Enviar telemetria não é suficiente: ADC pronto para investigação, Forensics retroativa e cadeia de evidências
Métricas no appliance + registros de eventos + auditoria + visibilidade de tráfego para investigação retroativa e análise rápida da causa raiz
CategoriaOperações e observabilidade
PublicadoDecember 1, 2025
Tempo de leitura14 min
AutorTR7 Engineering Team
Tópicos
ADCWAFObservabilidadeForensicsAuditoriaDebugVisibilidade em runtime
Introdução
Quando a produção falha, três perguntas importam: O que aconteceu? Quando aconteceu? Por que aconteceu?
Na prática, as respostas estão frequentemente dispersas — métricas em um lugar, logs de tráfego em outro e histórico de alterações em outro lugar.
Há outra realidade: exportações para sistemas externos são tipicamente seletivas. Se o sinal de que você precisa durante um incidente nunca foi selecionado para exportação, você não o terá.
A abordagem do TR7 é clara: integrações de exportação importam, mas a investigação não deve depender apenas delas. É por isso que o TR7 mantém sinais críticos no appliance, alinhados em uma única linha do tempo.
Um sinal que não é capturado é um risco que permanece invisível.
Por que apenas exportação não é suficiente?
Plataformas SIEM, servidores de log e Prometheus/Grafana são valiosos para visibilidade empresarial. No entanto, o sucesso da investigação depende de ter os dados certos disponíveis quando você precisa deles.
A coleta seletiva é inevitável
Custo e ruído significam que nem toda métrica/log é exportado. Quando um incidente ocorre, o sinal crítico pode estar faltando.
A correlação fica mais difícil à medida que os dados se dispersam
Quando métricas, eventos, auditoria e logs de tráfego estão em lugares diferentes, construir uma única linha do tempo leva mais tempo.
O pipeline é outra área de risco
Problemas de agente, rede, cota/limite ou indexação podem causar perda de dados — especialmente durante incidentes.
Pronto para investigação
Gaste tempo resolvendo, não coletando dados. O TR7 mantém sinais críticos prontos no appliance.
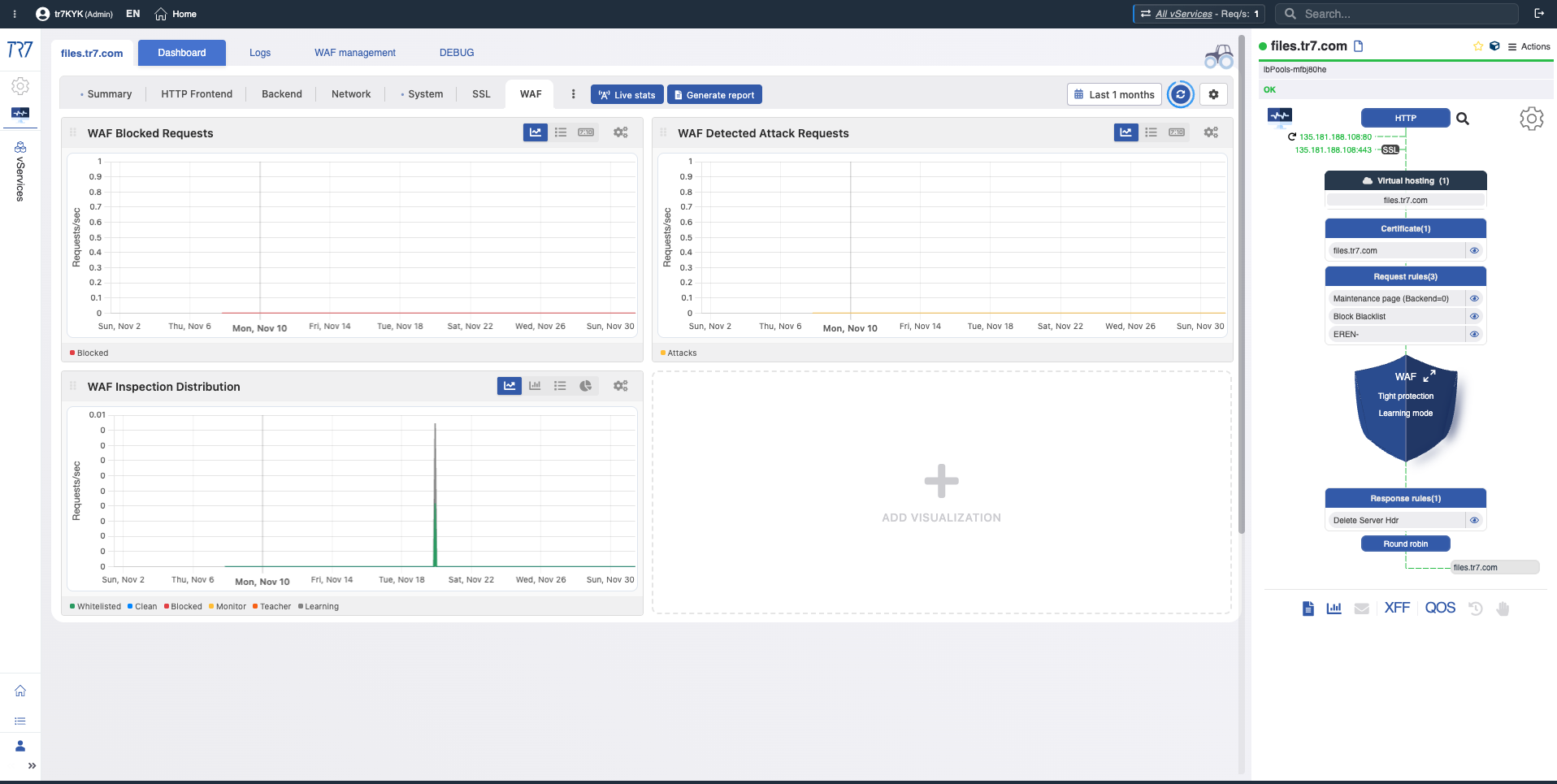
Dynamic Flow Panel: visibilidade em runtime e ponto de partida rápido
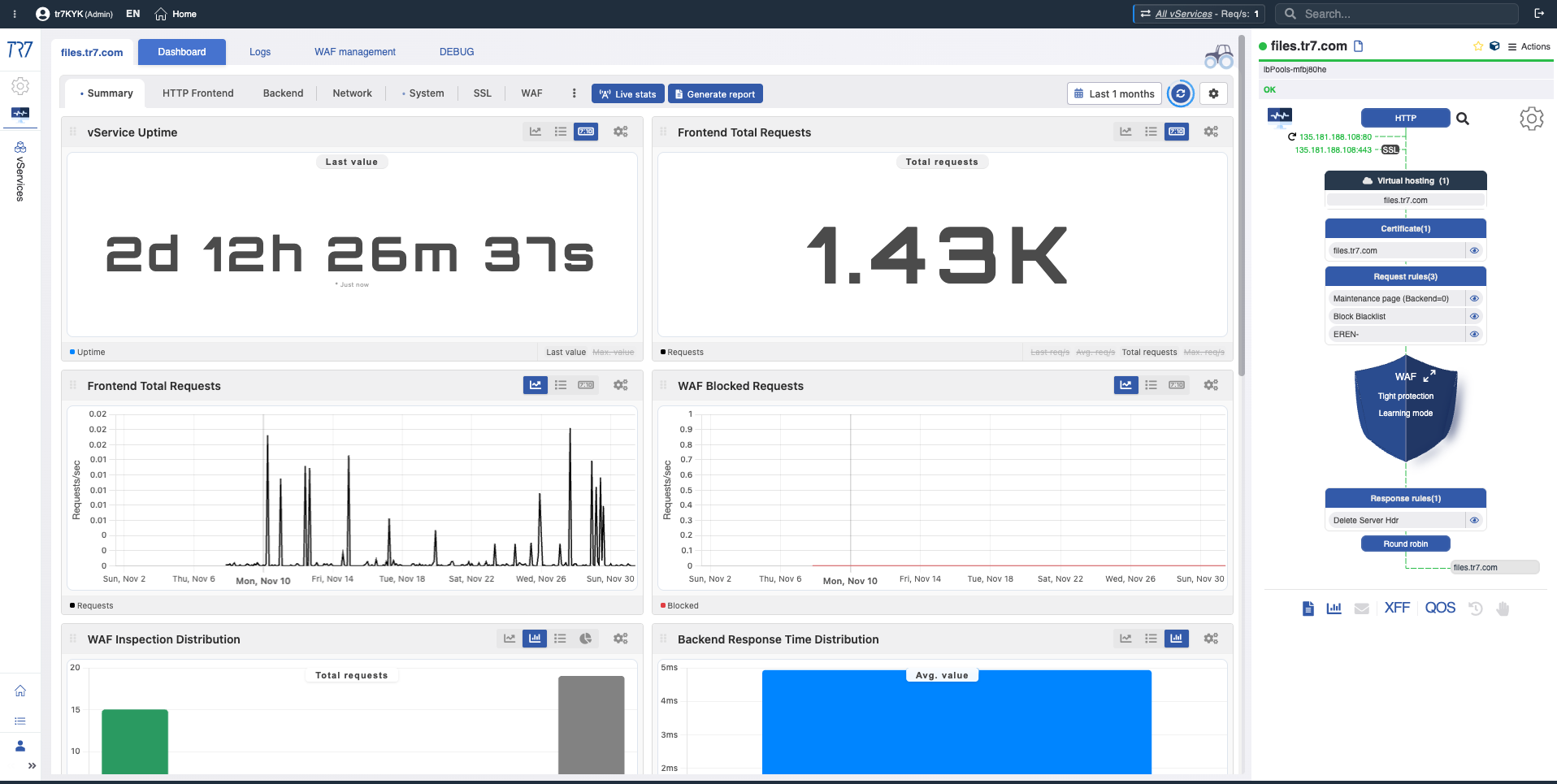
Na interface do TR7, a topologia do serviço pode ser monitorada ao vivo (runtime) através do Dynamic Flow Panel. Controle completo →
O painel exibe o status do serviço com cores. Por exemplo, se o link de interface que serve o IP de um vService cair, o sistema gera um alerta e o nome do serviço muda de verde para amarelo.
Isso permite que os operadores vejam imediatamente o que investigar. A triagem começa mais rápido e o tempo de investigação diminui.
Cores de status
As cores no Flow Panel ajudam você a ler rapidamente o status do serviço:
Verde: Normal
As conexões de serviço e verificações de saúde estão funcionando conforme esperado.
Todos os backends saudáveis
Links de interface ativos
Verificações de saúde passando
Monitoramento de rotina
Amarelo: Atenção
Há uma condição que precisa de monitoramento.
Link de interface inativo (serviço ainda pode funcionar)
Uma verificação de saúde de backend falhou
Aproximando-se do limite de recursos
Verificação rápida via métricas + notificação + auditoria
Vermelho: Crítico
Há um problema afetando o serviço.
Backends inativos
vService inacessível
Erro de configuração crítico
Triagem rápida: métrica + evento + auditoria
Exemplos de cenários de investigação
Os exemplos a seguir mostram como uma investigação típica progride no TR7.
Cenário A: Aumento de latência
Reclamação: 'A aplicação está lenta'
Verificar tendência do tempo de resposta do vService → Há picos?
Verificar distribuição do tempo de resposta do backend → Qual backend está lento?
Verificar com verificações de saúde e distribuições de conexão
Há alertas de recursos nos logs de notificação durante o mesmo período?
Trilha de auditoria: Houve alterações recentes?
Resultado: Camada LB ou backend específico — rapidamente esclarecido
Cenário B: Aumento de bloqueios WAF
Reclamação: 'Envios de formulário falhando'
Verificar métrica de bloqueio WAF → Há picos?
Encontrar regra acionada nos logs HTTP/WAF
Determinar a partir dos detalhes da requisição: falso positivo ou ataque real?
Trilha de auditoria: Houve alterações de regra/política?
