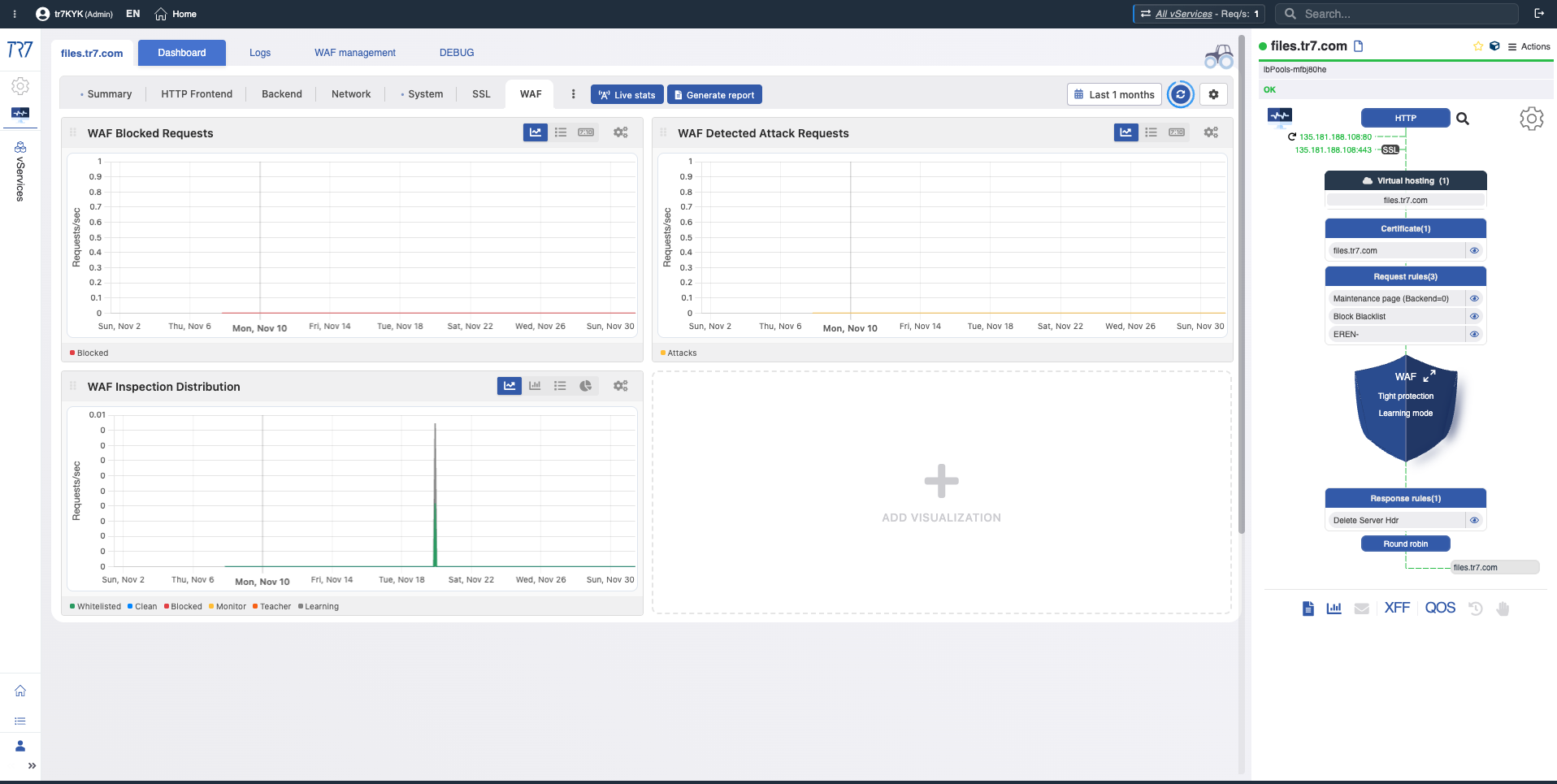
Panel de Flujo Dinámico: Visibilidad en tiempo real y punto de partida rápido
En la interfaz de TR7, la topología de servicios puede monitorearse en vivo (runtime) a través del Panel de Flujo Dinámico. Control Completo →
El panel muestra el estado del servicio con colores. Por ejemplo, si el enlace de interfaz que sirve la IP de un vService se cae, el sistema genera una advertencia y el nombre del servicio cambia de verde a amarillo.
Esto permite a los operadores ver qué investigar inmediatamente. El triage comienza más rápido y el tiempo de investigación se acorta.
Colores de Estado
Los colores en el Panel de Flujo le ayudan a leer rápidamente el estado del servicio:
Verde: Normal
Las conexiones del servicio y los health checks están funcionando como se espera.
Todos los backends saludables
Enlaces de interfaz activos
Health-checks pasando
Monitoreo rutinario
Amarillo: Atención
Hay una condición que necesita monitoreo.
Enlace de interfaz caído (el servicio puede seguir funcionando)
Los siguientes ejemplos muestran cómo progresa una investigación típica en TR7.
Escenario A: Aumento de latencia
Queja: 'La aplicación está lenta'
Verificar tendencia de tiempo de respuesta de vService → ¿hay picos?
Verificar distribución de tiempo de respuesta de backend → ¿cuál backend está lento?
Verificar con health-check y distribuciones de conexión
¿Hay alertas de recursos en los logs de notificación durante el mismo período?
Rastro de auditoría: ¿hay cambios recientes?
Resultado: Capa LB o backend específico — clarificado rápidamente
Escenario B: Aumentaron los bloqueos WAF
Queja: 'Los envíos de formularios están fallando'
Verificar métrica de bloqueos WAF → ¿hay picos?
Encontrar regla disparada desde logs HTTP/WAF
Determinar desde detalles de solicitud: ¿falso positivo o ataque real?
Rastro de auditoría: ¿hay cambios de regla/política?
Usar debug dirigido si es necesario para inspeccionar solo el tráfico relevante
Resultado: Ajuste de regla o acción de seguridad — decidir con datos
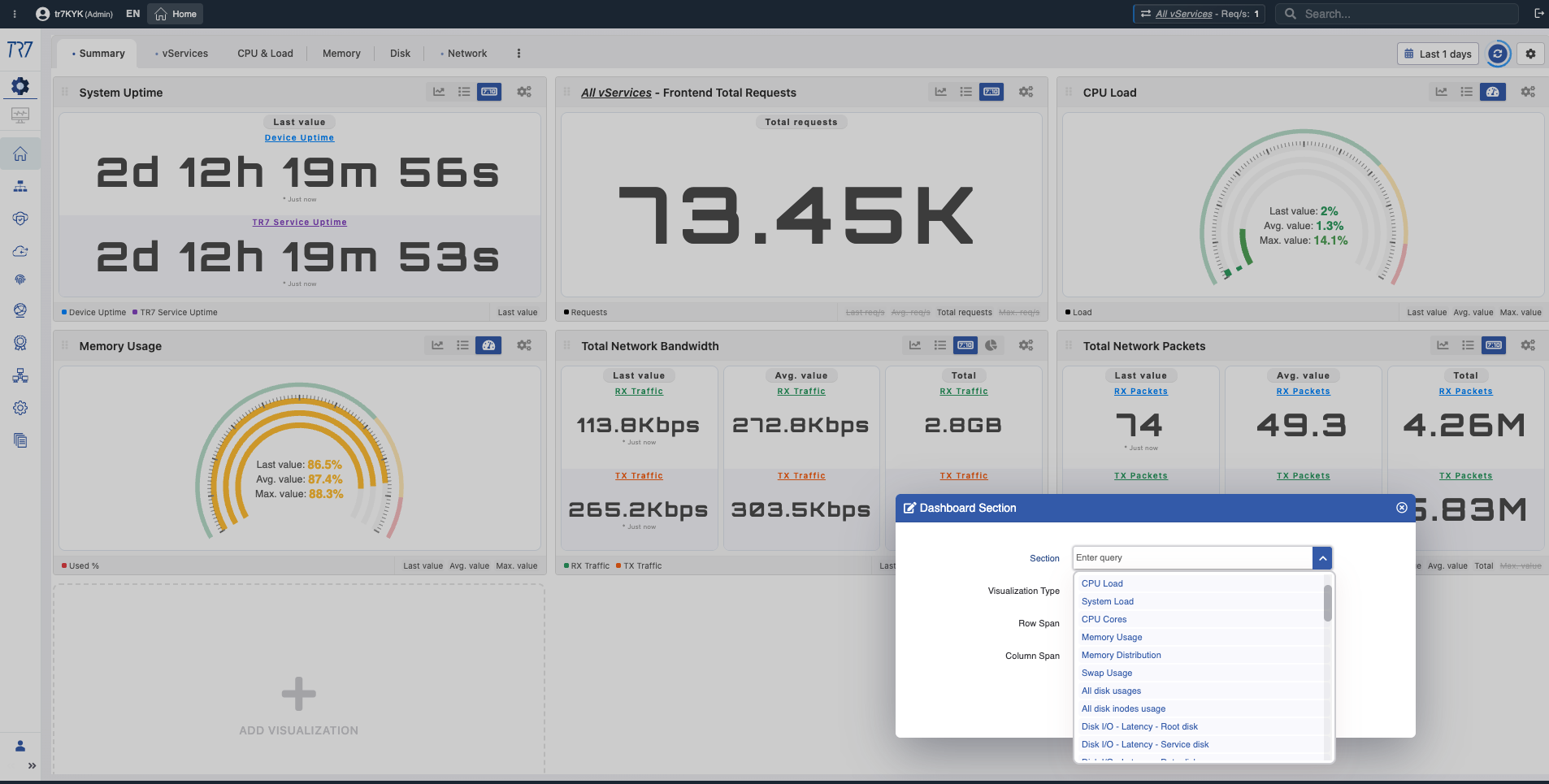
Resumen del Dispositivo: Punto de partida de la investigación
La investigación de incidentes siempre comienza con el resumen del dispositivo. CPU, memoria, uso de disco y salud del sistema — evalúe el estado general del dispositivo de un vistazo. La selección de rango de tiempo habilita el análisis forense retroactivo.
Resumen del Sistema: Uptime, solicitudes totales, carga de CPU, memoria, ancho de banda — evalúe rápidamente el estado del dispositivo durante un incidente.
