Wenn die Produktion ausfällt, sind drei Fragen wichtig: Was ist passiert? Wann ist es passiert? Warum ist es passiert?
In der Praxis sind die Antworten oft verstreut—Metriken an einem Ort, Traffic-Logs an einem anderen und Änderungshistorie wieder woanders.
Es gibt noch eine weitere Realität: Exporte an externe Systeme sind typischerweise selektiv. Wenn das bei einem Vorfall benötigte Signal nie für den Export ausgewählt wurde, werden Sie es nicht haben.
Der TR7-Ansatz ist klar: Export-Integrationen sind wichtig, aber die Untersuchung sollte nicht ausschließlich von ihnen abhängen. Deshalb hält TR7 kritische Signale auf dem Appliance, ausgerichtet auf einer einzigen Zeitachse.
Ein Signal, das nicht erfasst wird, ist ein Risiko, das unsichtbar bleibt.
Warum reicht nur Export nicht aus?
SIEM, Log-Server und Prometheus/Grafana-Plattformen sind wertvoll für Unternehmens-Sichtbarkeit. Der Untersuchungserfolg hängt jedoch davon ab, dass die richtigen Daten verfügbar sind, wenn Sie sie brauchen.
Selektive Erfassung ist unvermeidlich
Kosten und Rauschen bedeuten, dass nicht jede Metrik/jedes Log exportiert wird. Bei einem Vorfall kann das kritische Signal fehlen.
Korrelation wird schwieriger, wenn Daten verstreut sind
Wenn Metriken, Events, Audit und Traffic-Logs an verschiedenen Orten sind, dauert das Erstellen einer einzigen Zeitachse länger.
Die Pipeline ist ein weiterer Risikobereich
Agent-, Netzwerk-, Quota/Limit- oder Indexierungsprobleme können Datenverlust verursachen—besonders während Vorfällen.
Investigation-Ready
Verbringen Sie Zeit mit Problemlösung, nicht mit Datensammlung. TR7 hält kritische Signale auf dem Appliance bereit.
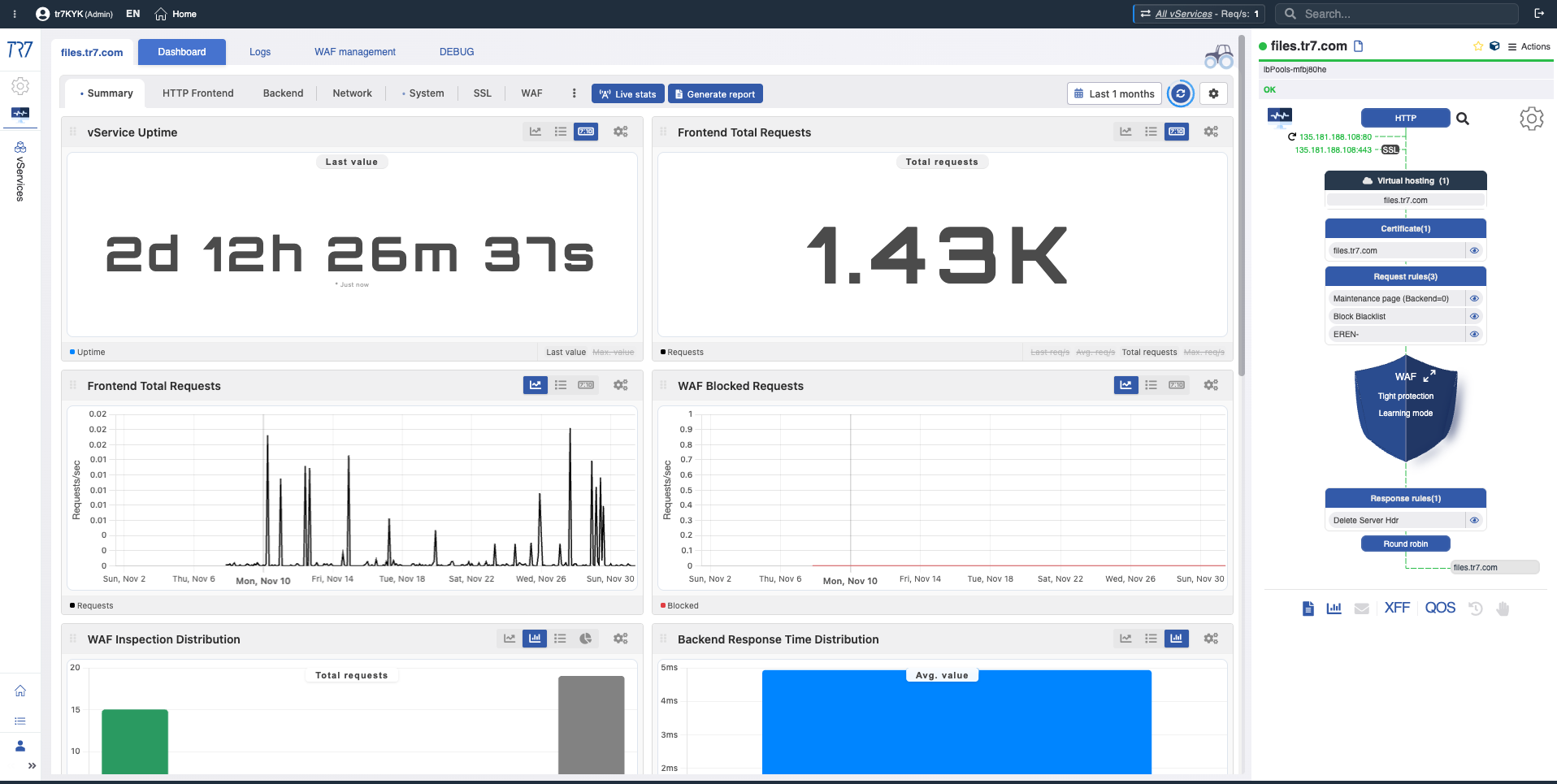