Usar debug direcionado se necessário para inspecionar apenas tráfego relevante
Resultado: Ajuste de regra ou ação de segurança — decidir com dados
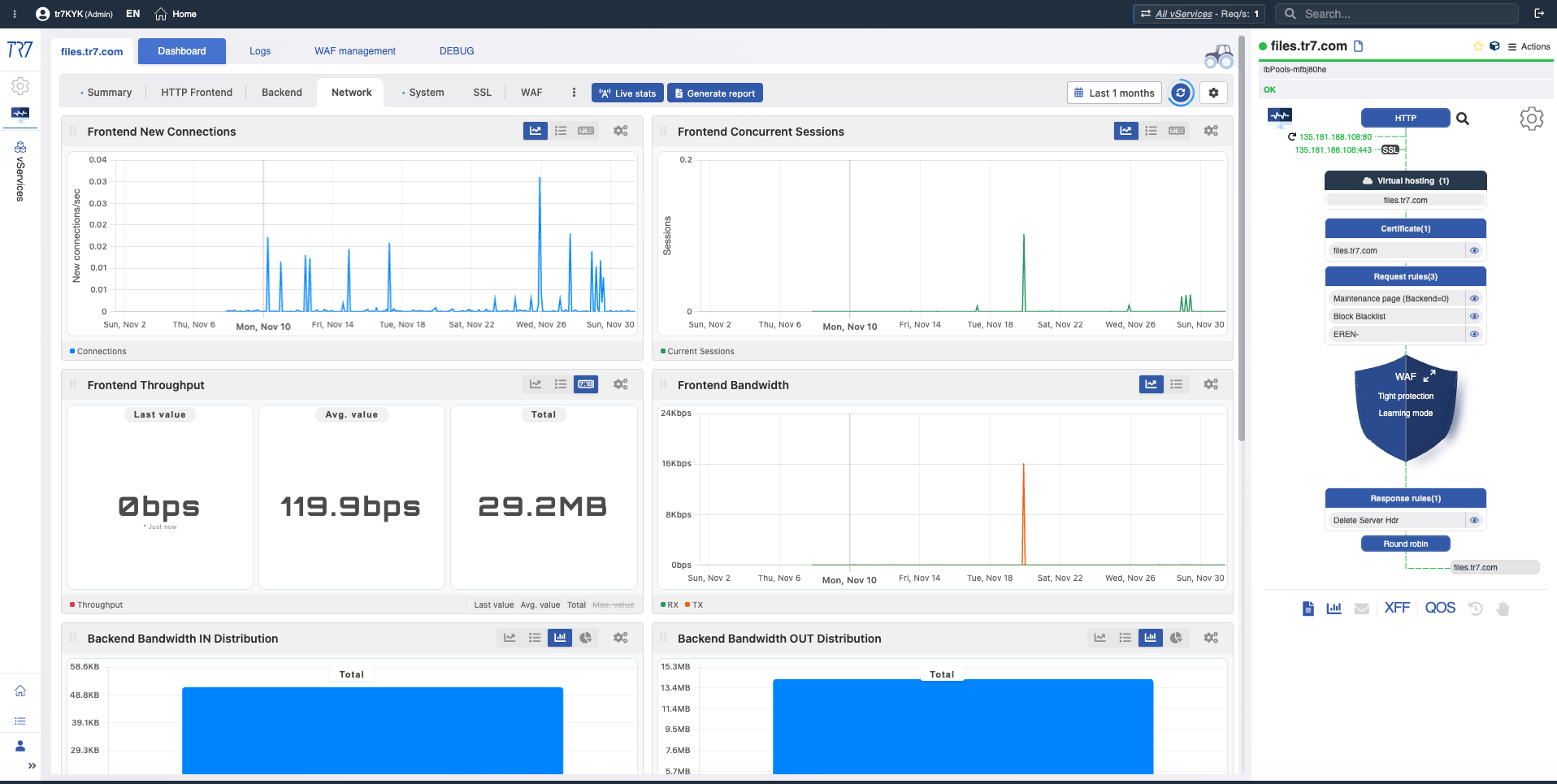
Visão geral do dispositivo: ponto de partida da investigação
A investigação de incidentes sempre começa com a visão geral do dispositivo. CPU, memória, uso de disco e saúde do sistema — avalie o estado geral do dispositivo rapidamente. A seleção de intervalo de tempo permite forensics retroativa.
Resumo do sistema: Tempo de atividade, total de requisições, carga da CPU, memória, largura de banda — avaliar rapidamente o estado do dispositivo durante um incidente.
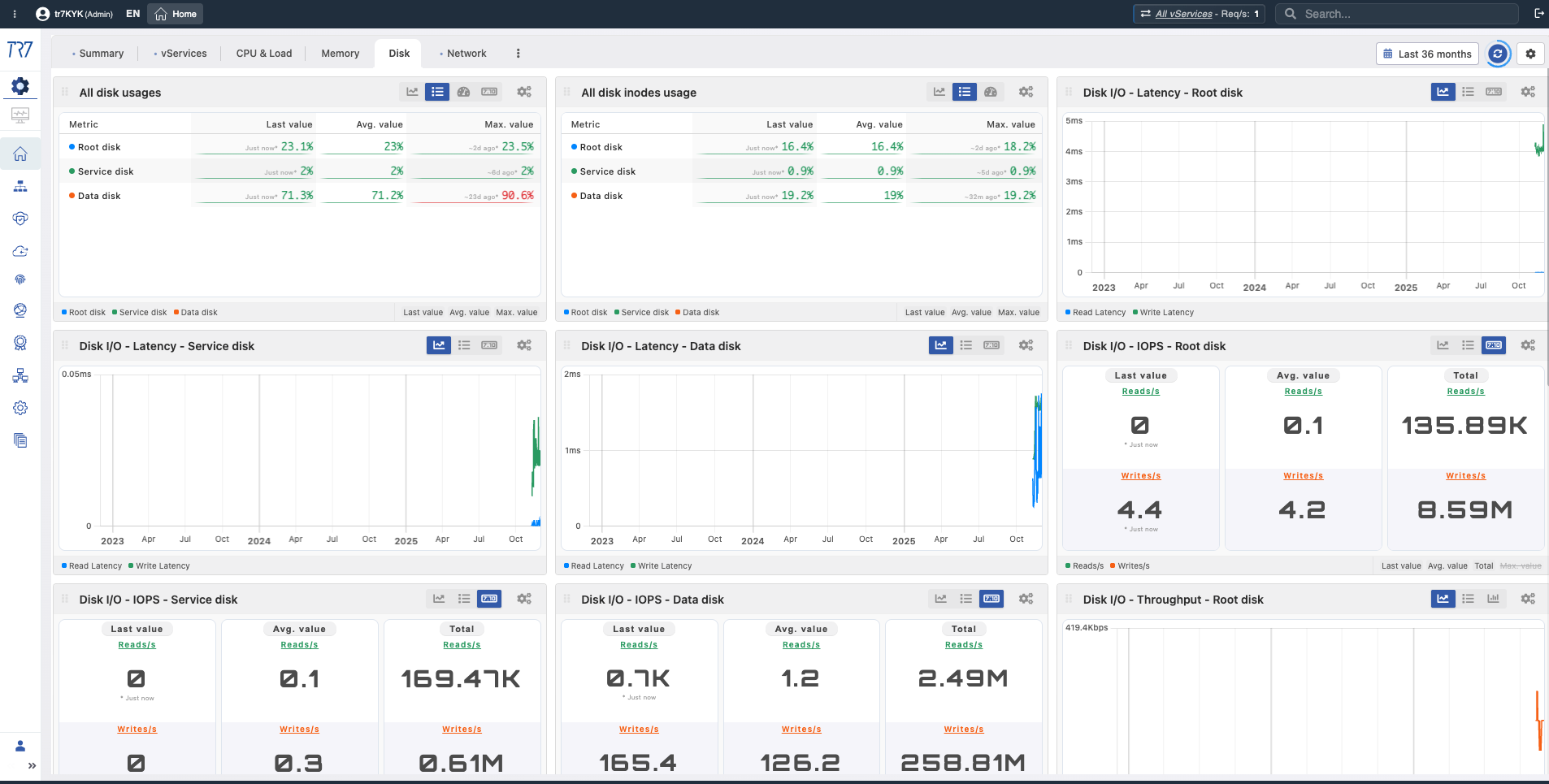
Disco e E/S: Uso, inode, latência, IOPS — a gravação de log ou desempenho de cache está afetado?
Serviço e backend: métricas de desempenho e saúde
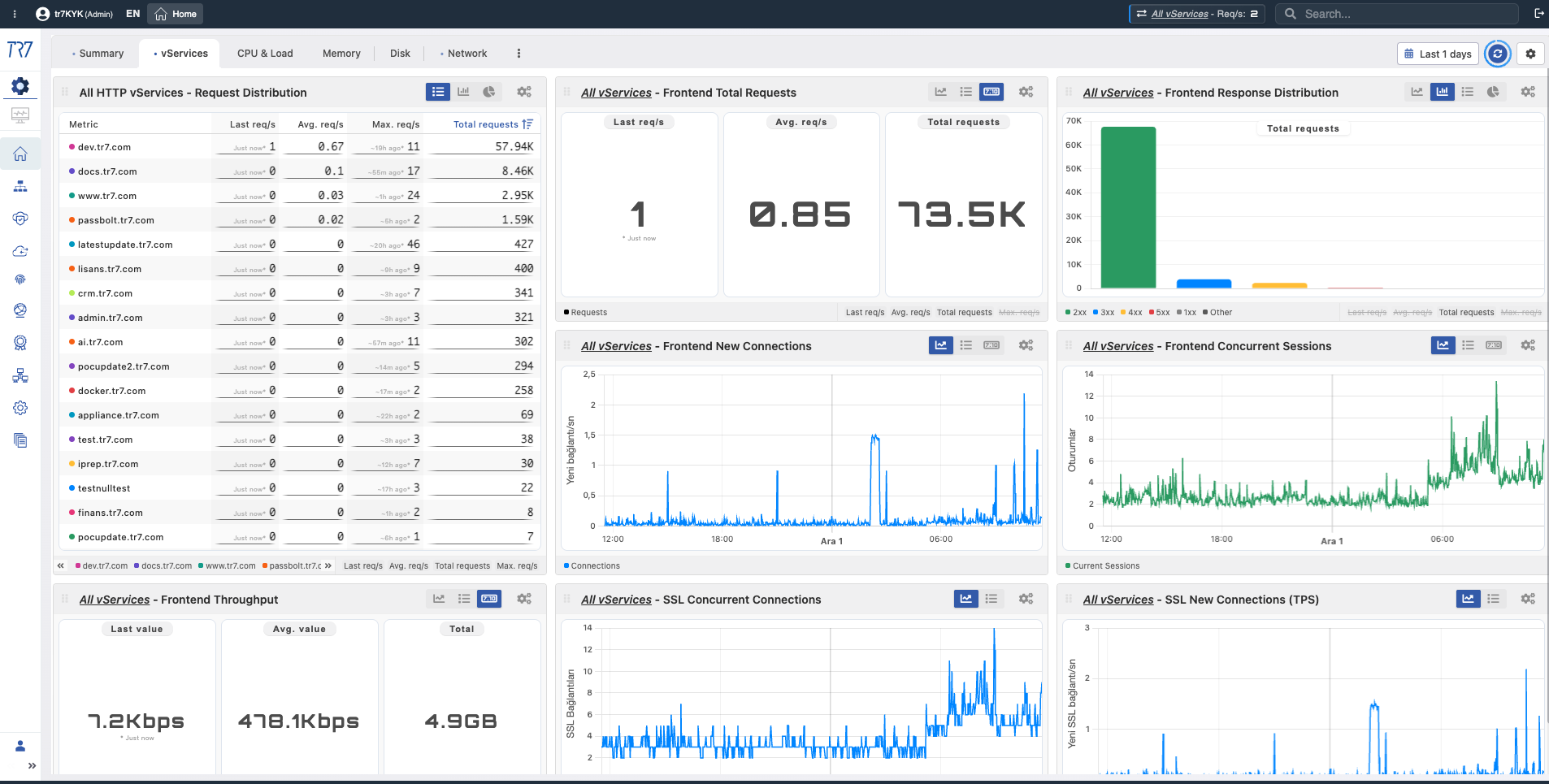
Após a visão geral do sistema, aprofunde-se na camada de serviço. Distribuição de requisições de todos os vServices, códigos de resposta, saúde do backend e topologia de serviço via Dynamic Flow Panel — tudo de relance. Cada vService tem seu próprio painel.
Visão geral vService: Distribuição de requisições e códigos de resposta (2xx/3xx/4xx/5xx) em todos os serviços — qual serviço tem anomalias?