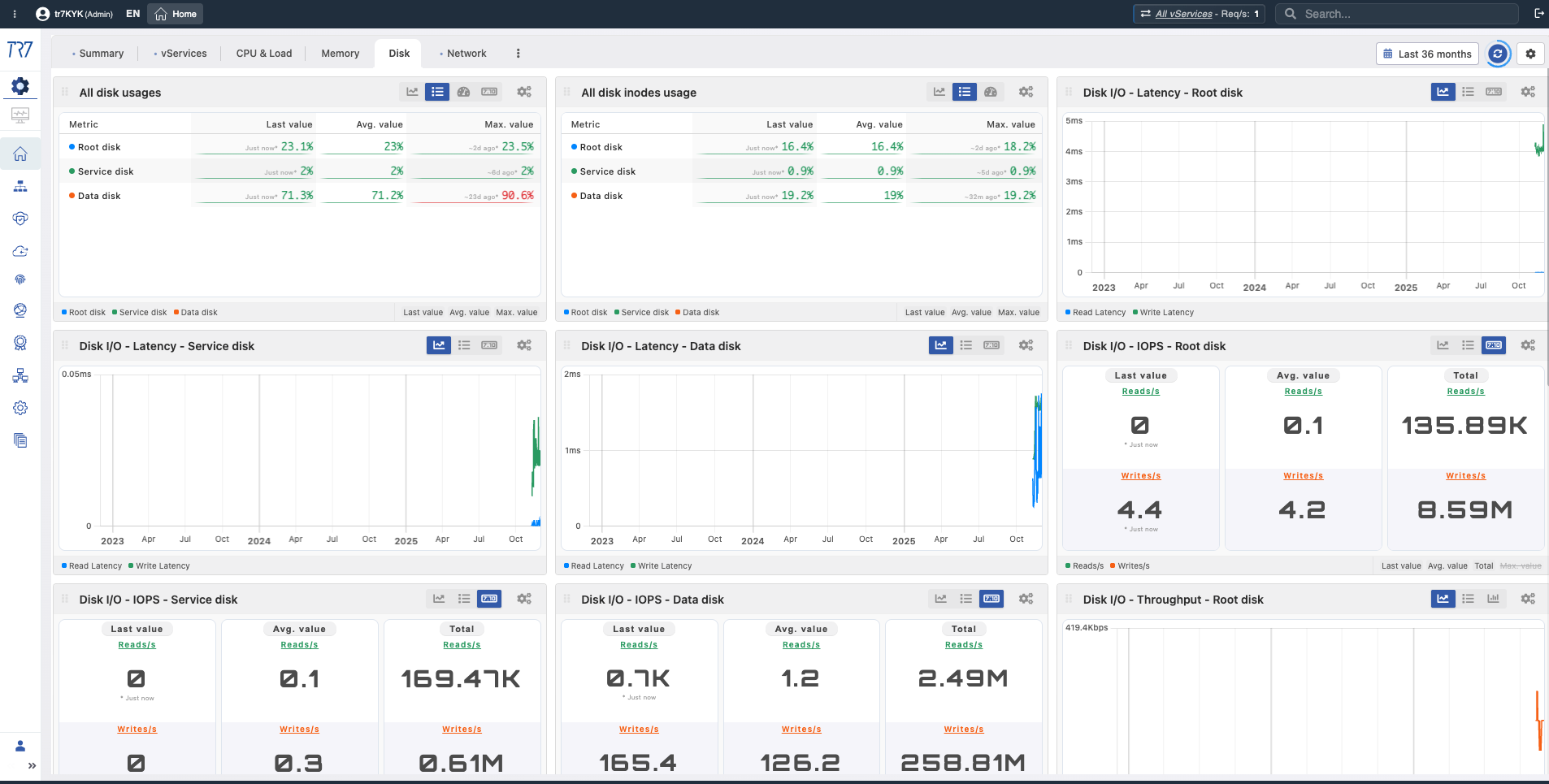
Disco e I/O: Uso, inode, latencia, IOPS — ¿está afectada la escritura de logs o el rendimiento de caché?
Servicio y Backend: Métricas de rendimiento y salud
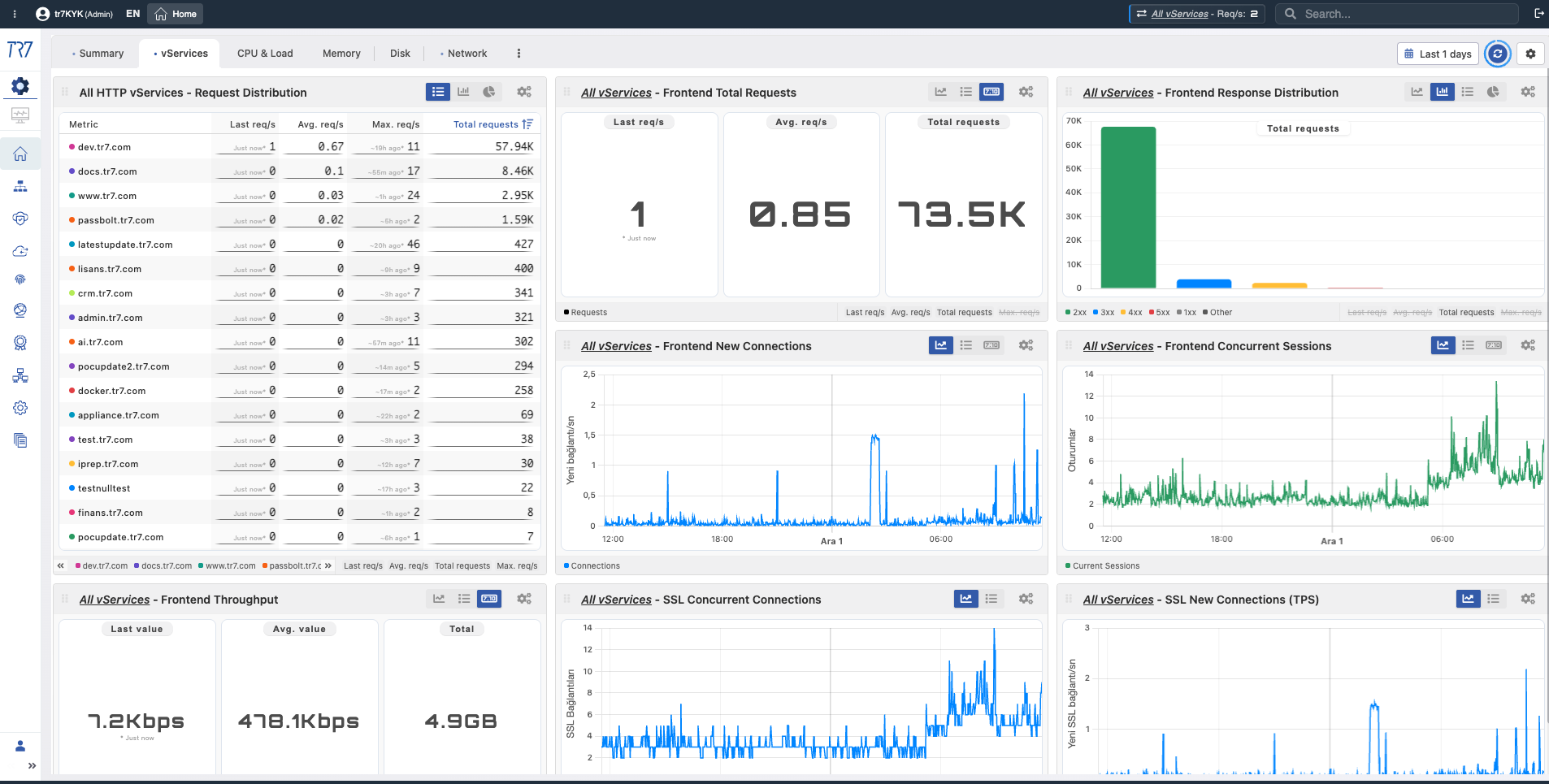
Después del resumen del sistema, profundice en la capa de servicio. Distribución de solicitudes de todos los vServices, códigos de respuesta, salud del backend y topología de servicio vía Panel de Flujo Dinámico — todo de un vistazo. Cada vService tiene su propio dashboard.
Resumen de vService: Distribución de solicitudes y códigos de respuesta (2xx/3xx/4xx/5xx) en todos los servicios — ¿qué servicio tiene anomalías?
Resumen de vService: Uptime, solicitudes frontend, conteo de bloqueos WAF y Panel de Flujo Dinámico — estado actual del servicio.
Métricas Personalizables: Reutilización SSL, compresión, tasa de aciertos de caché — agregue métricas necesarias para la investigación.
Distribuciones de Backend: ¿Cuál backend está lento? ¿Cuál recibe más solicitudes? Métricas de tiempo de respuesta y conexión.
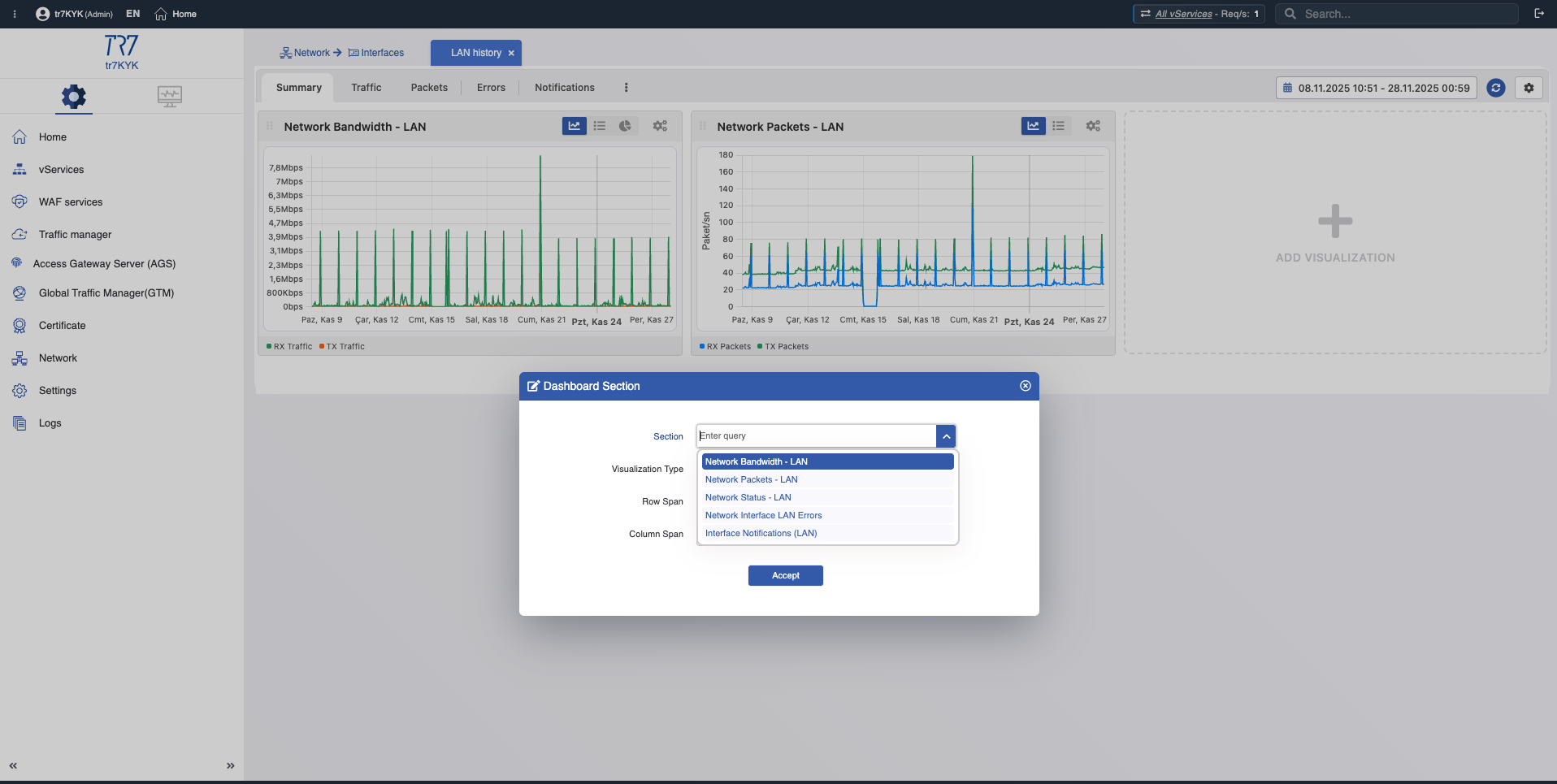
Red e Interfaz: Estado de conexión y flujo de tráfico
¿El problema está en el servicio o en la red? Topología, ancho de banda, distribución de estados TCP y métricas de interfaz responden esta pregunta. Los cambios de estado de enlace y errores de paquetes revelan rápidamente problemas en la capa de red.
Topología de Red: Ancho de banda, distribución de estados TCP — primera pista para separar problema de servicio vs red.