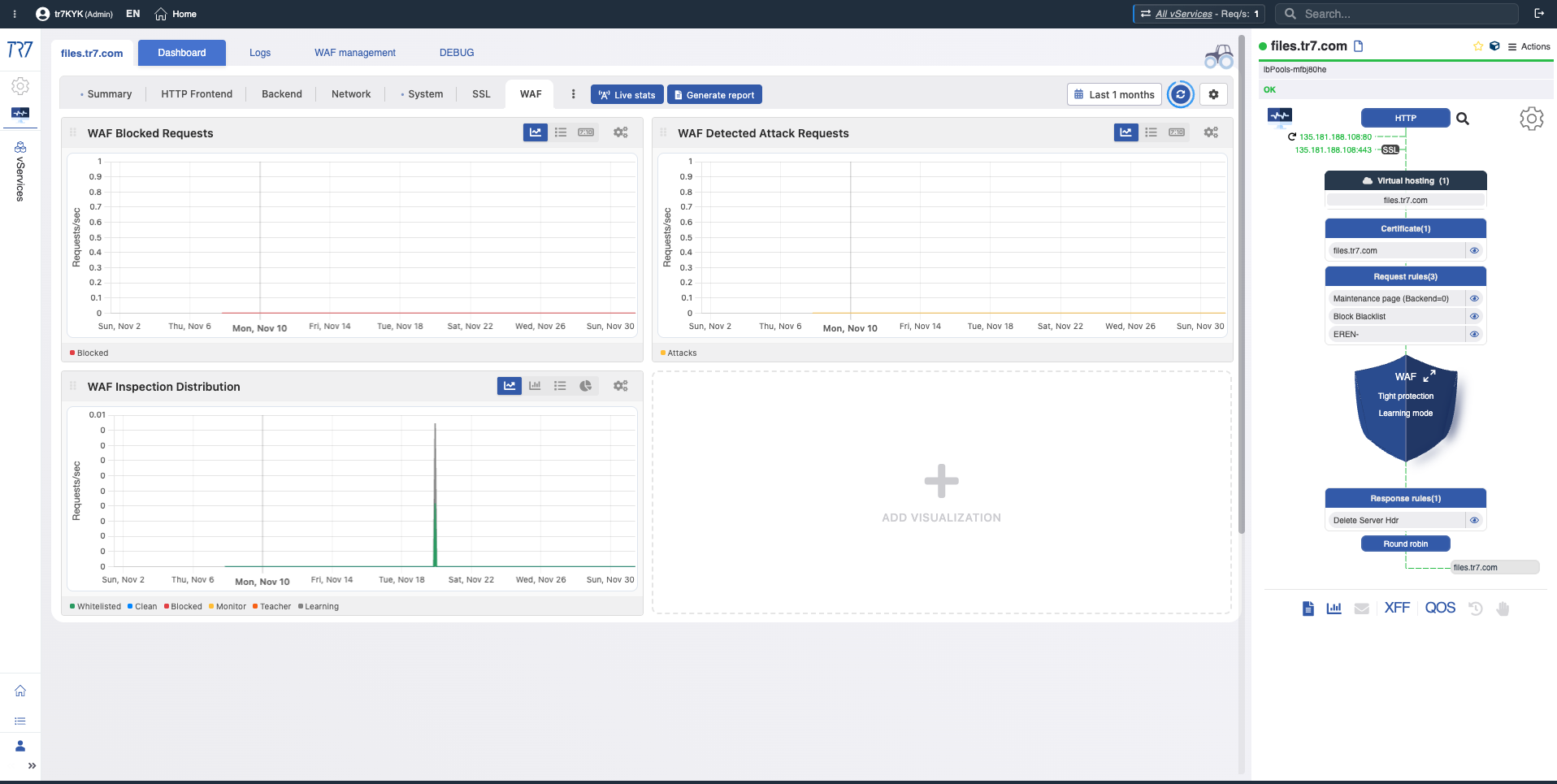
Dynamic Flow Panel: Runtime-Sichtbarkeit und schneller Einstiegspunkt
In der TR7-Oberfläche kann die Service-Topologie live (Runtime) über das Dynamic Flow Panel überwacht werden. Complete Control →
Das Panel zeigt den Servicestatus mit Farben an. Wenn beispielsweise der Interface-Link, der die IP eines vService bedient, ausfällt, erzeugt das System eine Warnung und der Servicename wechselt von Grün zu Gelb.
Dies ermöglicht es Operatoren, sofort zu sehen, was untersucht werden muss. Die Triage beginnt schneller und die Untersuchungszeit verkürzt sich.
Statusfarben
Farben im Flow Panel helfen Ihnen, den Servicestatus schnell zu lesen:
Grün: Normal
Service-Verbindungen und Health-Checks funktionieren wie erwartet.
Aus Request-Details bestimmen: False Positive oder echter Angriff?
Audit-Trail: Regel/Policy-Änderungen?