Resumo vService: Tempo de atividade, requisições frontend, contagem de bloqueios WAF e Dynamic Flow Panel — estado atual do serviço.
Métricas personalizáveis: Reutilização SSL, compressão, taxa de acerto de cache — adicionar métricas necessárias para investigação.
Distribuições de backend: Qual backend está lento? Qual recebe mais requisições? Métricas de tempo de resposta e conexão.
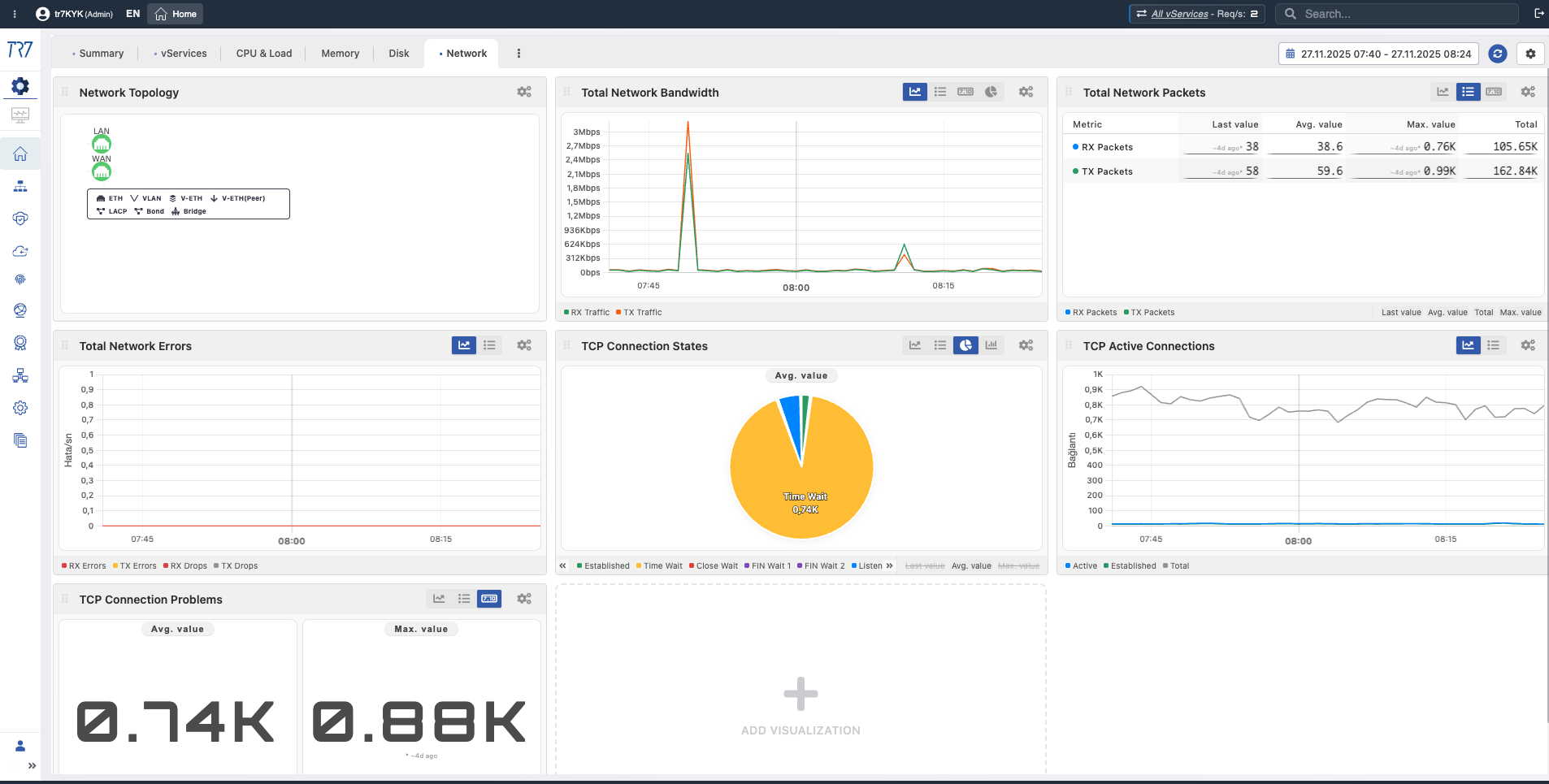
Rede e interface: status de conexão e fluxo de tráfego
O problema está no serviço ou na rede? Topologia, largura de banda, distribuição de estado TCP e métricas de interface respondem a essa pergunta. Mudanças no status do link e erros de pacote revelam rapidamente problemas na camada de rede.
Topologia de rede: Largura de banda, distribuição de estado TCP — primeira pista para separar problemas de serviço e rede.
Métricas de interface: Largura de banda RX/TX, contagens de pacotes, erros — desempenho e saúde do link.
Rede vService: Taxa de transferência e estados de conexão por serviço — o padrão de tráfego está normal?
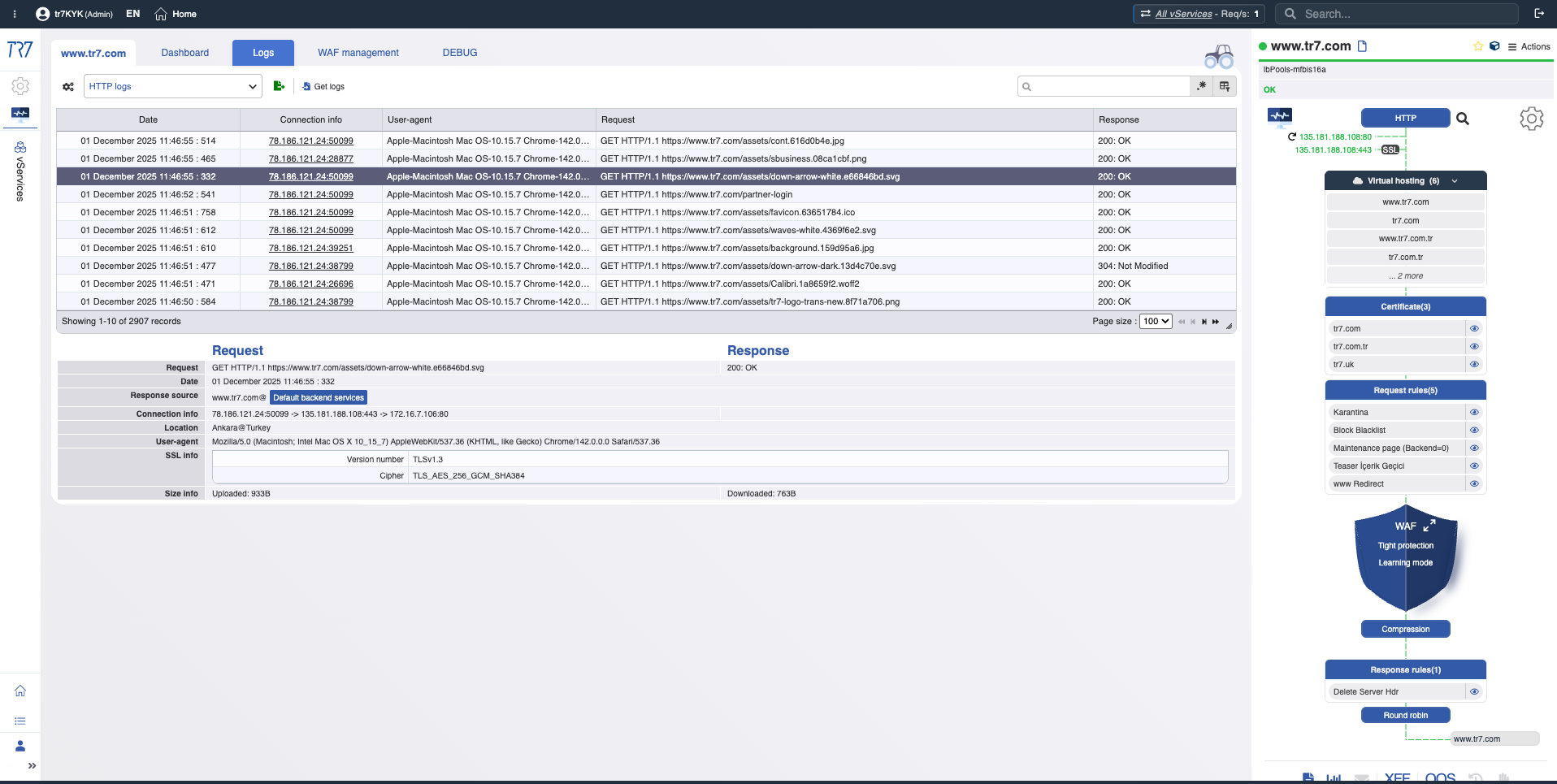
Logs HTTP e WAF: investigação no nível de requisição
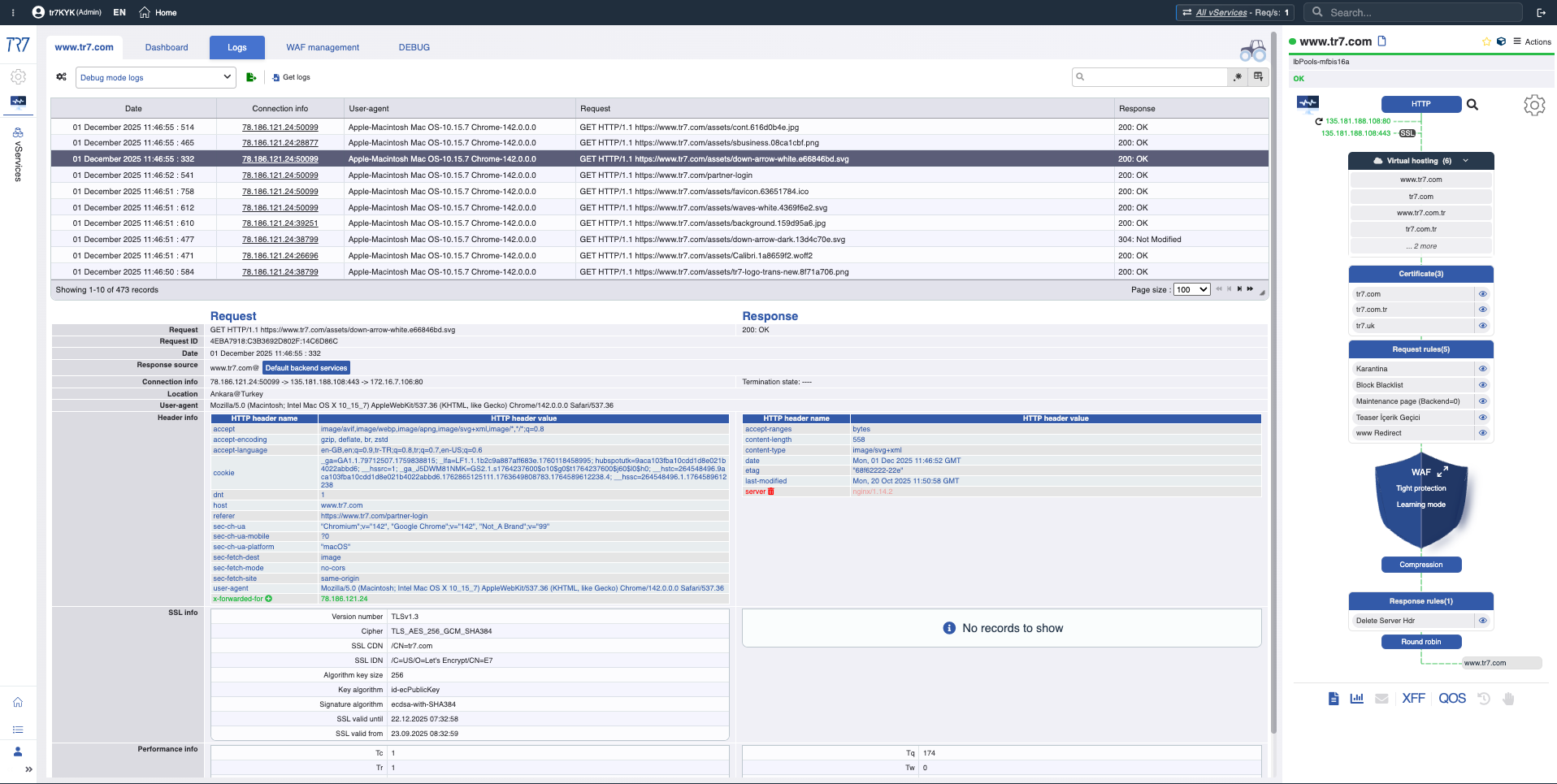
O tráfego HTTP e eventos WAF são visíveis sem ativar o debug. Quando necessário, o debug direcionado captura detalhes completos apenas para host/path/header específico. Forensics no nível de requisição sem impactar a produção.