Métricas de Interfaz: Ancho de banda RX/TX, conteos de paquetes, errores — rendimiento y salud del enlace.
Red de vService: Throughput por servicio y estados de conexión — ¿es normal el patrón de tráfico?
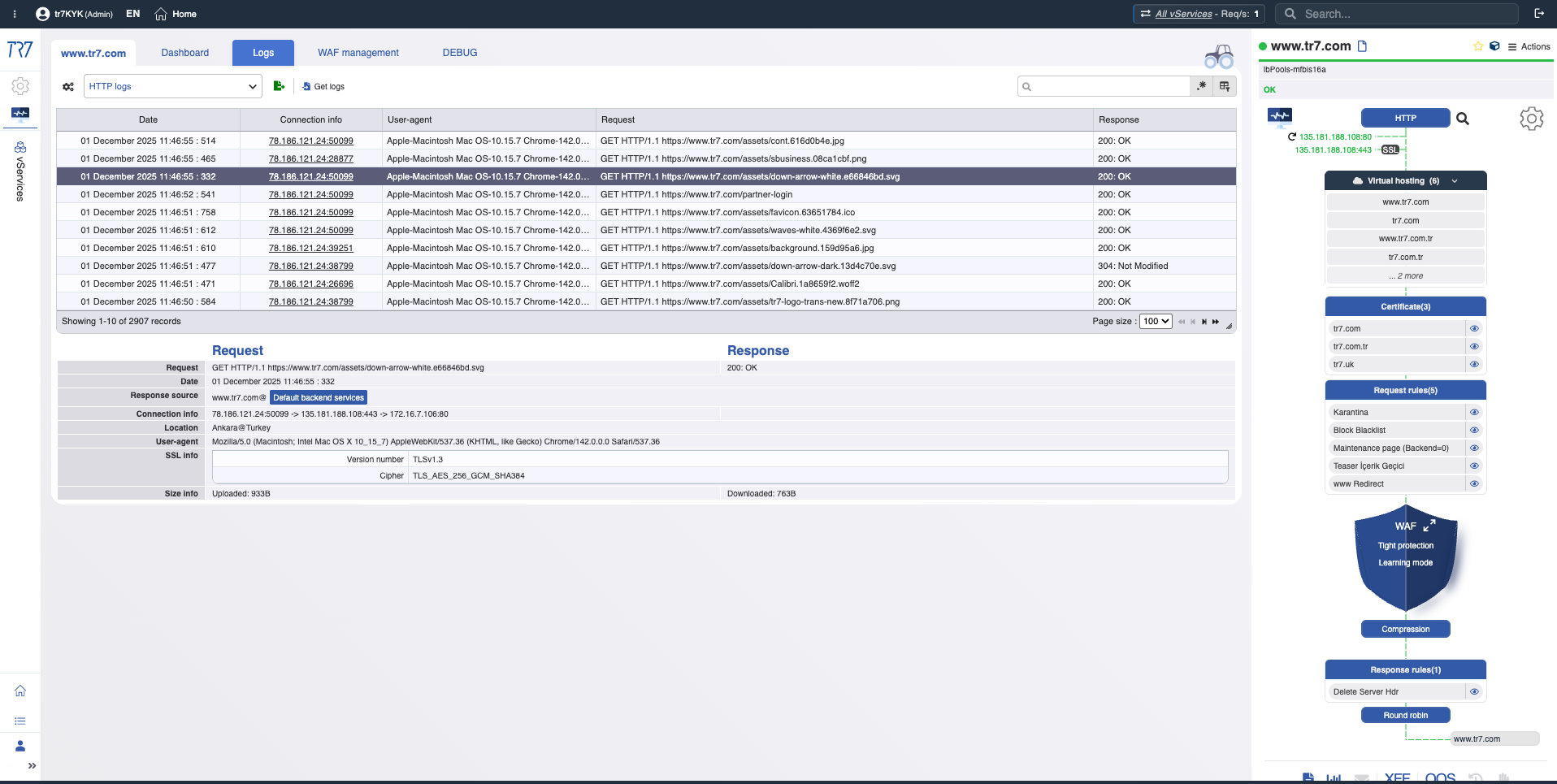
Logs HTTP y WAF: Investigación a nivel de solicitud
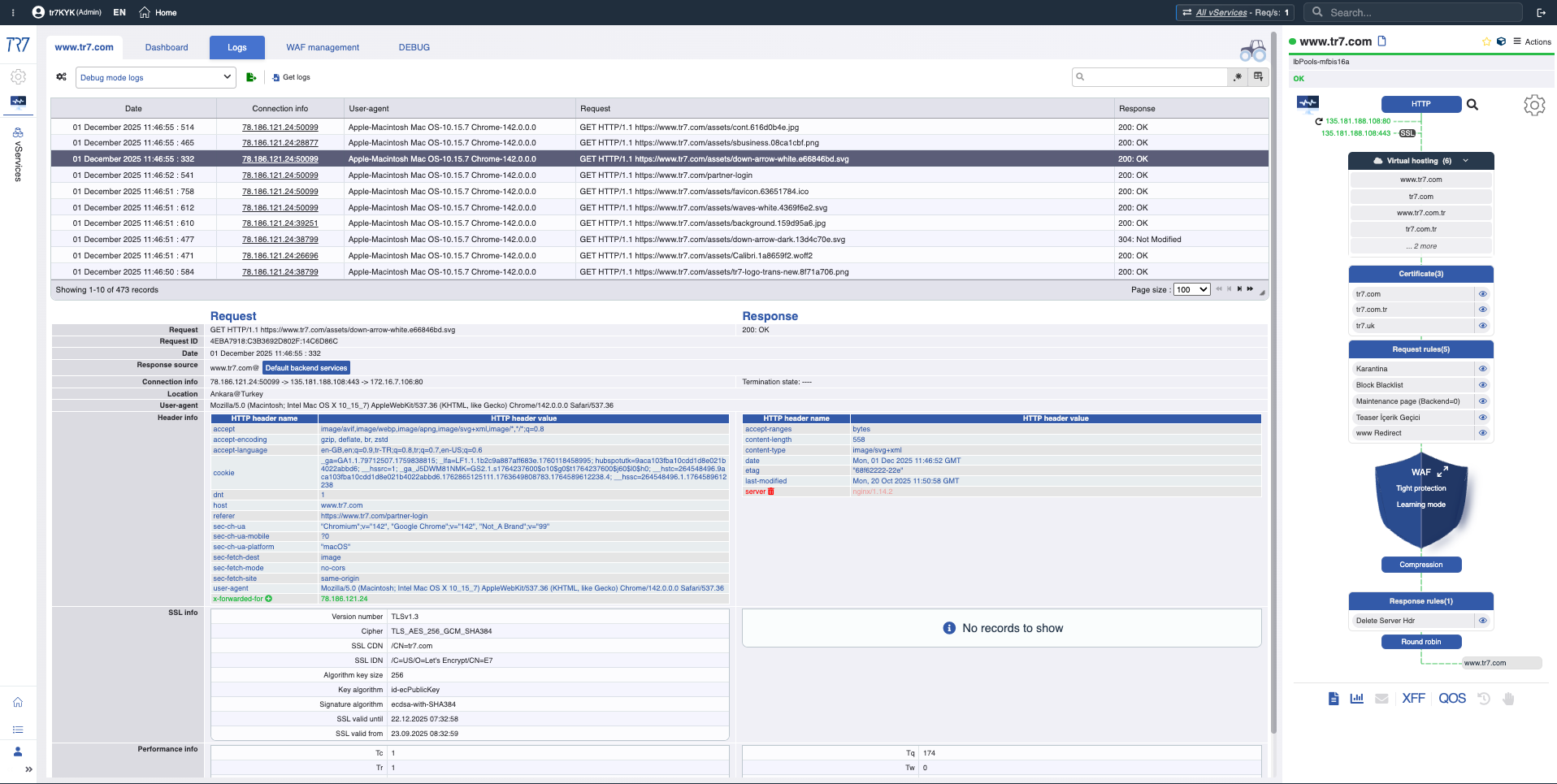
El tráfico HTTP y los eventos WAF son visibles sin habilitar debug. Cuando se necesita, el debug dirigido captura detalles completos solo para host/path/header específicos. Análisis forense a nivel de solicitud sin impactar producción.
Logs HTTP: IP de origen, destino, código de respuesta, tamaño, duración — visibilidad básica incluso con debug desactivado.
Debug Dirigido: Headers y cookies completos solo para tráfico relevante — detalle sin impactar producción.
Logs WAF: Regla disparada, detalles de solicitud, análisis basado en comportamiento — datos para evaluación de falsos positivos.