Logs HTTP: IP de origem, destino, código de resposta, tamanho, duração — visibilidade básica mesmo com debug desativado.
Debug direcionado: Cabeçalhos e cookies completos apenas para tráfego relevante — detalhes sem impactar a produção.
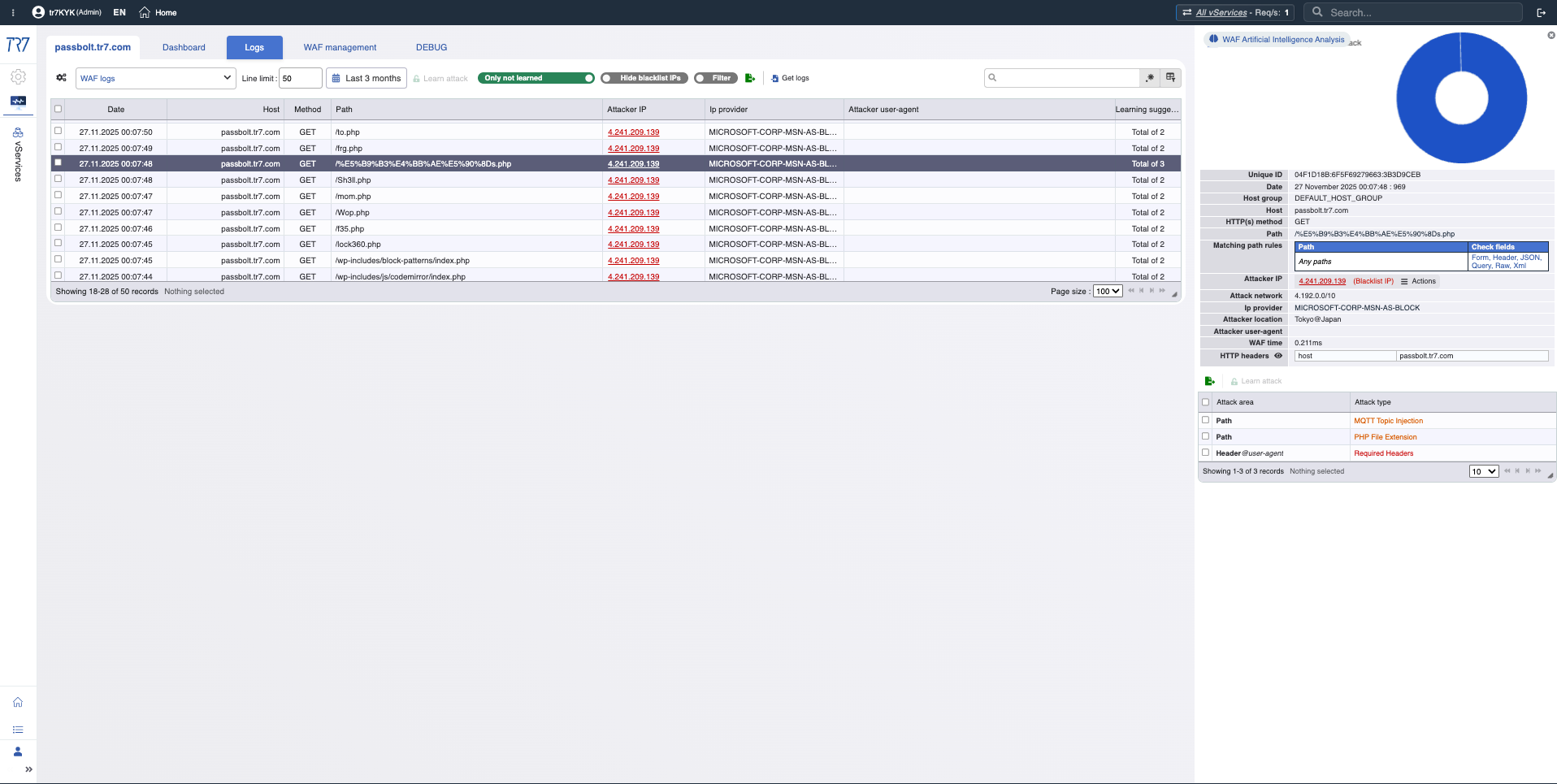
Logs WAF: Regra acionada, detalhes de requisição, análise alimentada por IA — dados para avaliação de falso positivo.
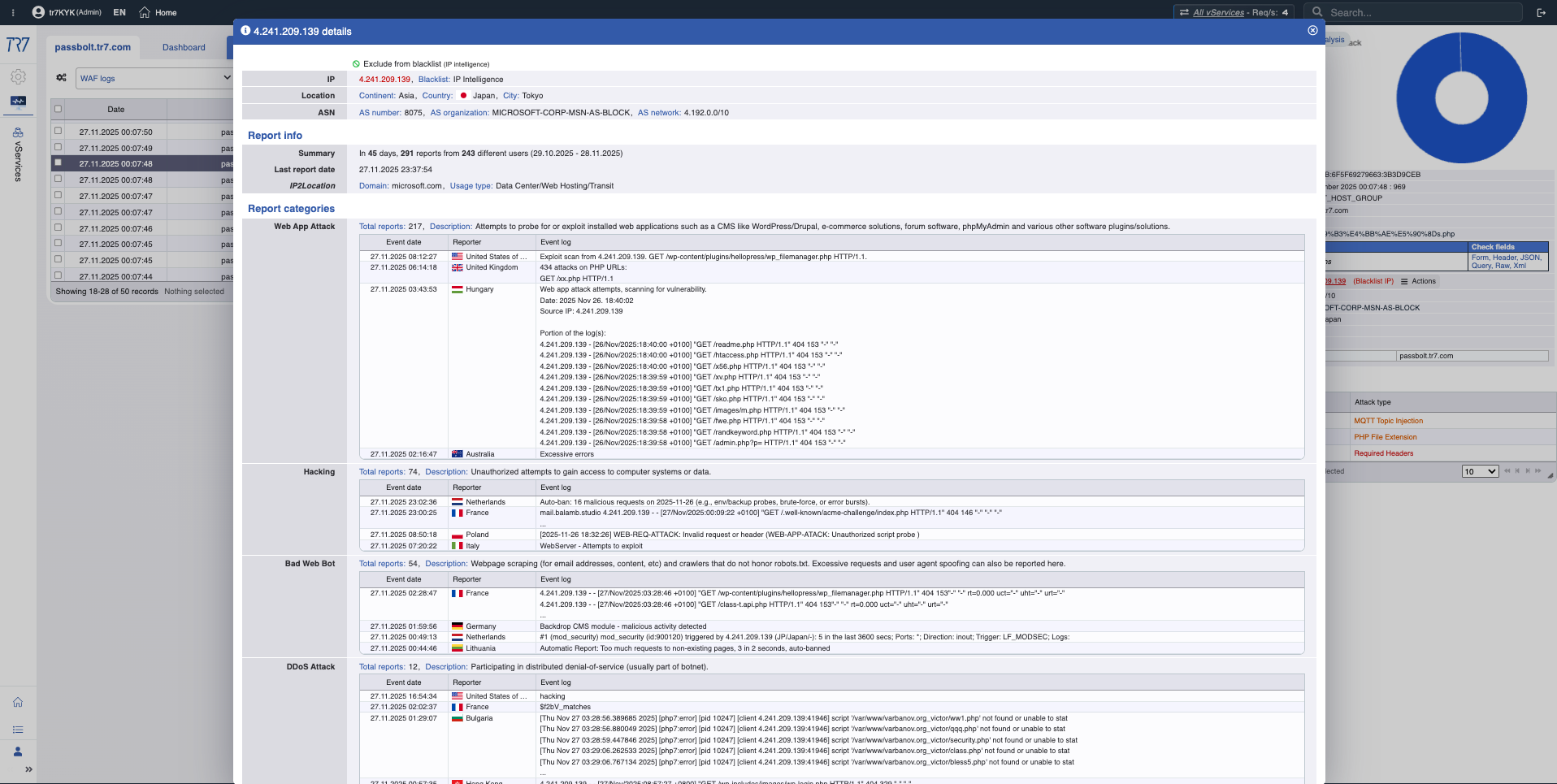
Inteligência de IP e WAF: perfil de ameaça
Pontuações de reputação de IP e métricas WAF revelam rapidamente o perfil do atacante. A primeira resposta para 'falso positivo ou ataque real?' está aqui. Categorias de ameaça (botnet, proxy, VPN, Tor) mostram a natureza do IP de origem.
Inteligência de IP: Pontuação de reputação, categorias de ameaça — o perfil do atacante fica rapidamente claro.
Métricas WAF: Tendência de bloqueio, distribuição de inspeção — visão geral de eventos de segurança.
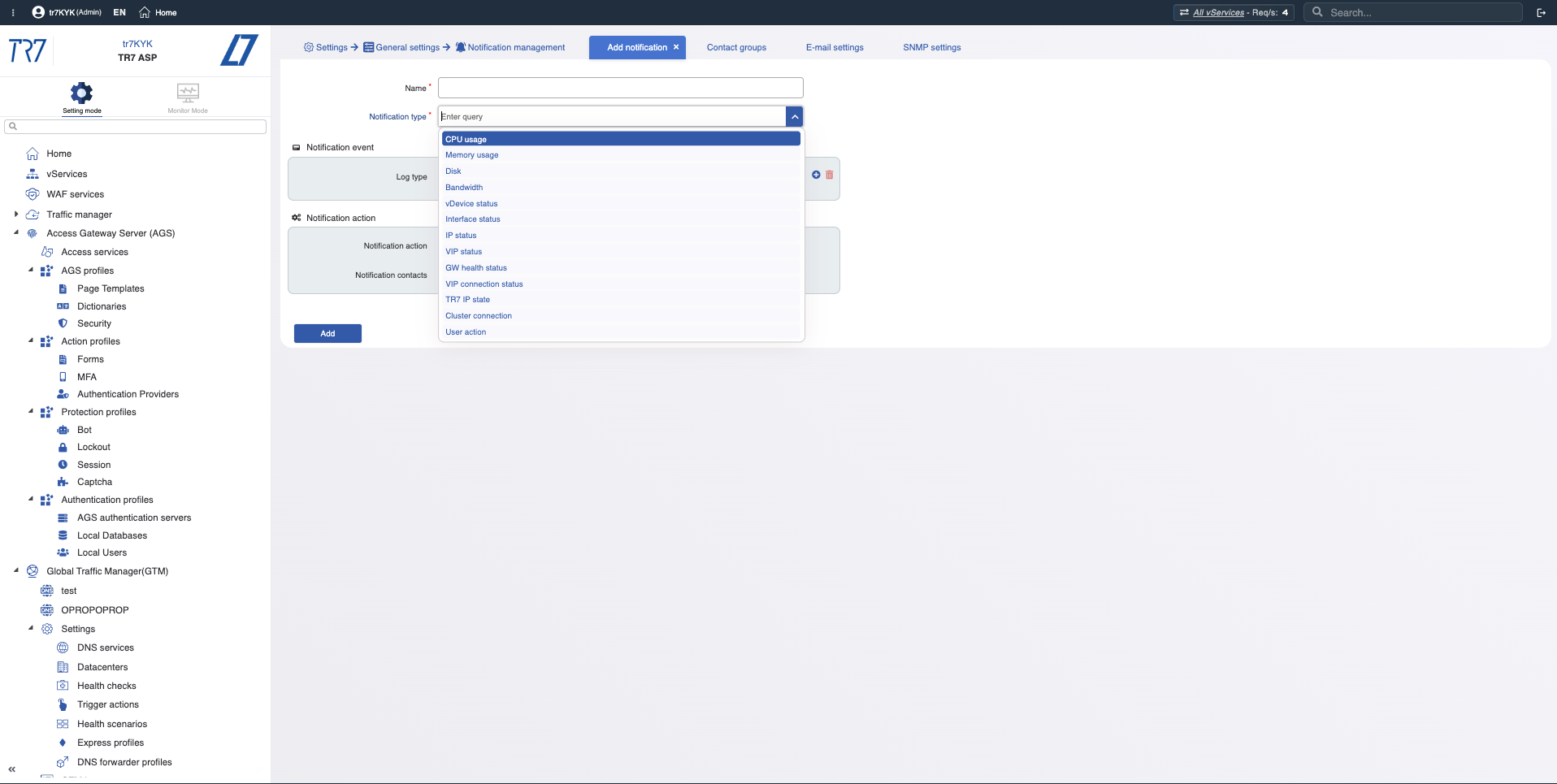
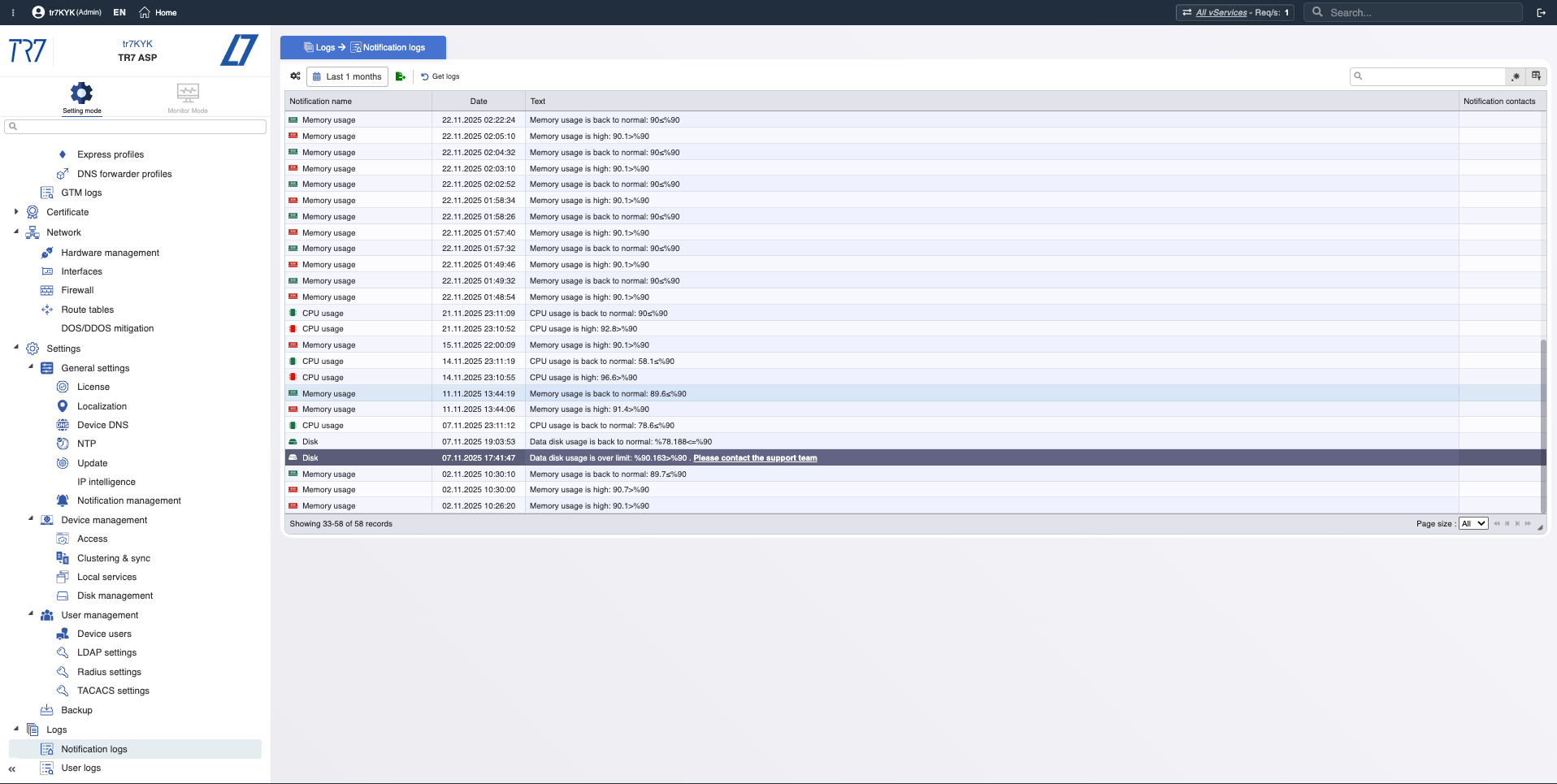
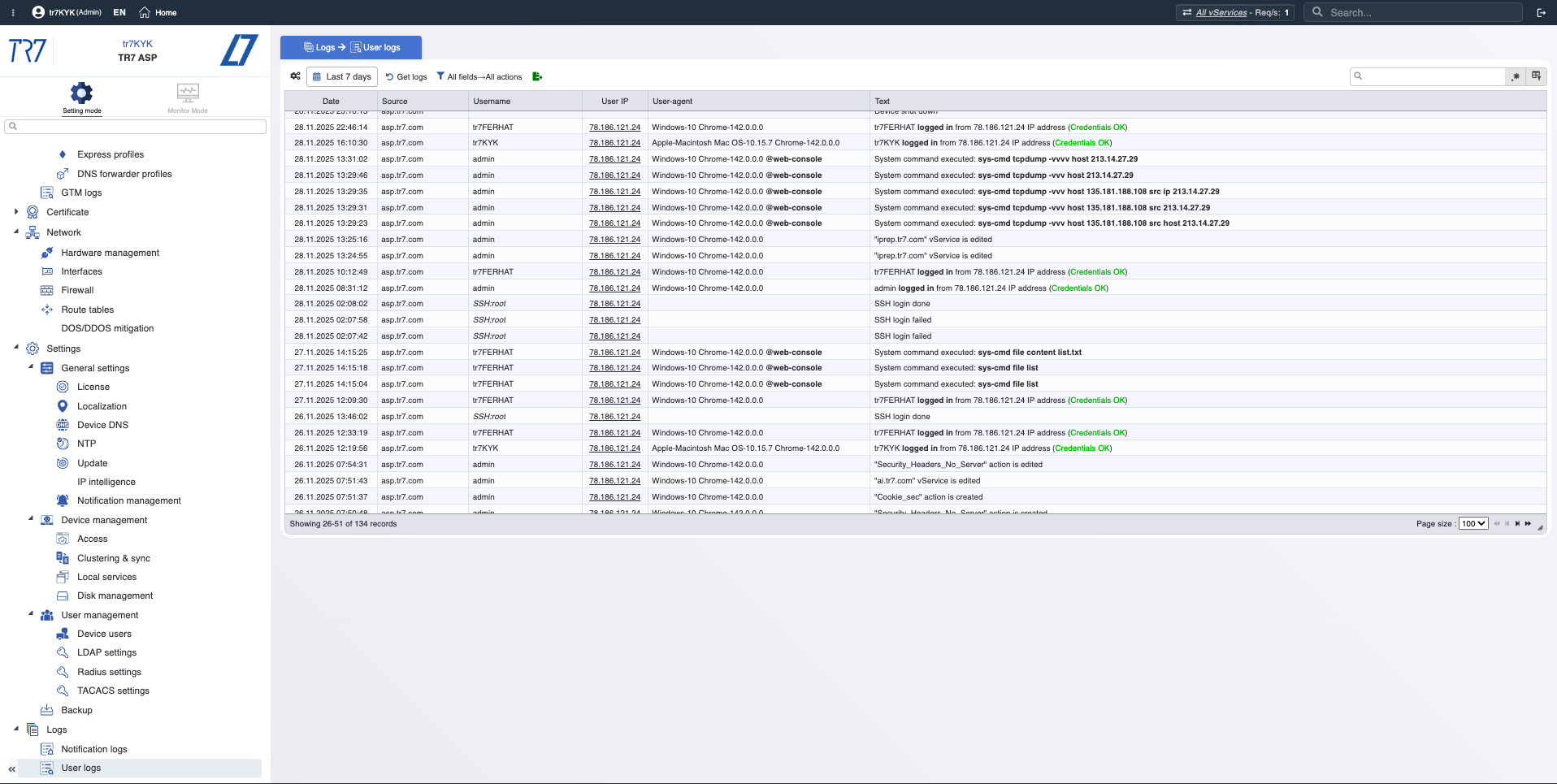
Linha do tempo de eventos: notificações e trilha de auditoria
Apenas métricas não são suficientes. Quais alertas dispararam? Quem mudou o quê e quando? Na investigação de incidentes, 'qual mudança afetou o quê?' é crítico. O TR7 mantém registros de notificação/evento e trilha de auditoria juntos, acelerando essa correlação.
Tipos de notificação: CPU, memória, disco, largura de banda, status do serviço — quais eventos estão sendo monitorados?
Histórico de notificações: Cronologia de alertas acionados — quais avisos vieram durante o incidente?
Trilha de auditoria: Quem mudou o quê, quando? Evidência para correlacionar rapidamente incidentes com mudanças.
Console Web: verificar a hipótese
As métricas fornecem uma hipótese; às vezes comandos são necessários para verificação. Execute ping, traceroute, curl, tcpdump do Console Web. Não é necessário SSH — os resultados aparecem na mesma tela.
Console Web: Comandos de diagnóstico da interface web — conectividade de backend, DNS, verificação de rota feita rapidamente.
Saída de comando: Resultados exibidos instantaneamente — exemplo de captura de tráfego direcionado com tcpdump.