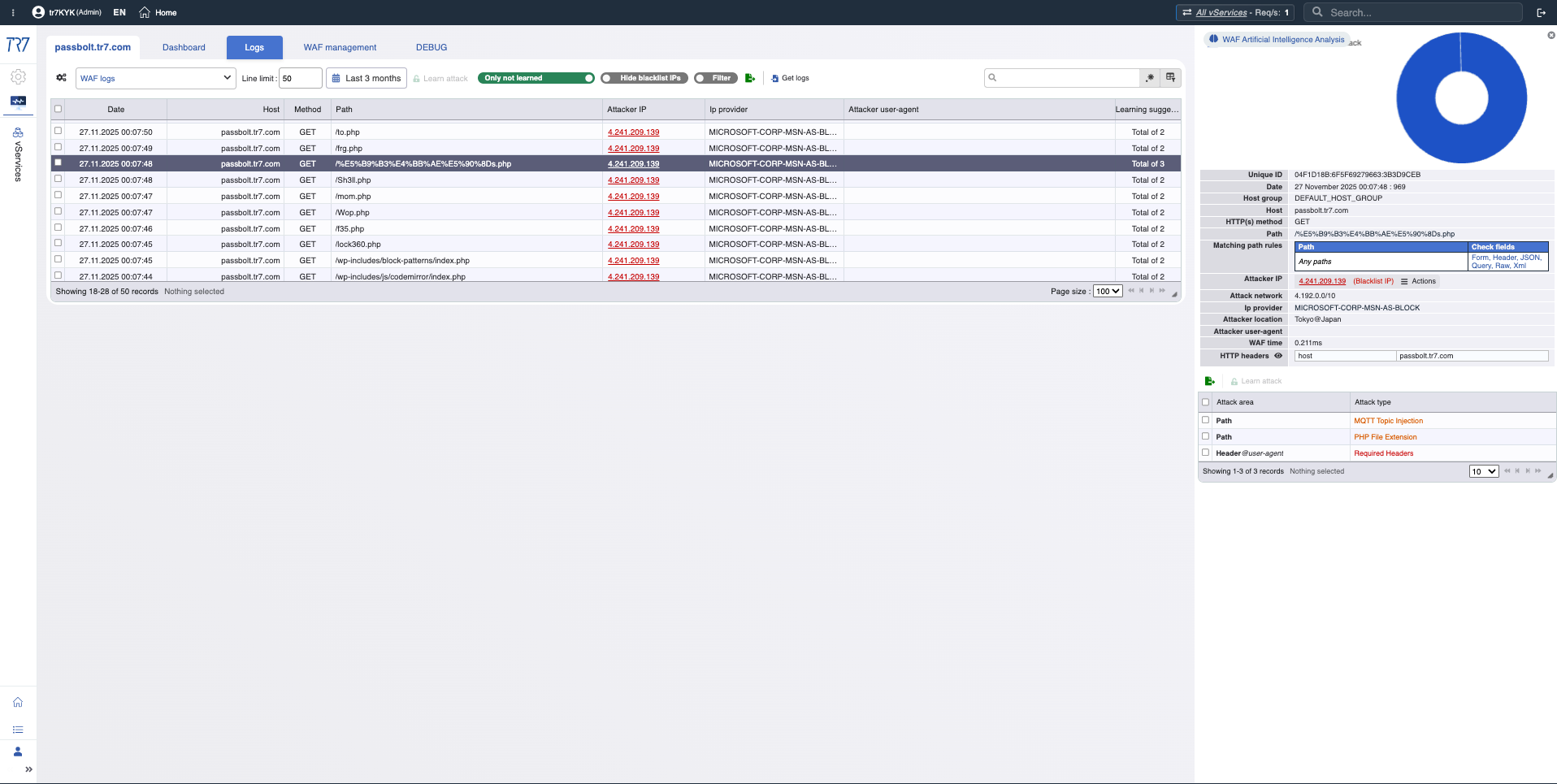
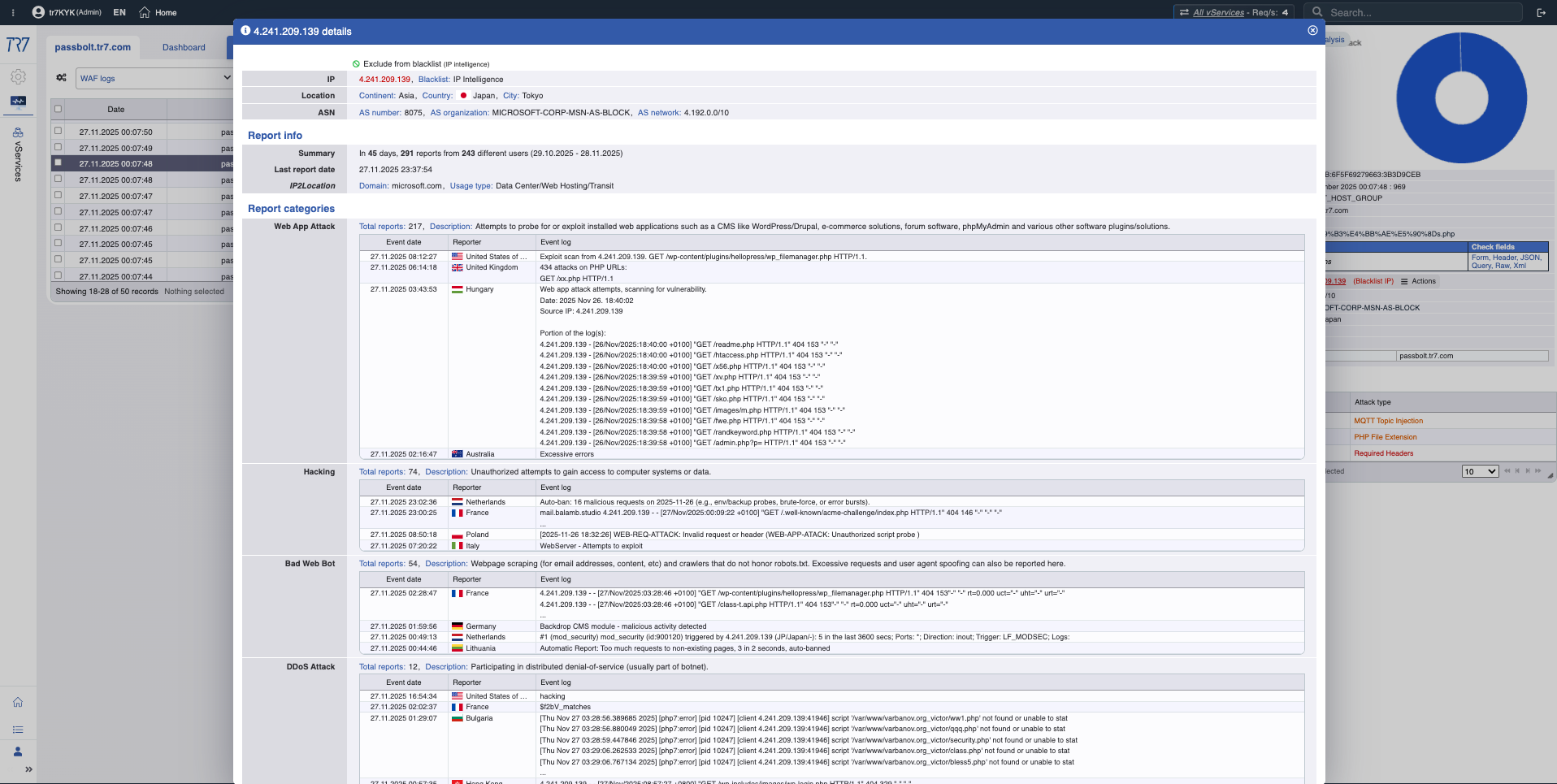
IP Intelligence y WAF: Perfil de amenaza
Las puntuaciones de reputación IP y métricas WAF revelan rápidamente el perfil del atacante. La primera respuesta a '¿falso positivo o ataque real?' está aquí. Las categorías de amenaza (botnet, proxy, VPN, Tor) muestran la naturaleza de la IP de origen.
IP Intelligence: Puntuación de reputación, categorías de amenaza — el perfil del atacante se aclara rápidamente.
Métricas WAF: Tendencia de bloqueos, distribución de inspección — resumen de eventos de seguridad.
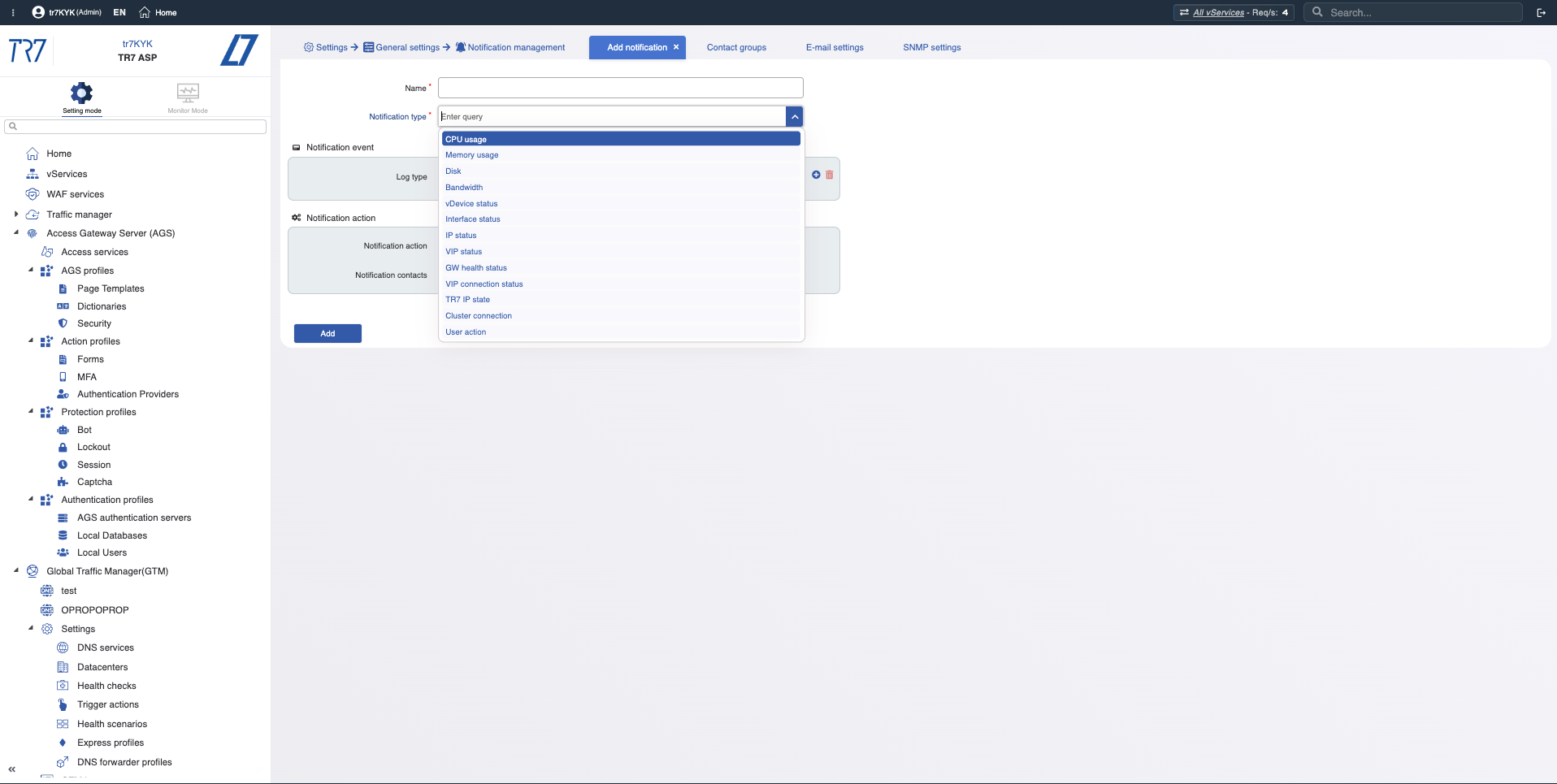
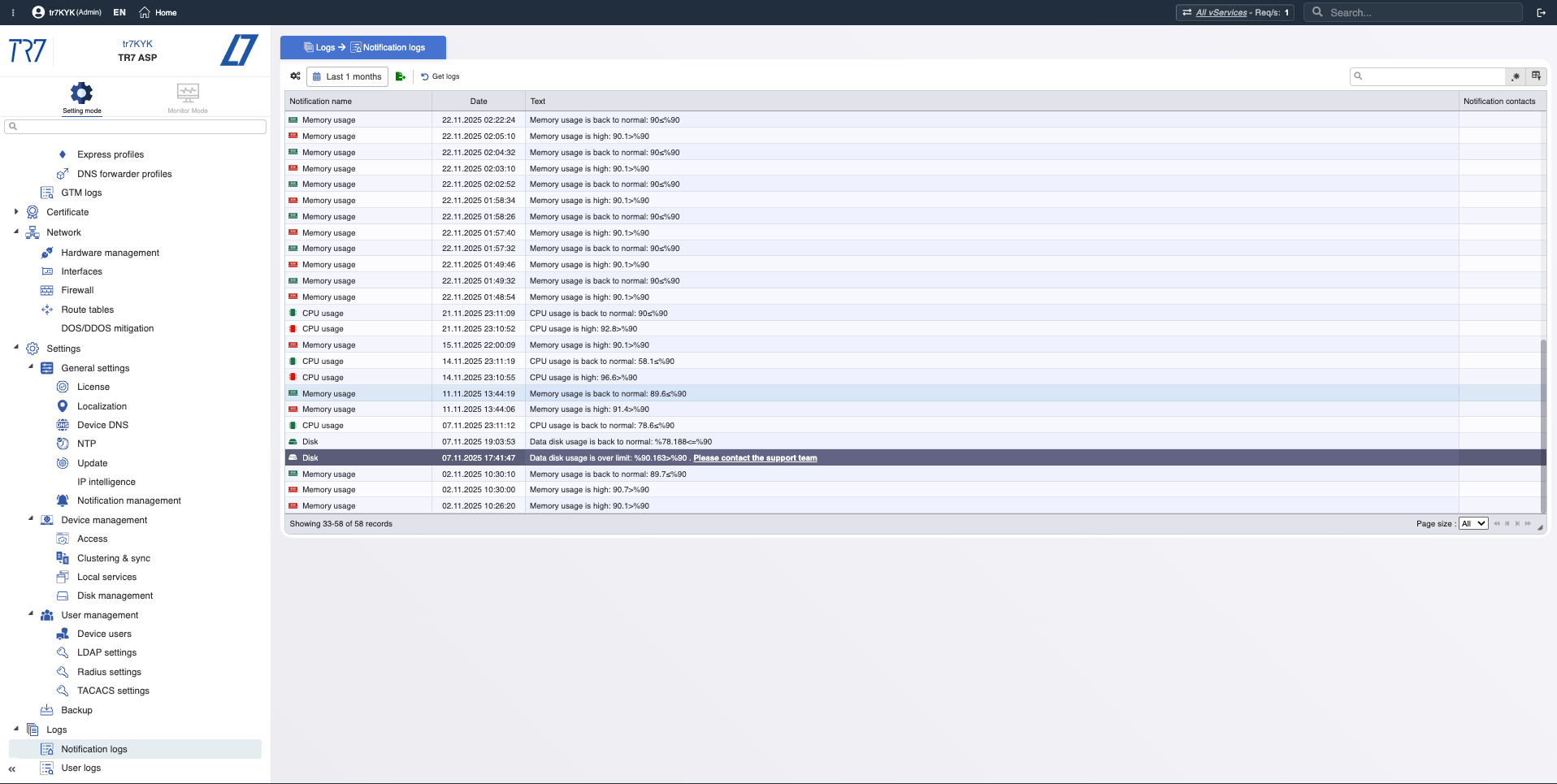
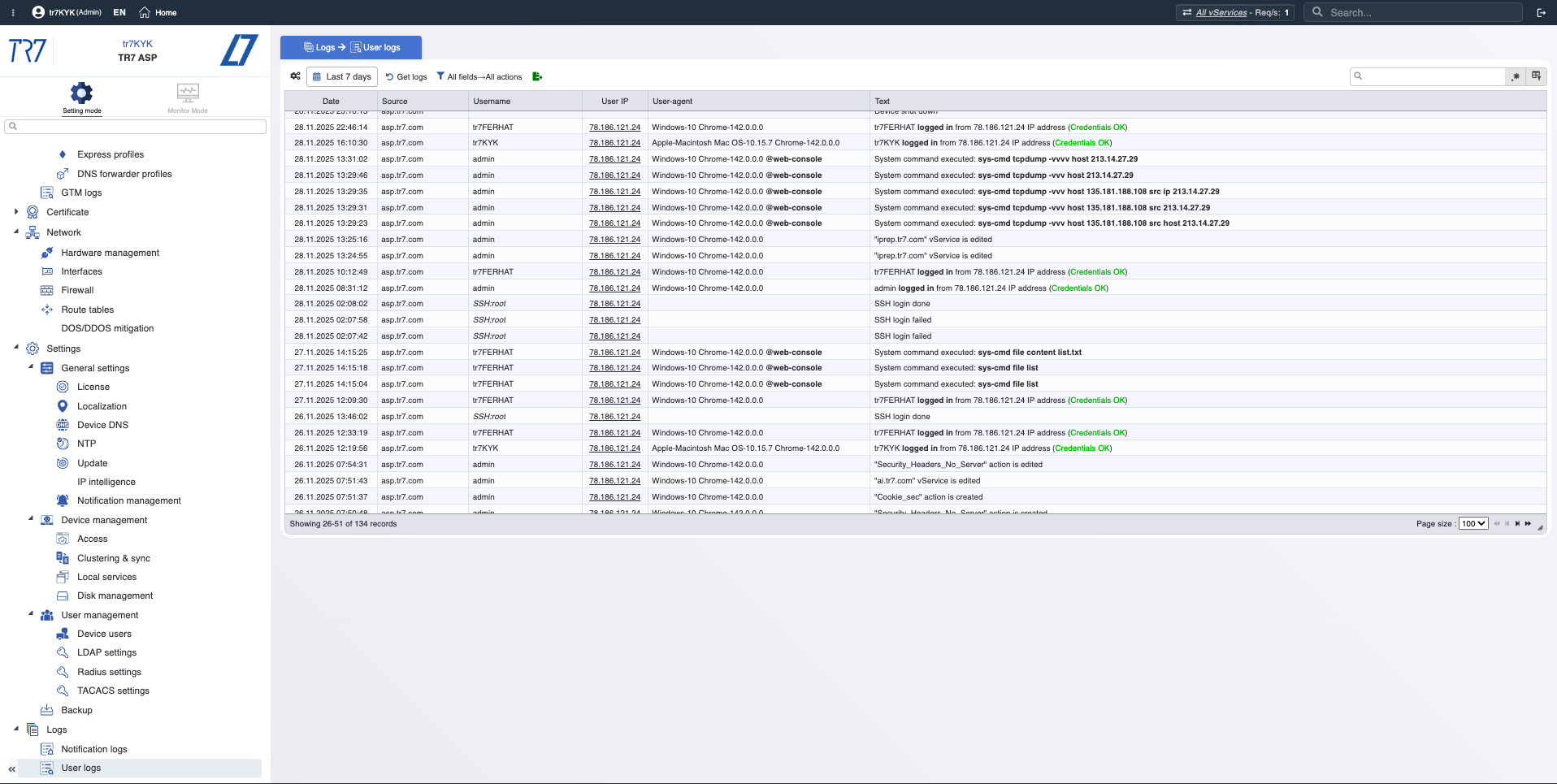
Línea de Tiempo de Eventos: Notificaciones y rastro de auditoría
Las métricas solas no son suficientes. ¿Qué alertas se dispararon? ¿Quién cambió qué y cuándo? En investigación de incidentes, '¿qué cambio afectó qué?' es crítico. TR7 mantiene registros de notificación/eventos y rastro de auditoría juntos, acelerando esta correlación.
Tipos de Notificación: CPU, memoria, disco, ancho de banda, estado del servicio — ¿qué eventos se están monitoreando?
Historial de Notificaciones: Cronología de alertas disparadas — ¿qué advertencias llegaron durante el incidente?
Rastro de Auditoría: ¿Quién cambió qué, cuándo? Evidencia para correlacionar rápidamente incidentes con cambios.
Consola Web: Verificar la hipótesis
Las métricas proporcionan una hipótesis; a veces se necesitan comandos para verificación. Ejecute ping, traceroute, curl, tcpdump desde la Consola Web. No requiere SSH — los resultados aparecen en la misma pantalla.
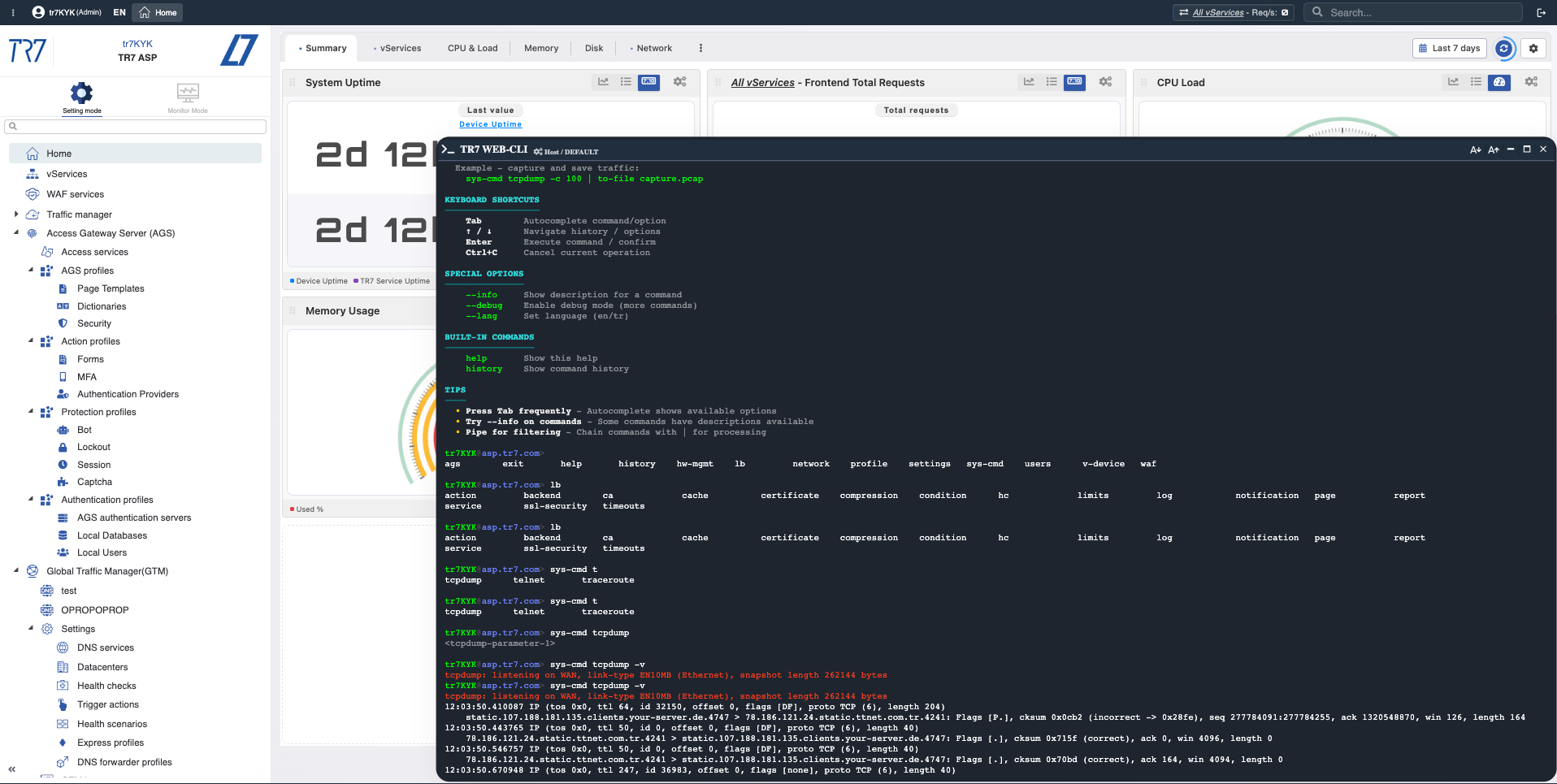
Consola Web: Comandos de diagnóstico desde la interfaz web — conectividad de backend, DNS, verificación de ruta hechos rápidamente.
Salida de Comando: Resultados mostrados instantáneamente — ejemplo de captura de tráfico dirigido con tcpdump.