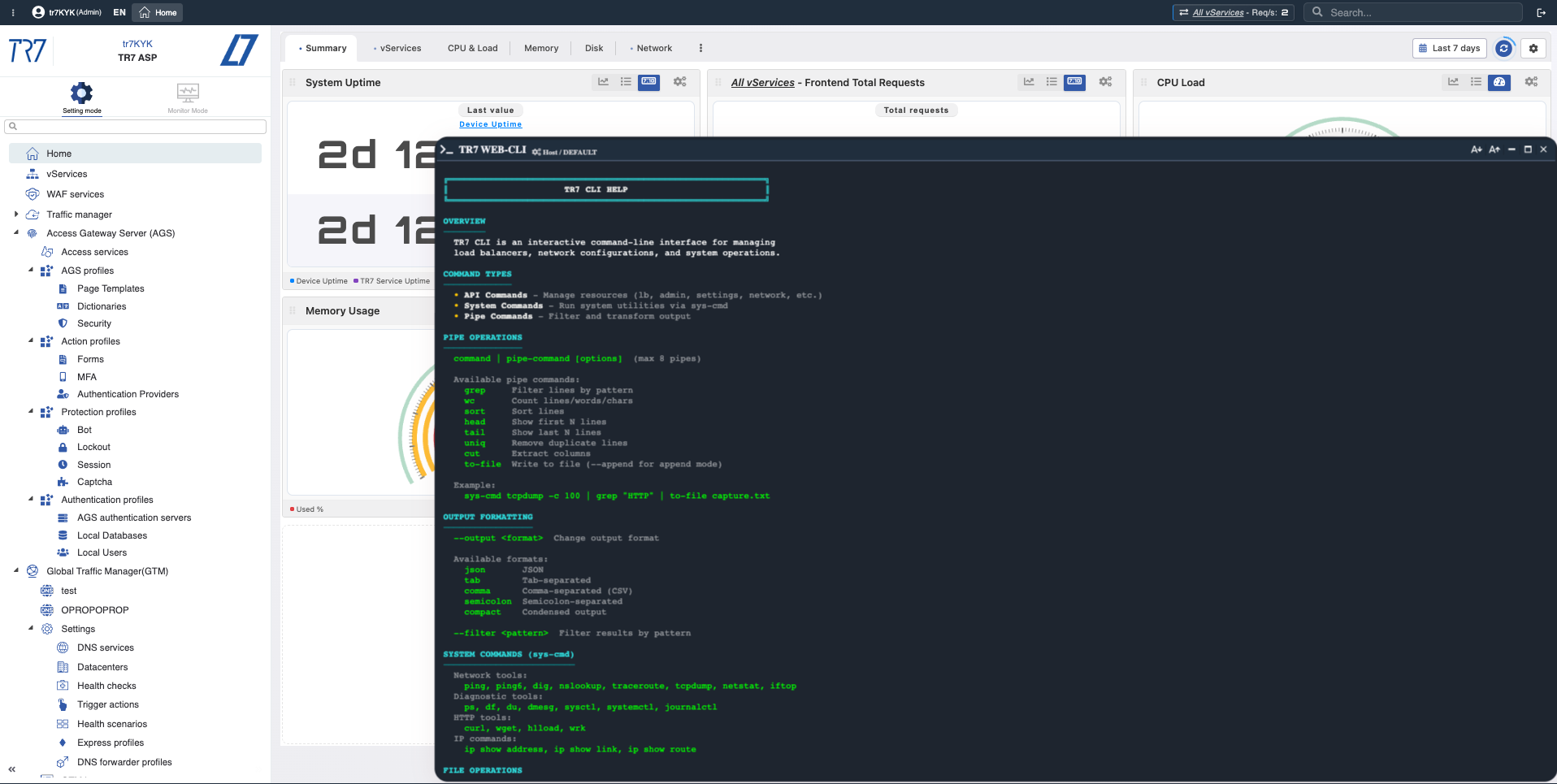
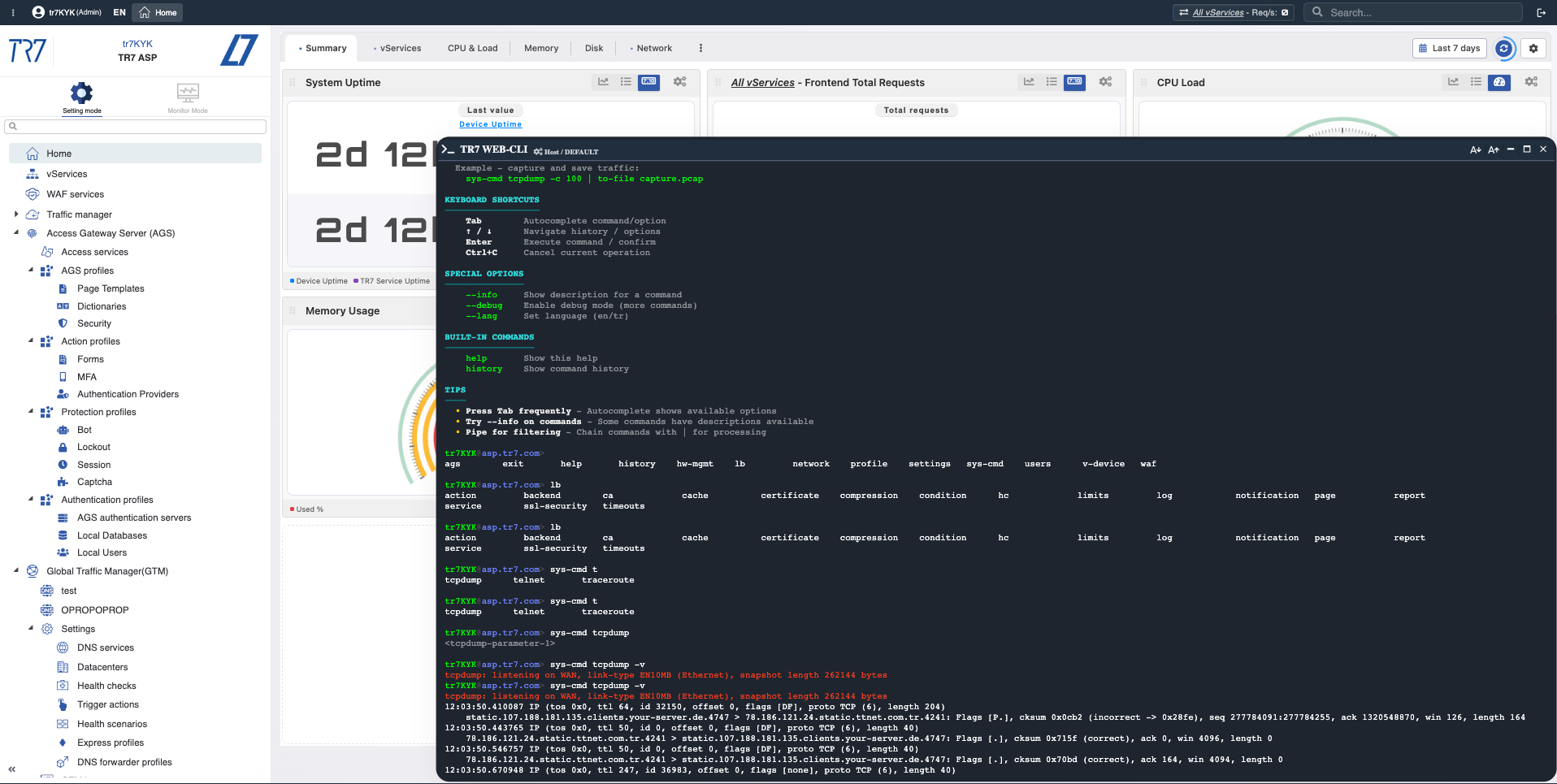
Console Web e CLI TR7: diagnósticos instantâneos e coleta de evidências da interface
A investigação no TR7 não para nos gráficos. O Console Web permite executar os comandos de sistema e rede mais necessários da interface web em produção. Não é necessário SSH. O CLI TR7 traz a mesma capacidade para a linha de comando; formatos de saída (JSON/CSV/tab) e comandos pipe tornam as etapas de investigação reproduzíveis.
Verificação de rede: ping, traceroute, dig, iftop
Verificar conectividade de backend, resolução DNS, análise de caminho e distribuição de largura de banda em tempo real do appliance.
Captura de tráfego direcionado: tcpdump, ssldump
Capturar pacotes para host/porta específico. Inspecionar handshakes TLS. Salvar apenas tráfego relevante em arquivo.
Teste de backend: curl, wrk
Medir código de resposta e tempo do backend da perspectiva do ADC. Executar testes de carga controlados quando necessário.
Status do sistema: netstat, ps, df, journalctl
Visualizar estados TCP, processos, uso de disco e logs do sistema de uma única tela.
Console Web: exemplos de fluxos de investigação
Você detectou um aviso no Flow Panel. Os fluxos a seguir são exemplos práticos para triagem rápida.
Timeout de backend ou problema de rede?
As métricas mostram timeout
ping backend-ip → Está acessível?
curl -I http://backend:8080/health → Qual é o código de resposta?
traceroute backend-ip → Há interrupções ao longo do caminho?
Resultado: Rede ou aplicação — separado rapidamente
Erro TLS: cliente ou servidor?
Erro de conexão SSL existe
ssldump -i wan0 host client-ip → Capturar o handshake
Identificar incompatibilidade de certificado, protocolo ou cifra
Resultado: Configuração do cliente ou servidor — provado com pacotes
Pico súbito de tráfego: ataque ou carga real?
A contagem de requisições aumentou repentinamente
iftop -i wan0 → Ver top talkers em tempo real
netstat -an | grep ESTABLISHED | wc → Contagem de conexões
tcpdump -c 1000 port 443 | to-file spike.pcap → Captura de amostra
Resultado: DDoS, bot ou tráfego legítimo — decidir com dados
Backend 'rápido' mas usuário diz 'lento'
A equipe de aplicação não vê nenhum problema
curl -w '%{time_total}' http://backend/api → Tempo da perspectiva do ADC
wrk -t2 -c10 -d10s http://backend/api → Teste sob carga
Resultado: Cadeia Cliente–ADC–backend — a diferença fica clara
Não ative o debug — direcione-o.
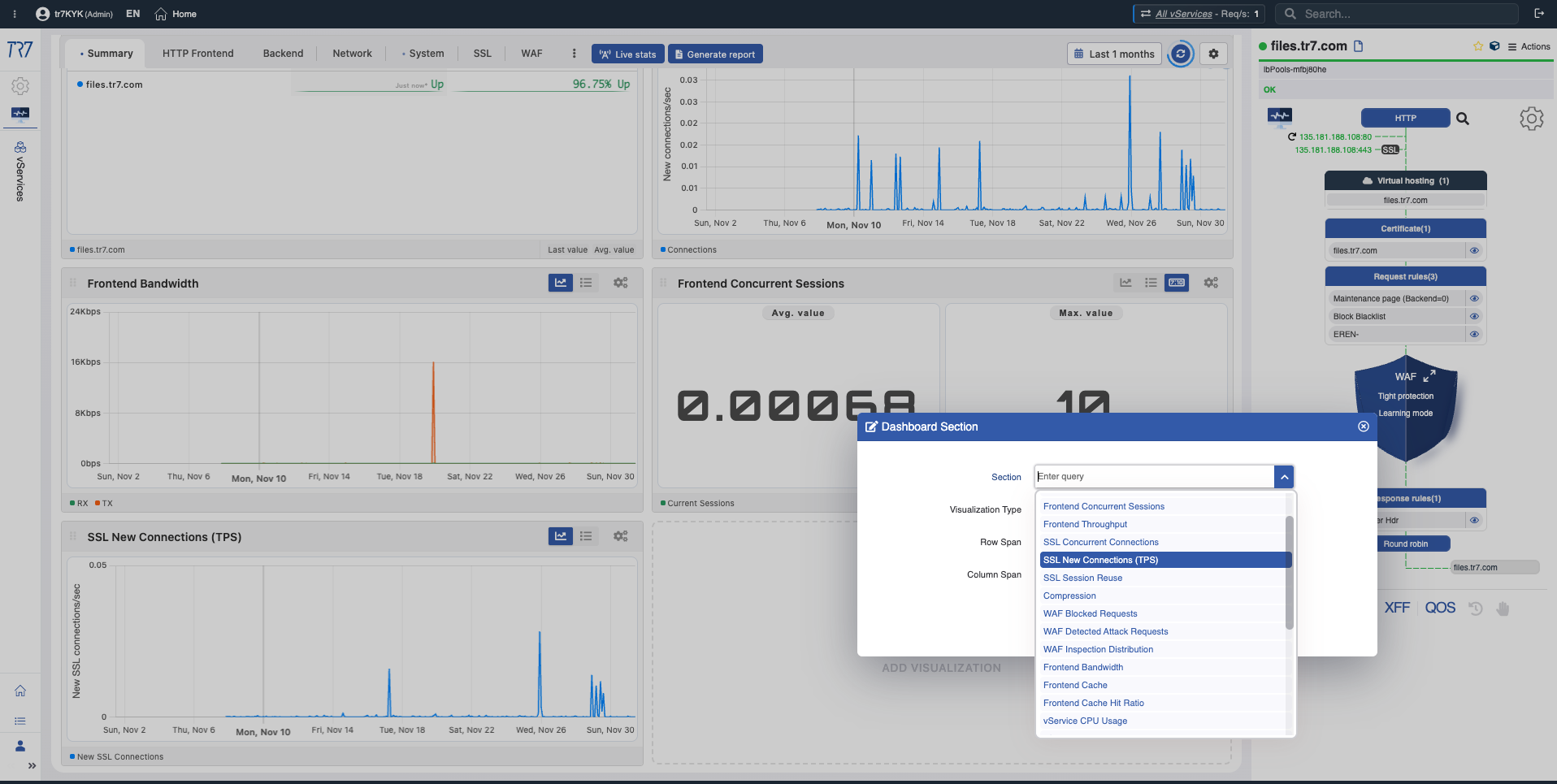
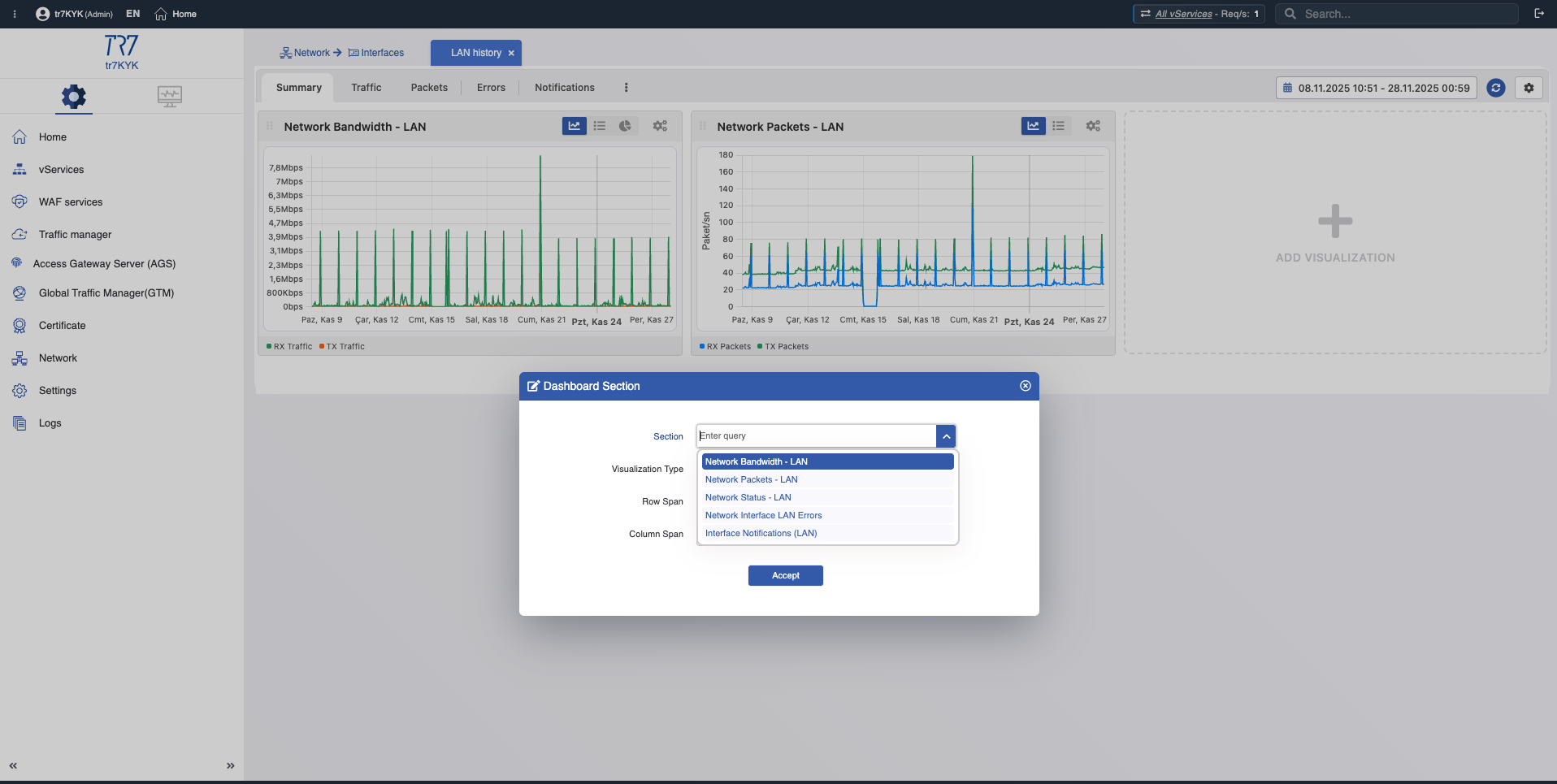
Biblioteca de métricas: monitoramento retrospectivo e gráficos de análise
Os títulos abaixo são títulos de grupos de gráficos de métricas na interface do TR7. Cada grupo contém gráficos onde métricas relacionadas podem ser monitoradas e analisadas retrospectivamente. Esses gráficos permitem examinar intervalos de tempo específicos durante ou após um incidente, ver tendências e detectar anomalias.