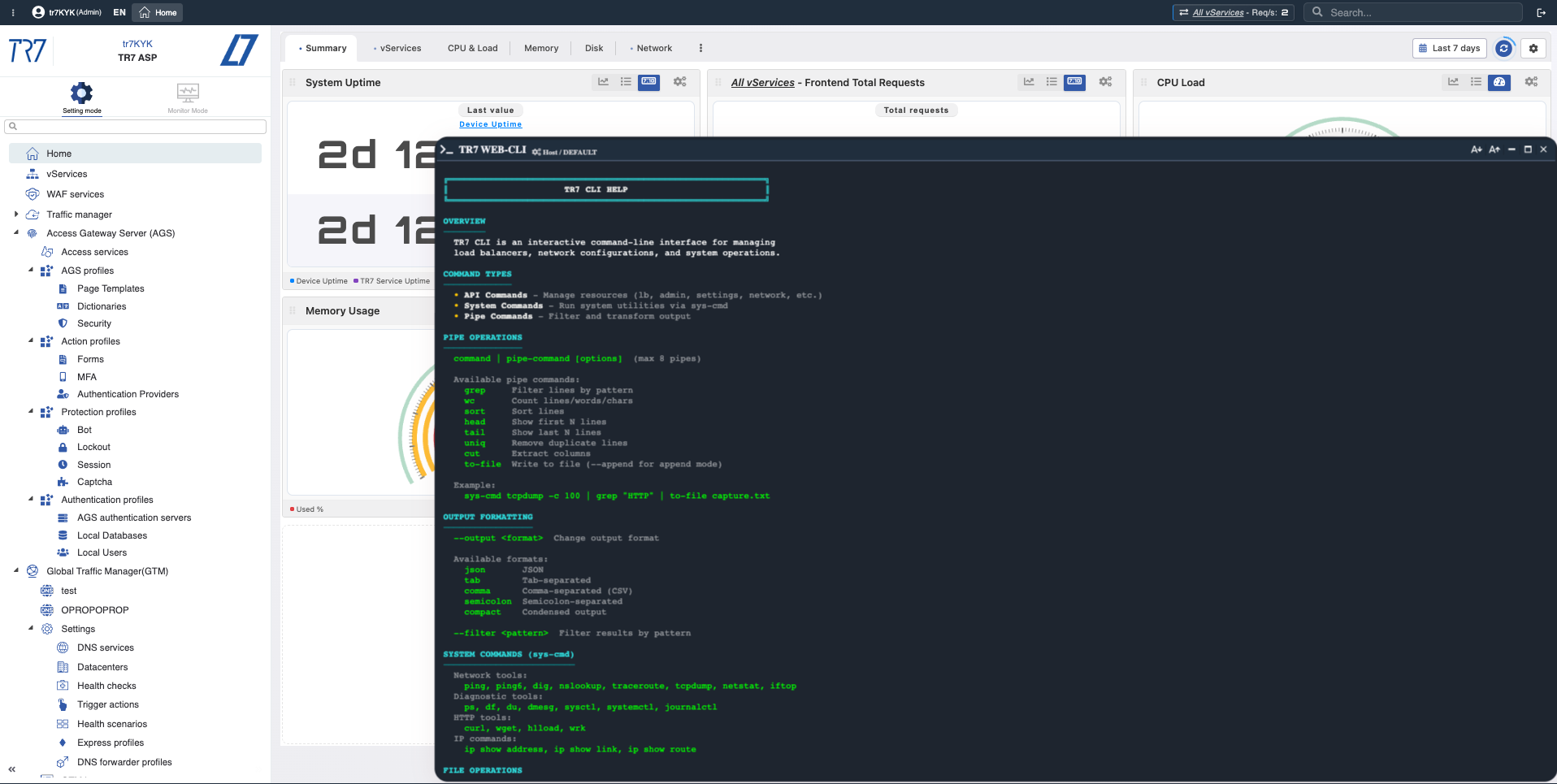
Consola Web y TR7 CLI: Diagnósticos instantáneos y recolección de evidencia desde la UI
La investigación en TR7 no se detiene en gráficos. La Consola Web habilita ejecutar los comandos de sistema y red más necesarios desde la interfaz web en producción. No requiere SSH. TR7 CLI trae la misma capacidad a la línea de comandos; los formatos de salida (JSON/CSV/tab) y comandos pipe hacen que los pasos de investigación sean repetibles.
Verificación de red: ping, traceroute, dig, iftop
Verifique conectividad de backend, resolución DNS, análisis de ruta y distribución de ancho de banda en tiempo real desde el appliance.
Captura de tráfico dirigida: tcpdump, ssldump
Capture paquetes para host/puerto específico. Inspeccione handshakes TLS. Guarde solo el tráfico relevante en archivo.
Pruebas de backend: curl, wrk
Mida código de respuesta y tiempo del backend desde la perspectiva del ADC. Ejecute pruebas de carga controladas cuando sea necesario.
Estado del sistema: netstat, ps, df, journalctl
Vea estados TCP, procesos, uso de disco y logs del sistema desde una sola pantalla.
Consola Web: Flujos de Investigación de Ejemplo
Detectó una advertencia en el Panel de Flujo. Los siguientes flujos son ejemplos prácticos para triage rápido.
¿Timeout de backend o problema de red?
Las métricas muestran timeout
ping backend-ip → ¿es alcanzable?
curl -I http://backend:8080/health → ¿cuál es el código de respuesta?
traceroute backend-ip → ¿hay cortes en el camino?
Resultado: Red o aplicación — separado rápidamente
Error TLS: ¿cliente o servidor?
Existe error de conexión SSL
ssldump -i wan0 host client-ip → capturar el handshake
Identificar discrepancia de certificado, protocolo o cipher
Resultado: Configuración de cliente o servidor — probado con paquetes
Pico repentino de tráfico: ¿ataque o carga real?
El conteo de solicitudes aumentó repentinamente
iftop -i wan0 → ver top talkers en tiempo real
netstat -an | grep ESTABLISHED | wc → conteo de conexiones
tcpdump -c 1000 port 443 | to-file spike.pcap → captura de muestra
Resultado: DDoS, bot o tráfico legítimo — decidir con datos
Backend 'rápido' pero el usuario dice 'lento'
El equipo de aplicación no ve problema
curl -w '%{time_total}' http://backend/api → tiempo desde la vista del ADC
wrk -t2 -c10 -d10s http://backend/api → prueba bajo carga
Resultado: Cadena Cliente–ADC–backend — la diferencia se aclara
No habilite debug — diríjalo.
Biblioteca de Métricas: Gráficos de Monitoreo y Análisis Retrospectivo
Los encabezados a continuación son títulos de grupos de gráficos de métricas en la interfaz de TR7. Cada grupo contiene gráficos donde las métricas relacionadas pueden monitorearse y analizarse retrospectivamente. Estos gráficos le permiten examinar rangos de tiempo específicos durante o después de un incidente, ver tendencias y detectar anomalías.
Solicitudes Totales Frontend
Total Requests
What?Muestra el conteo total de solicitudes HTTP/HTTPS al servicio a lo largo del tiempo.
Why important?Referencia fundamental para entender picos de tráfico, caídas repentinas e impacto de capacidad. Permite comparación antes/después del incidente.
Distribución de Códigos de Estado Frontend
Status Code Distribution
What?Muestra distribución de códigos de respuesta HTTP (2xx éxito, 3xx redirección, 4xx error de cliente, 5xx error de servidor) a lo largo del tiempo.
Why important?Detecte rápidamente aumentos en tasa de errores. Un pico de 5xx puede indicar problemas de backend; un pico de 4xx puede indicar problemas del lado del cliente o configuración.
Nuevas Conexiones Frontend
New Connections
What?Muestra nuevas conexiones TCP abiertas por segundo.
Why important?Aumentos repentinos de conexiones pueden indicar ataques DDoS, actividad de bots o problemas de reconexión del lado del cliente.
Sesiones Concurrentes Frontend
Concurrent Sessions
What?Muestra conteo de sesiones activas simultáneamente.
Why important?Ayuda a entender qué tan cerca está de los límites de capacidad. Aproximarse a límites de sesión puede causar degradación de rendimiento.
Throughput Frontend
Throughput
What?Muestra volumen total de datos pasando a través del servicio (bits/seg o bytes/seg).
Why important?Se usa para entender uso de ancho de banda y tendencias de tráfico. Caídas de throughput pueden indicar problemas de red o backend.
Conexiones SSL Concurrentes
SSL Concurrency
What?Muestra conteo de conexiones TLS encriptadas activas simultáneamente.
Why important?Las operaciones SSL/TLS son intensivas en CPU; esta métrica es crítica para planificación de capacidad y análisis de rendimiento.
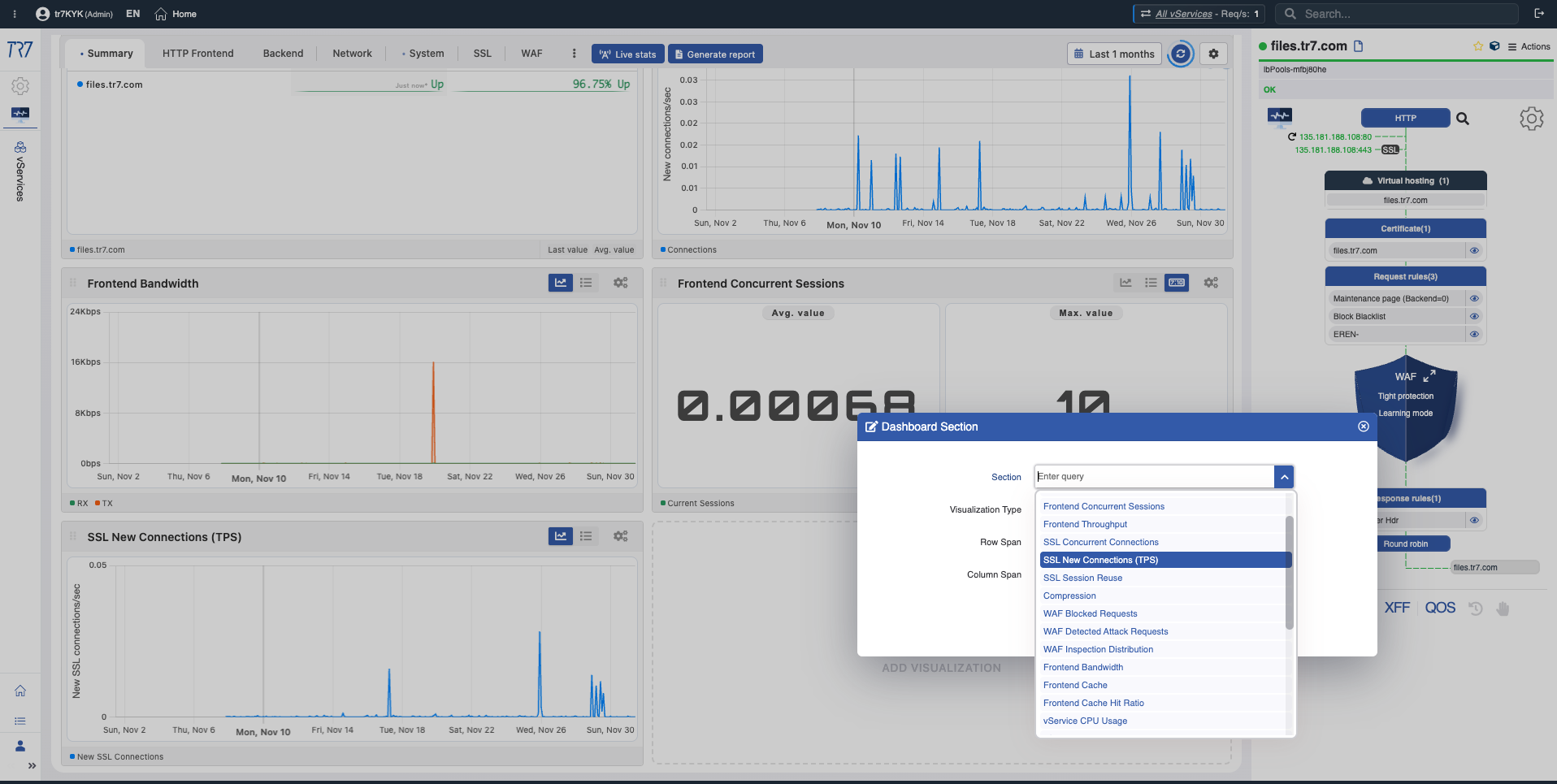
Nuevas Conexiones SSL (TPS)
TLS Handshake TPS
What?Muestra handshakes TLS realizados por segundo.
Why important?Aumentos repentinos en tasa de handshake pueden indicar que la reutilización de sesión no está funcionando o problemas del lado del cliente. Tasas altas de handshake aumentan la carga de CPU.
Reutilización de Sesión SSL
SSL Session Reuse
What?Muestra tasa de reutilización de sesión TLS y estadísticas.
Why important?Baja reutilización de sesión causa uso innecesario de CPU y mayor latencia. Esta métrica guía la optimización de rendimiento TLS.
Compresión
Compression
What?Muestra ratio de compresión de respuesta HTTP y volumen de datos comprimidos.
Why important?La compresión ahorra ancho de banda pero usa CPU. Entender este balance es importante para optimización de rendimiento.
Solicitudes Bloqueadas WAF
WAF Blocked Requests
What?Muestra conteo de solicitudes bloqueadas por Web Application Firewall a lo largo del tiempo.
Why important?Aumentos repentinos en bloqueos pueden indicar una ola de ataques o una nueva regla produciendo falsos positivos. Cualquier caso requiere investigación.
Solicitudes de Ataque Detectadas WAF
WAF Detected Attacks
What?Muestra conteo y tipos de intentos de ataque detectados por WAF.
Why important?Le permite rastrear nivel de amenaza y tendencias de ataque. Entender qué tipos de ataque se intentan y con qué frecuencia es valioso para estrategia de seguridad.
Distribución de Inspección WAF
WAF Inspection Distribution
What?Muestra qué proporción de reglas y categorías WAF se disparan.
Why important?Muestra qué conjuntos de reglas están activos y cuáles se disparan más frecuentemente. Datos fundamentales para decisiones de ajuste y optimización de reglas.
Ancho de Banda Frontend
Bandwidth
What?Muestra ancho de banda entrante y saliente usado por el servicio.
Why important?Se usa para monitorear saturación de enlace y cambios de throughput. Aproximarse a límites de ancho de banda puede causar problemas de rendimiento.
Caché Frontend
Cache
What?Muestra el comportamiento de caché del servicio, datos escritos y leídos desde caché.
Why important?El almacenamiento en caché reduce la carga del backend y mejora los tiempos de respuesta. Cambios en comportamiento de caché afectan directamente el rendimiento.
Tasa de Aciertos de Caché Frontend
Cache Hit Ratio
What?Muestra qué porcentaje de solicitudes se sirven desde caché.
Why important?Una alta tasa de aciertos reduce la carga del backend y acorta los tiempos de respuesta. Caídas en tasa de aciertos requieren investigar cambios de configuración de caché o contenido.
Uso de CPU de vService
vService CPU Usage
What?Muestra porcentaje de uso de CPU atribuido a este servicio.
Why important?Le permite ver cuánta CPU consume un solo servicio. Un servicio usando CPU excesiva puede afectar a otros.
Uso de Memoria de vService
vService Memory Usage
What?Muestra uso de memoria atribuido a este servicio.
Why important?Monitorear consumo de memoria por servicio ayuda a detectar fugas de memoria o problemas de uso excesivo de recursos.
Uso de Memoria de vService %
vService Memory %
What?Muestra uso de memoria del servicio como porcentaje.
Why important?Se usa para análisis de tendencias y planificación de capacidad. Uso de memoria en constante aumento puede señalar un problema.
Uptime de vService
vService Uptime
What?Muestra tiempo transcurrido desde el último reinicio del servicio.
Why important?Le permite correlacionar reinicios del servicio con líneas de tiempo de incidentes. Reinicios inesperados requieren investigación.
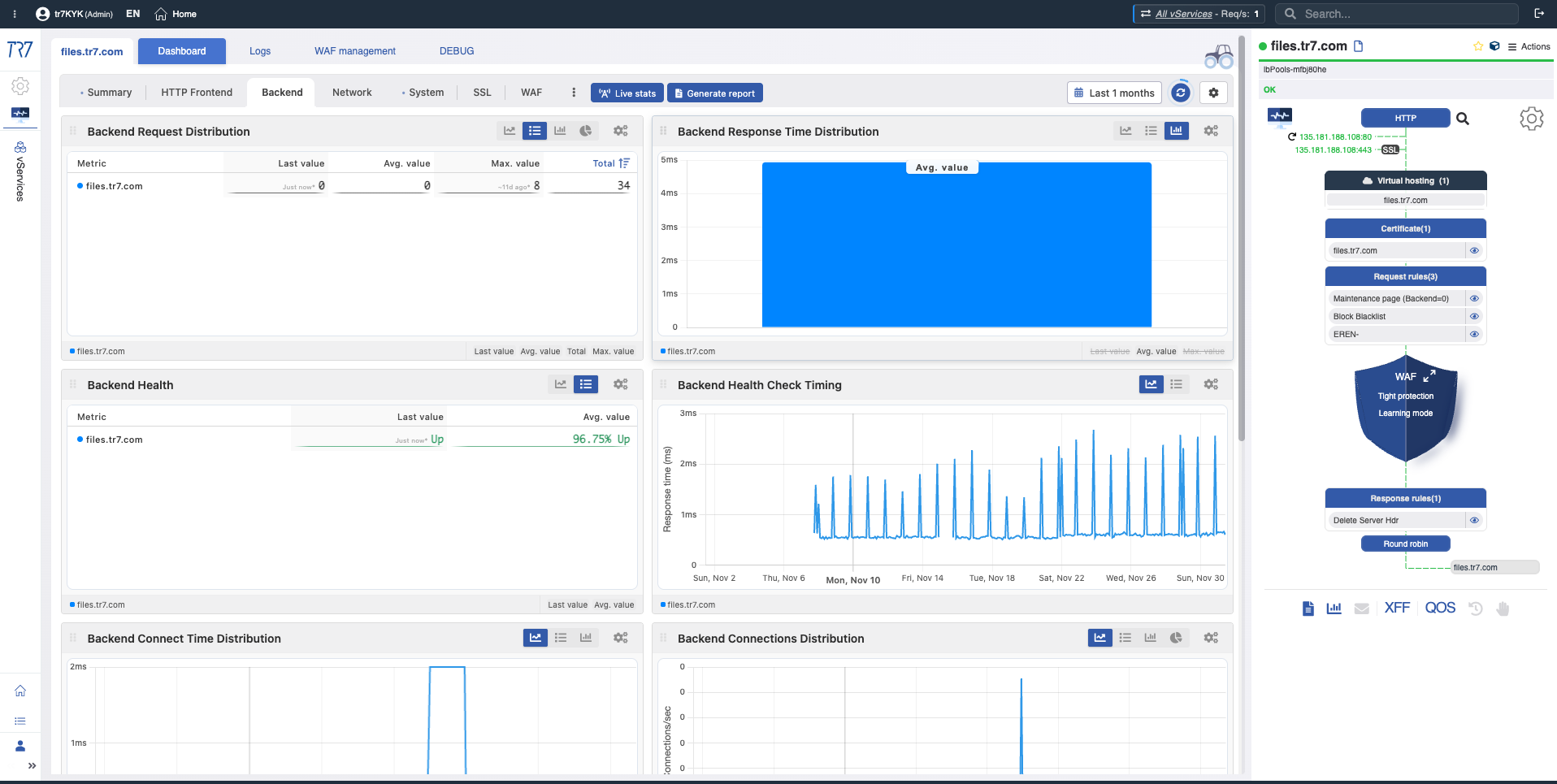
Distribución de Solicitudes de Backend
Backend Request Distribution
What?Muestra cómo se distribuyen las solicitudes entrantes entre los servidores backend.
Why important?Le permite detectar distribución de carga desbalanceada. Un backend recibiendo desproporcionadamente más o menos solicitudes puede indicar problemas de configuración o salud.
Distribución de Tiempo de Respuesta de Backend
Backend Response Time Distribution
What?Muestra el tiempo de respuesta promedio de cada servidor backend comparativamente.
Why important?Le permite identificar rápidamente backends lentos. Si el tiempo de respuesta de un backend es significativamente mayor que otros, puede haber un problema con ese servidor.
Salud del Backend
Backend Health
What?Muestra resultados de health-check y estado de salud para cada servidor backend.
Why important?Le permite ver instantáneamente qué backends están saludables, caídos o degradados.
Timing de Health Check de Backend
Health Check Timing
What?Muestra con qué frecuencia se ejecutan los health-checks y sus tiempos de respuesta.
Why important?Le permite detectar problemas de timing de health-check. Respuestas lentas de health-check pueden retrasar la detección de un backend problemático.
Distribución de Tiempo de Conexión de Backend
Connection Time Distribution
What?Muestra distribución de tiempo de establecimiento de conexión a backends.
Why important?Ayuda a detectar retrasos de red y problemas de conexión TCP. Alto tiempo de conexión indica problemas del lado de la red o backend.
Distribución de Conexiones de Backend
Connection Distribution
What?Muestra distribución de conexiones activas entre backends.
Why important?Le permite monitorear comportamiento de sesión sticky y balance de carga. Acumulación desproporcionada de conexiones en un backend puede causar problemas de rendimiento.
Distribución de Ancho de Banda IN de Backend
Bandwidth IN Distribution
What?Muestra distribución de ancho de banda del tráfico yendo a backends.
Why important?Le permite ver qué backends reciben cuánto tráfico. Un backend recibiendo tráfico excesivo puede convertirse en cuello de botella.
Distribución de Ancho de Banda OUT de Backend
Bandwidth OUT Distribution
What?Muestra distribución de ancho de banda del tráfico de respuesta desde backends.
Why important?Ayuda a entender tamaños de respuesta de backend y patrones de tráfico. Backends produciendo respuestas grandes afectan la planificación de ancho de banda.
Distribución de Sesiones de Backend
Session Distribution
What?Muestra distribución de sesiones activas entre backends.
Why important?Le permite monitorear comportamiento de persistencia de sesión y densidad de sesión por backend.
Distribución de Cola de Backend
Queue Distribution
What?Muestra estado de cola de solicitudes esperando ser enrutadas a backends.
Why important?La acumulación de cola es una señal temprana de capacidad insuficiente de backend. A medida que las colas se llenan, los tiempos de respuesta aumentan.