Total de requisições Frontend
Total de requisições
What?Mostra a contagem total de requisições HTTP/HTTPS para o serviço ao longo do tempo.
Why important?Referência fundamental para entender picos de tráfego, quedas súbitas e impacto na capacidade. Permite comparação antes/depois do incidente.
Distribuição de código de status Frontend
Distribuição de código de status
What?Mostra a distribuição de códigos de resposta HTTP (2xx sucesso, 3xx redirecionamento, 4xx erro de cliente, 5xx erro de servidor) ao longo do tempo.
Why important?Detectar rapidamente aumentos na taxa de erro. Pico 5xx pode indicar problemas de backend; pico 4xx pode indicar problemas do lado do cliente ou de configuração.
Novas conexões Frontend
Novas conexões
What?Mostra novas conexões TCP abertas por segundo.
Why important?Aumentos súbitos de conexão podem indicar ataques DDoS, atividade de bot ou problemas de reconexão do lado do cliente.
Sessões concorrentes Frontend
Sessões concorrentes
What?Mostra a contagem de sessões ativas simultaneamente.
Why important?Ajuda a entender o quão perto você está dos limites de capacidade. Aproximar-se dos limites de sessão pode causar degradação de desempenho.
Taxa de transferência Frontend
Taxa de transferência
What?Mostra o volume total de dados passando pelo serviço (bits/seg ou bytes/seg).
Why important?Usado para entender uso de largura de banda e tendências de tráfego. Quedas na taxa de transferência podem indicar problemas de rede ou backend.
Conexões concorrentes SSL
Concorrência SSL
What?Mostra a contagem de conexões TLS criptografadas ativas simultaneamente.
Why important?Operações SSL/TLS consomem muito CPU; essa métrica é crítica para planejamento de capacidade e análise de desempenho.
Novas conexões SSL (TPS)
TPS handshake TLS
What?Mostra handshakes TLS realizados por segundo.
Why important?Aumentos súbitos na taxa de handshake podem indicar que a reutilização de sessão não está funcionando ou problemas do lado do cliente. Altas taxas de handshake aumentam a carga da CPU.
Reutilização de sessão SSL
Reutilização de sessão SSL
What?Mostra taxa de reutilização de sessão TLS e estatísticas.
Why important?Baixa reutilização de sessão causa uso desnecessário de CPU e maior latência. Essa métrica orienta a otimização de desempenho TLS.
Compressão
Compressão
What?Mostra taxa de compressão de resposta HTTP e volume de dados compactados.
Why important?A compressão economiza largura de banda, mas usa CPU. Entender esse equilíbrio é importante para otimização de desempenho.
Requisições bloqueadas WAF
Requisições bloqueadas WAF
What?Mostra contagem de requisições bloqueadas pelo Web Application Firewall ao longo do tempo.
Why important?Aumento súbito em bloqueios pode indicar uma onda de ataque ou uma nova regra produzindo falsos positivos. Qualquer caso requer investigação.
Requisições de ataque detectadas WAF
Ataques detectados WAF
What?Mostra contagem e tipos de tentativas de ataque detectadas pelo WAF.
Why important?Permite rastrear nível de ameaça e tendências de ataque. Entender quais tipos de ataque são tentados e com que frequência é valioso para estratégia de segurança.
Distribuição de inspeção WAF
Distribuição de inspeção WAF
What?Mostra qual proporção de regras e categorias WAF são acionadas.
Why important?Mostra quais conjuntos de regras estão ativos e quais disparam com mais frequência. Dados fundamentais para decisões de ajuste e otimização de regras.
Largura de banda Frontend
Largura de banda
What?Mostra largura de banda de entrada e saída usada pelo serviço.
Why important?Usado para monitorar saturação de link e mudanças na taxa de transferência. Aproximar-se dos limites de largura de banda pode causar problemas de desempenho.
Cache Frontend
Cache
What?Mostra o comportamento do cache do serviço, dados gravados e lidos do cache.
Why important?O cache reduz a carga do backend e melhora os tempos de resposta. Mudanças no comportamento do cache afetam diretamente o desempenho.
Taxa de acerto de cache Frontend
Taxa de acerto de cache
What?Mostra qual porcentagem de requisições são servidas do cache.
Why important?Alta taxa de acerto reduz a carga do backend e encurta os tempos de resposta. Quedas na taxa de acerto exigem investigação da configuração do cache ou mudanças de conteúdo.
Uso de CPU vService
Uso de CPU vService
What?Mostra a porcentagem de uso de CPU atribuída a este serviço.
Why important?Permite ver quanto CPU um único serviço consome. Um serviço usando CPU excessivo pode afetar outros.
Uso de memória vService
Uso de memória vService
What?Mostra o uso de memória atribuído a este serviço.
Why important?Monitorar o consumo de memória por serviço ajuda a detectar vazamentos de memória ou problemas de uso excessivo de recursos.
% Uso de memória vService
% Memória vService
What?Mostra o uso de memória do serviço como porcentagem.
Why important?Usado para análise de tendências e planejamento de capacidade. Uso de memória em aumento contínuo pode sinalizar um problema.
Tempo de atividade vService
Tempo de atividade vService
What?Mostra o tempo decorrido desde a última reinicialização do serviço.
Why important?Permite correlacionar reinicializações de serviço com linhas do tempo de incidentes. Reinicializações inesperadas requerem investigação.
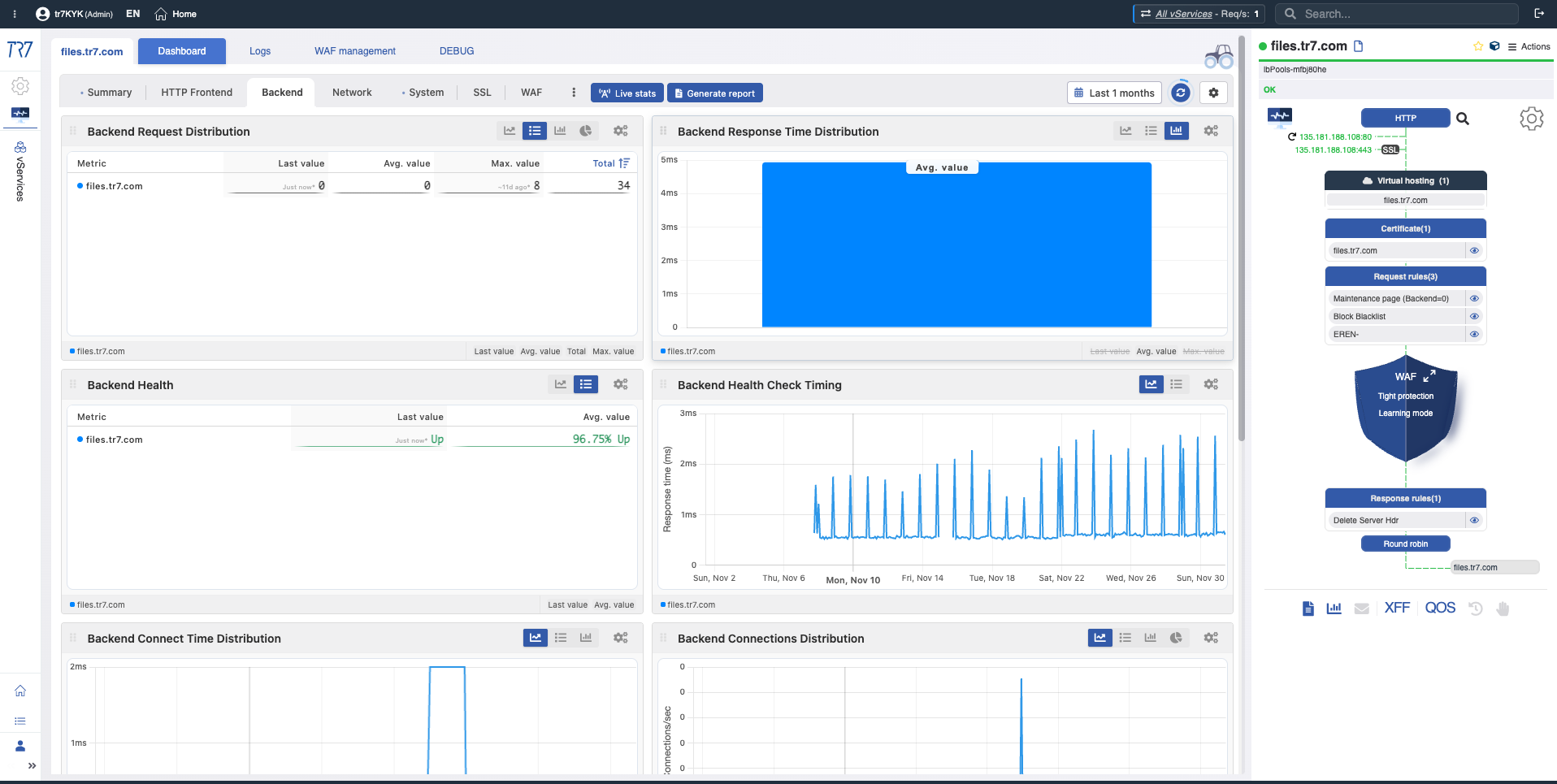
Distribuição de requisições Backend
Distribuição de requisições Backend
What?Mostra como as requisições de entrada são distribuídas entre os servidores backend.
Why important?Permite detectar distribuição de carga desbalanceada. Um backend recebendo desproporcionalmente mais ou menos requisições pode indicar problemas de configuração ou saúde.
Distribuição de tempo de resposta Backend
Distribuição de tempo de resposta Backend
What?Mostra o tempo de resposta médio de cada servidor backend comparativamente.
Why important?Permite identificar rapidamente backends lentos. Se o tempo de resposta de um backend for significativamente maior que outros, pode haver um problema com esse servidor.
Saúde Backend
Saúde Backend
What?Mostra resultados de verificação de saúde e status de saúde para cada servidor backend.
Why important?Permite ver instantaneamente quais backends estão saudáveis, inativos ou degradados.
Timing de verificação de saúde Backend
Timing de verificação de saúde
What?Mostra com que frequência as verificações de saúde são executadas e seus tempos de resposta.
Why important?Permite detectar problemas de timing de verificação de saúde. Respostas lentas de verificação de saúde podem atrasar a detecção de um backend problemático.
Distribuição de tempo de conexão Backend
Distribuição de tempo de conexão
What?Mostra a distribuição do tempo de estabelecimento de conexão com backends.
Why important?Ajuda a detectar atrasos de rede e problemas de conexão TCP. Tempo de conexão alto indica problemas de rede ou do lado do backend.
Distribuição de conexões Backend
Distribuição de conexões
What?Mostra a distribuição de conexões ativas entre backends.
Why important?Permite monitorar comportamento de sessão sticky e balanceamento de carga. Acúmulo desproporcional de conexões em um backend pode causar problemas de desempenho.
Distribuição de largura de banda IN Backend
Distribuição de largura de banda IN
What?Mostra a distribuição de largura de banda do tráfego indo para backends.
Why important?Permite ver quais backends recebem quanto tráfego. Um backend recebendo tráfego excessivo pode se tornar um gargalo.
Distribuição de largura de banda OUT Backend
Distribuição de largura de banda OUT
What?Mostra a distribuição de largura de banda do tráfego de resposta dos backends.
Why important?Ajuda a entender tamanhos de resposta de backend e padrões de tráfego. Backends produzindo respostas grandes afetam o planejamento de largura de banda.
Distribuição de sessões Backend
Distribuição de sessões
What?Mostra a distribuição de sessões ativas entre backends.
Why important?Permite monitorar comportamento de persistência de sessão e densidade de sessão por backend.
Distribuição de fila Backend
Distribuição de fila
What?Mostra o status da fila de requisições aguardando serem roteadas para backends.
Why important?Acúmulo de fila é um sinal precoce de capacidade de backend insuficiente. À medida que as filas se enchem, os tempos de resposta aumentam.
Largura de banda de rede - WAN
Largura de banda WAN
What?Mostra o volume total de tráfego passando pela interface WAN.
Why important?Permite ver o quão perto você está da capacidade do link. Saturação de link causa perda de pacotes e aumento de latência.
Pacotes de rede - WAN
Pacotes WAN
What?Mostra pacotes processados por segundo (PPS).
Why important?Anomalias de PPS podem indicar ataques DDoS ou problemas de rede. PPS alto com largura de banda baixa indica inundação de pacotes pequenos.
Status de rede - WAN
Status WAN
What?Mostra o status operacional da interface de rede (ativo/inativo) e qualidade do link.
Why important?Permite detectar instantaneamente mudanças no status do link. Links intermitentes inativos causam problemas de conectividade.
Erros de interface de rede
Erros de interface
What?Mostra erros ocorrendo na interface (CRC, colisão, drop, etc.).
Why important?Erros de interface podem indicar problemas de cabo físico, incompatibilidades de MTU ou falhas de hardware.
Unidades de interface (WAN)
Unidades de interface
What?Mostra o status de sub-interfaces e VLANs.
Why important?Permite monitorar o status de cada sub-unidade separadamente em topologias de rede complexas.
Uso de CPU do dispositivo
CPU do dispositivoCPU do sistema
What?Mostra a porcentagem total de uso de CPU do dispositivo.
Why important?Alto uso de CPU afeta o desempenho de todos os serviços. CPU consistentemente alto requer aumento de capacidade ou otimização.
Temperatura da CPU do dispositivo
Temperatura da CPU
What?Mostra a temperatura de operação da CPU.
Why important?Alta temperatura pode causar throttling térmico e degradação de desempenho. Aumento excessivo de temperatura aumenta o risco de falha de hardware.
Tempo de atividade do sistema
Tempo de atividade do sistema
What?Mostra o tempo decorrido desde que o dispositivo foi iniciado pela última vez.
Why important?Permite detectar reinicializações inesperadas. Se o tempo de atividade foi redefinido, investigue por que o dispositivo reiniciou.
Carga do sistema
Carga do sistemaMédia de carga
What?Mostra as médias de carga do sistema em 1, 5 e 15 minutos.
Why important?Ajuda a entender o quão ocupado o sistema está. Se a média de carga consistentemente exceder a contagem de CPU, o sistema está sobrecarregado.
Uso total de memória
Uso total de memória
What?Mostra a quantidade total de memória usada pelo sistema.
Why important?Permite rastrear o consumo de memória ao longo do tempo. Uso de memória em aumento contínuo pode indicar vazamento de memória.
Memória disponível
Memória disponível
What?Mostra a quantidade de memória disponível para novos processos.
Why important?Baixa memória disponível pode impedir o início de novas conexões e processos.
Taxa de uso de memória
% Uso de memória
What?Mostra qual porcentagem da memória total está sendo usada.
Why important?Usado para planejamento de capacidade e alertas baseados em limites. Uso acima de 90% é nível crítico.
Uso de swap
Uso de swap
What?Mostra o uso do espaço de swap em disco.
Why important?O uso de swap indica que a memória física é insuficiente. Uso ativo de swap causa degradação significativa de desempenho.
Uso de disco
Uso de disco
What?Mostra a quantidade de espaço em disco usado.
Why important?Permite monitorar a taxa de preenchimento do disco. Se o disco encher, a gravação de log pode parar e o sistema pode ficar instável.
Capacidade do disco
Capacidade do disco
What?Mostra a capacidade total do disco.
Why important?Ponto de referência para planejamento de capacidade e análise de tendência de crescimento.
Taxa de uso de disco
% Uso de disco
What?Mostra qual porcentagem da capacidade do disco está sendo usada.
Why important?Acima de 90% é aviso, acima de 95% é nível crítico. Preenchimento de disco requer planejamento de rotação e arquivamento de log.
Uso de inode de disco
Uso de inode
What?Mostra o uso de inode do sistema de arquivos.
Why important?Mesmo com espaço livre em disco, se os inodes estiverem esgotados, novos arquivos não podem ser criados. Crítico para sistemas com muitos arquivos pequenos.
Leitura de E/S de disco
Leitura de E/S de disco
What?Mostra operações de leitura de disco por segundo e velocidade.
Why important?E/S de leitura alta pode indicar gargalo de disco. Especialmente importante para sistemas não-SSD.
Gravação de E/S de disco
Gravação de E/S de disco
What?Mostra operações de gravação de disco por segundo e velocidade.
Why important?A gravação de log e auditoria gera constantemente E/S de disco. Se a velocidade de gravação cair, ocorre risco de perda de log.
Latência de E/S de disco
Latência de E/S
What?Mostra o tempo médio de conclusão para operações de disco.
Why important?Alta latência de E/S é um sinal precoce de degradação de desempenho de disco. O aumento de latência afeta o desempenho geral do sistema.
Contagem de conexões TCP
Conexões TCP
What?Mostra a contagem total de conexões TCP no sistema.
Why important?Permite ver se você está se aproximando dos limites de conexão. Se o limite de conexão for excedido, novas conexões são rejeitadas.
TCP Established
Conexões estabelecidas
What?Mostra a contagem de conexões transferindo dados ativamente.
Why important?Indicador de carga de trabalho real. A contagem de conexões estabelecidas está diretamente relacionada à capacidade.
TCP TIME_WAIT
TIME_WAIT
What?Mostra a contagem de conexões aguardando no estado TIME_WAIT.
Why important?Alta contagem TIME_WAIT indica risco de esgotamento de porta. Conexões de curta duração e tráfego intenso causam acúmulo de TIME_WAIT.
TCP CLOSE_WAIT
CLOSE_WAIT
What?Mostra a contagem de conexões aguardando no estado CLOSE_WAIT.
Why important?Alta contagem CLOSE_WAIT indica que a aplicação não está fechando conexões adequadamente. Isso geralmente é um bug do lado da aplicação.
Retransmissão TCP
Retransmissões
What?Mostra a contagem de retransmissões de pacotes TCP.
Why important?O aumento de retransmissão indica problemas de qualidade de rede, perda de pacotes ou congestionamento. Alta taxa de retransmissão causa aumento de latência e queda na taxa de transferência.
Total de requisições vService
Total de requisições vService
What?Mostra a contagem total de requisições para todos os vServices em um gráfico.
Why important?Permite entender o volume total de tráfego e tendências em todo o dispositivo. Referência fundamental para planejamento de capacidade e avaliação de carga geral.
Total de conexões vService
Total de conexões vService
What?Mostra a contagem total de conexões ativas para todos os vServices.
Why important?Permite monitorar a pressão de conexão e o uso da tabela de conexões em todo o dispositivo. Aproximar-se dos limites da tabela de conexões pode causar rejeição de novas conexões.
Integrações: disponíveis, mas a investigação não depende delas
O TR7 pode se integrar ao ecossistema de monitoramento e gerenciamento de logs da sua organização. A diferença crítica: a investigação de incidentes não depende apenas de pipelines externos. Sistemas externos agregam valor; registros no appliance servem como referência fundamental.
Perguntas frequentes
O objetivo é ter dados necessários para investigação sempre prontos no appliance. Exportação externa e arquivamento centralizado são suportados. No entanto, o sucesso da investigação não depende apenas da configuração de exportação.
O objetivo não é olhar para tudo o tempo todo. Categorias, pesquisa e filtragem permitem que você alcance rapidamente o sinal certo quando necessário.
O objetivo do Console Web não é acesso irrestrito, mas diagnósticos controlados. Quando usado com autorização adequada e runbooks, ele encurta o tempo de investigação.
É em tempo real. Os estados de serviço são monitorados em runtime e as mudanças são imediatamente refletidas como mudanças de cor. Além disso, registros de métricas e eventos retrospectivos são retidos.
O debug normal normalmente captura todo o tráfego e requer filtragem depois. O debug direcionado captura registros apenas para host, porta, path ou cabeçalho específico desde o início. Isso reduz o ruído, acelera a investigação e minimiza o impacto na produção.
O TR7 suporta exportação Prometheus e encaminhamento de log SIEM. As integrações mantêm seu valor. A diferença: dados necessários para investigação não dependem apenas de sistemas externos — eles também estão prontos no appliance.
O período de retenção é configurável. O que importa é que ações de usuário e mudanças de configuração sejam mantidas na mesma linha do tempo que métricas e registros de eventos.
Detalhe é preparação, não complexidade. Mesmo em equipes pequenas, alcançar rapidamente os dados certos durante um incidente economiza tempo. A estrutura categorizada e os recursos de pesquisa facilitam o foco apenas nos dados necessários.
Conclusão
A afirmação do TR7 não é 'mais gráficos' — é tornar a camada ADC/WAF pronta para investigação. Métricas vService/backend/interface, registros de eventos/notificações, trilha de auditoria e visibilidade HTTP/WAF se combinam em uma única linha do tempo; forensics retroativa e debug direcionado aceleram a análise da causa raiz.
Integrações de exportação são valiosas; mas para minimizar o risco 'não foi enviado, então não existe' durante momentos críticos, a cadeia de evidências deve permanecer acessível dentro do produto o tempo todo.
Essas e capacidades similares — detalhes que não aparecem em datasheets, são difíceis de compreender em demos, mas definem a qualidade operacional na prática — são a razão principal pela qual quase todas as organizações que avaliam o TR7 decidem fazer a mudança.