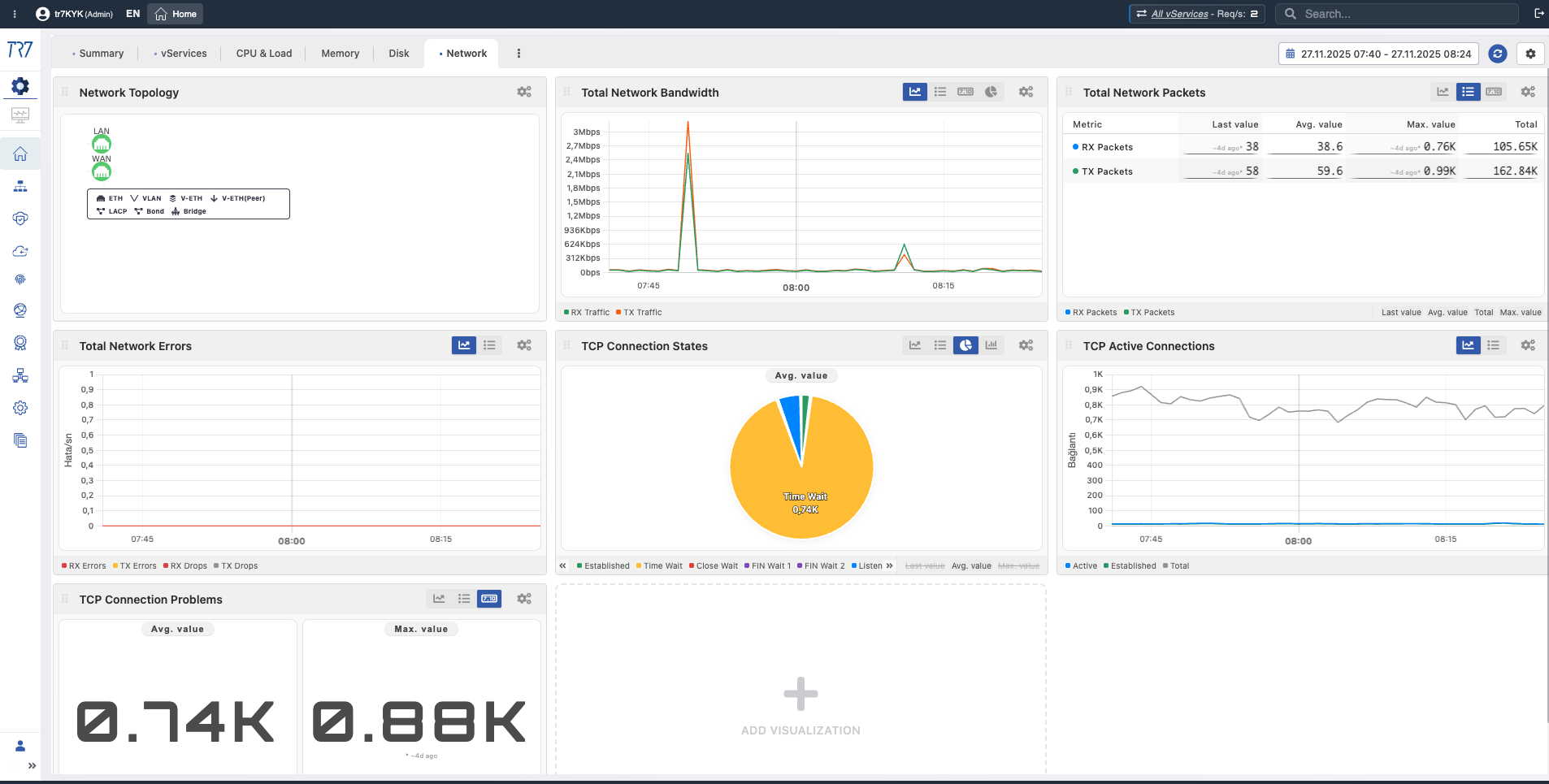
Ancho de Banda de Red - WAN
WAN Bandwidth
What?Muestra volumen total de tráfico pasando a través de la interfaz WAN.
Why important?Le permite ver qué tan cerca está de la capacidad del enlace. La saturación del enlace causa pérdida de paquetes y aumento de latencia.
Paquetes de Red - WAN
WAN Packets
What?Muestra paquetes procesados por segundo (PPS).
Why important?Anomalías de PPS pueden indicar ataques DDoS o problemas de red. Alto PPS con bajo ancho de banda indica flood de paquetes pequeños.
Estado de Red - WAN
WAN Status
What?Muestra estado operacional de interfaz de red (up/down) y calidad del enlace.
Why important?Le permite detectar instantáneamente cambios de estado del enlace. Caídas intermitentes del enlace causan problemas de conectividad.
Errores de Interfaz de Red
Interface Errors
What?Muestra errores ocurriendo en la interfaz (CRC, colisión, drop, etc.).
Why important?Errores de interfaz pueden indicar problemas de cable físico, discrepancias de MTU o fallas de hardware.
Unidades de Interfaz (WAN)
Interface Units
What?Muestra estado de sub-interfaces y VLANs.
Why important?Le permite monitorear el estado de cada sub-unidad separadamente en topologías de red complejas.
Uso de CPU del Dispositivo
Device CPUSystem CPU
What?Muestra porcentaje total de uso de CPU del dispositivo.
Why important?Alto uso de CPU afecta el rendimiento de todos los servicios. CPU consistentemente alta requiere aumento de capacidad u optimización.
Temperatura de CPU del Dispositivo
CPU Temperature
What?Muestra temperatura operacional de la CPU.
Why important?Alta temperatura puede causar thermal throttling y degradación de rendimiento. Temperatura excesiva aumenta el riesgo de falla de hardware.
Uptime del Sistema
System Uptime
What?Muestra tiempo transcurrido desde que el dispositivo fue iniciado por última vez.
Why important?Le permite detectar reinicios inesperados. Si el uptime se reinició, investigue por qué el dispositivo se reinició.
Carga del Sistema
System LoadLoad Average
What?Muestra promedios de carga del sistema de 1, 5 y 15 minutos.
Why important?Ayuda a entender qué tan ocupado está el sistema. Si el promedio de carga excede consistentemente el conteo de CPU, el sistema está sobrecargado.
Uso Total de Memoria
Total Memory Usage
What?Muestra cantidad total de memoria usada por el sistema.
Why important?Le permite rastrear consumo de memoria a lo largo del tiempo. Uso de memoria en constante aumento puede indicar una fuga de memoria.
Memoria Disponible
Available Memory
What?Muestra cantidad de memoria disponible para nuevos procesos.
Why important?Baja memoria disponible puede prevenir que nuevas conexiones y procesos se inicien.
Ratio de Uso de Memoria
Memory Usage %
What?Muestra qué porcentaje de memoria total se usa.
Why important?Se usa para planificación de capacidad y alertas basadas en umbrales. Uso por encima del 90% es nivel crítico.
Uso de Swap
Swap Usage
What?Muestra uso de espacio swap en disco.
Why important?Uso de swap indica que la memoria física es insuficiente. Uso activo de swap causa degradación significativa de rendimiento.
Uso de Disco
Disk Usage
What?Muestra cantidad de espacio en disco usado.
Why important?Le permite monitorear la tasa de llenado del disco. Si el disco se llena, la escritura de logs puede detenerse y el sistema puede volverse inestable.
Capacidad de Disco
Disk Capacity
What?Muestra capacidad total del disco.
Why important?Punto de referencia para planificación de capacidad y análisis de tendencia de crecimiento.
Ratio de Uso de Disco
Disk Usage %
What?Muestra qué porcentaje de capacidad del disco se usa.
Why important?Por encima del 90% es advertencia, por encima del 95% es nivel crítico. Disco lleno requiere planificación de rotación y archivado de logs.
Uso de Inodes de Disco
Inode Usage
What?Muestra uso de inodes del sistema de archivos.
Why important?Incluso con espacio libre en disco, si los inodes se agotan, no se pueden crear nuevos archivos. Crítico para sistemas con muchos archivos pequeños.
I/O de Lectura de Disco
Disk Read I/O
What?Muestra operaciones de lectura de disco por segundo y velocidad.
Why important?Alto I/O de lectura puede indicar cuello de botella de disco. Especialmente importante para sistemas sin SSD.
I/O de Escritura de Disco
Disk Write I/O
What?Muestra operaciones de escritura de disco por segundo y velocidad.
Why important?La escritura de logs y auditoría genera constantemente I/O de disco. Si la velocidad de escritura cae, hay riesgo de pérdida de logs.
Latencia de I/O de Disco
I/O Latency
What?Muestra tiempo promedio de finalización para operaciones de disco.
Why important?Alta latencia de I/O es una señal temprana de degradación de rendimiento del disco. Aumento de latencia afecta el rendimiento general del sistema.
Conteo de Conexiones TCP
TCP Connections
What?Muestra conteo total de conexiones TCP en el sistema.
Why important?Le permite ver si se está aproximando a límites de conexión. Si se excede el límite de conexión, nuevas conexiones son rechazadas.
TCP Establecidas
Established Connections
What?Muestra conteo de conexiones transfiriendo datos activamente.
Why important?Indicador de carga de trabajo real. El conteo de conexiones establecidas se relaciona directamente con la capacidad.
TCP TIME_WAIT
TIME_WAIT
What?Muestra conteo de conexiones esperando en estado TIME_WAIT.
Why important?Alto conteo de TIME_WAIT indica riesgo de agotamiento de puertos. Conexiones de corta duración y tráfico pesado causan acumulación de TIME_WAIT.
TCP CLOSE_WAIT
CLOSE_WAIT
What?Muestra conteo de conexiones esperando en estado CLOSE_WAIT.
Why important?Alto conteo de CLOSE_WAIT indica que la aplicación no está cerrando correctamente las conexiones. Esto es usualmente un bug del lado de la aplicación.
Retransmisión TCP
Retransmissions
What?Muestra conteo de retransmisión de paquetes TCP.
Why important?Aumento de retransmisión indica problemas de calidad de red, pérdida de paquetes o congestión. Alta tasa de retransmisión causa aumento de latencia y caída de throughput.
Solicitudes Totales de vService
Total vService Requests
What?Muestra conteo total de solicitudes para todos los vServices en un gráfico.
Why important?Le permite entender volumen total de tráfico y tendencias en todo el dispositivo. Referencia fundamental para planificación de capacidad y evaluación de carga general.
Conexiones Totales de vService
Total vService Connections
What?Muestra conteo total de conexiones activas para todos los vServices.
Why important?Le permite monitorear presión de conexión y uso de tabla de conexiones en todo el dispositivo. Aproximarse a límites de tabla de conexiones puede causar que nuevas conexiones sean rechazadas.
Integraciones: disponibles, pero la investigación no depende de ellas
TR7 puede integrarse con el ecosistema de monitoreo y gestión de logs de su organización. La diferencia crítica: la investigación de incidentes no depende únicamente de pipelines externos. Los sistemas externos agregan valor; los registros en el appliance sirven como referencia fundamental.
Preguntas Frecuentes
El objetivo es tener datos requeridos para investigación siempre listos en el appliance. La exportación externa y el archivado centralizado son soportados. Sin embargo, el éxito de la investigación no depende únicamente de la configuración de exportación.
El objetivo no es mirar todo todo el tiempo. Las categorías, búsqueda y filtrado le permiten llegar rápidamente a la señal correcta cuando se necesita.
El objetivo de la Consola Web no es acceso sin restricciones sino diagnósticos controlados. Cuando se usa con autorización adecuada y runbooks, acorta el tiempo de investigación.
Es en tiempo real. Los estados de servicio se monitorean en runtime y los cambios se reflejan inmediatamente como cambios de color. Además, se retienen métricas retrospectivas y registros de eventos.
El debug normal típicamente captura todo el tráfico y requiere filtrar después. El debug dirigido captura registros solo para host, puerto, path o header específicos desde el inicio. Esto reduce el ruido, acelera la investigación y minimiza el impacto en producción.
TR7 soporta exportación a Prometheus y reenvío de logs a SIEM. Las integraciones retienen su valor. La diferencia: los datos requeridos para investigación no dependen únicamente de sistemas externos—también están listos en el appliance.
El período de retención es configurable. Lo que importa es que las acciones de usuario y cambios de configuración se mantienen en la misma línea de tiempo que las métricas y registros de eventos.
El detalle es preparación, no complejidad. Incluso en equipos pequeños, llegar rápidamente a los datos correctos durante un incidente ahorra tiempo. La estructura categorizada y las funciones de búsqueda facilitan enfocarse solo en los datos necesarios.
Conclusión
La afirmación de TR7 no es 'más gráficos'—es hacer que la capa ADC/WAF esté lista para investigación. Métricas de vService/backend/interfaz, registros de eventos/notificaciones, rastro de auditoría y visibilidad HTTP/WAF se combinan en una sola línea de tiempo; el análisis forense retroactivo y el debug dirigido aceleran el análisis de causa raíz.
Las integraciones de exportación son valiosas; pero para minimizar el riesgo de 'no se envió, así que no existe' durante momentos críticos, la cadena de evidencia debe permanecer accesible dentro del producto en todo momento.
Estas y capacidades similares—detalles que no aparecen en hojas de especificaciones, son difíciles de captar en demos, pero definen la calidad operacional en la práctica—son la razón principal por la que casi todas las organizaciones que evalúan TR7 deciden hacer el cambio.