Gezieltes Debug bei Bedarf verwenden, um nur relevanten Traffic zu untersuchen
Ergebnis: Regel-Tuning oder Sicherheitsaktion — mit Daten entscheiden
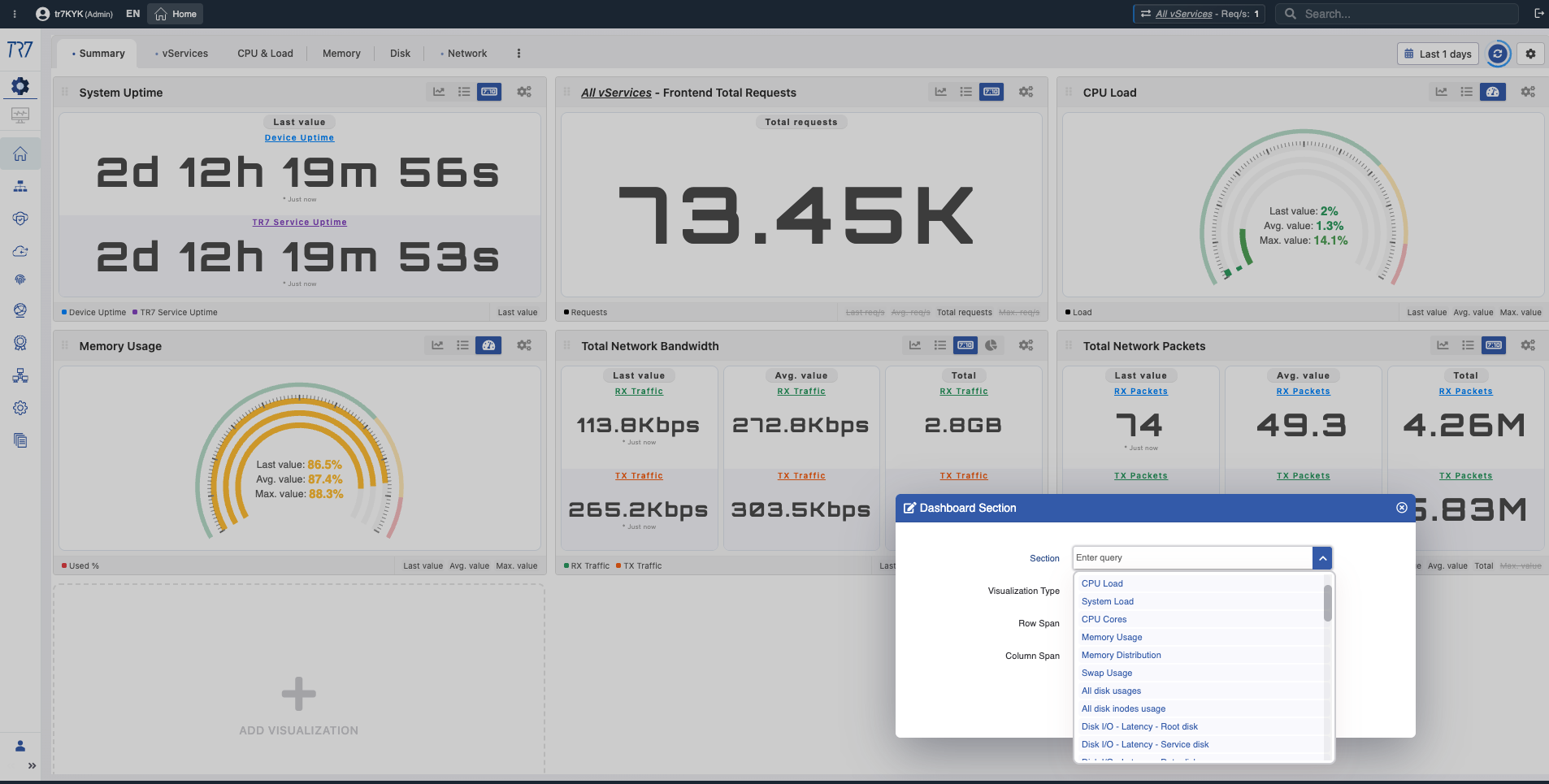
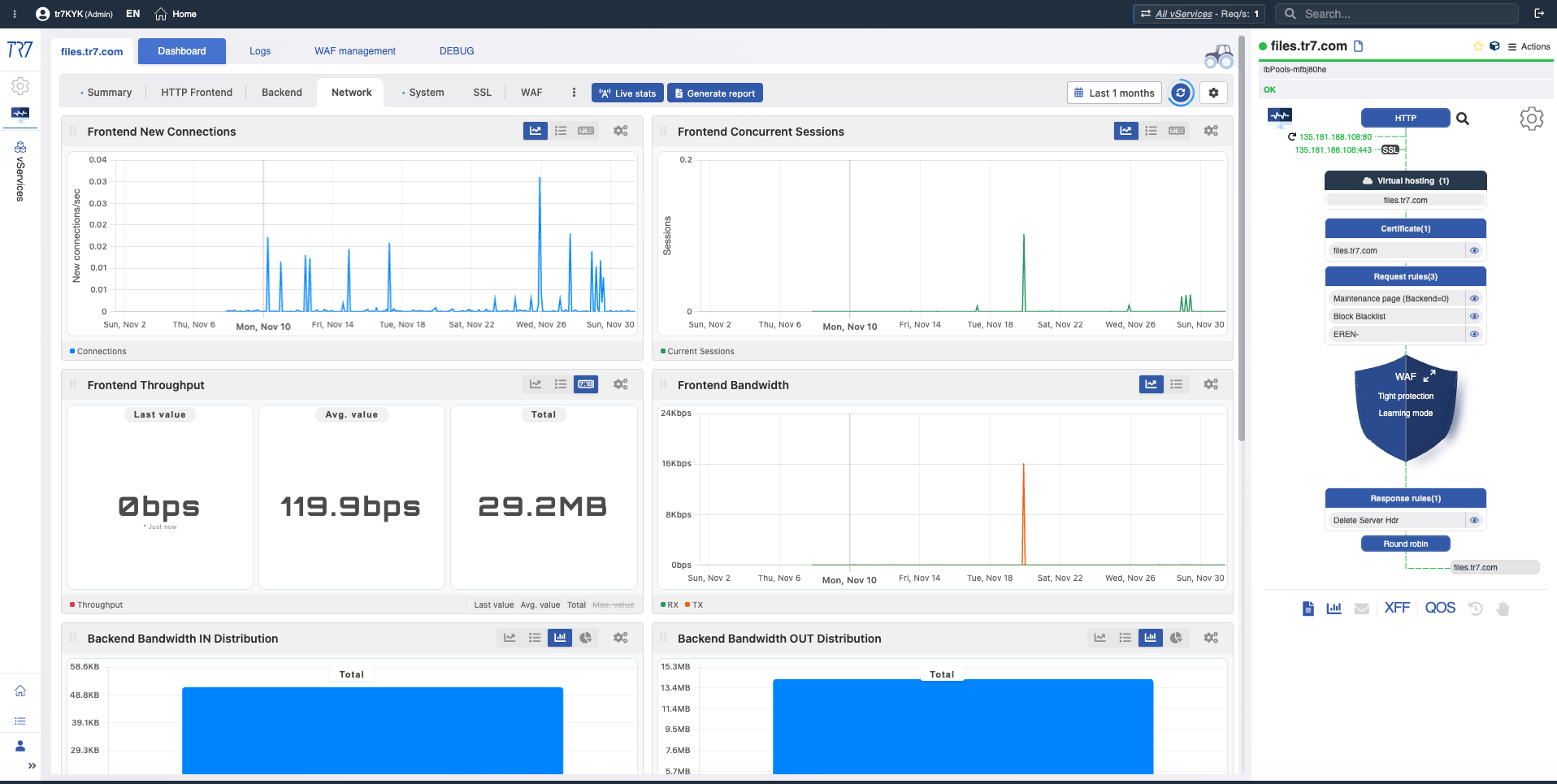
Geräteübersicht: Ausgangspunkt der Untersuchung
Die Vorfalluntersuchung beginnt immer mit der Geräteübersicht. CPU, Speicher, Festplattennutzung und Systemgesundheit — bewerten Sie den Gesamtzustand des Geräts auf einen Blick. Die Zeitbereichsauswahl ermöglicht retroaktive Forensik.
Systemzusammenfassung: Uptime, Gesamtanfragen, CPU-Last, Speicher, Bandbreite — Gerätezustand bei einem Vorfall schnell bewerten.
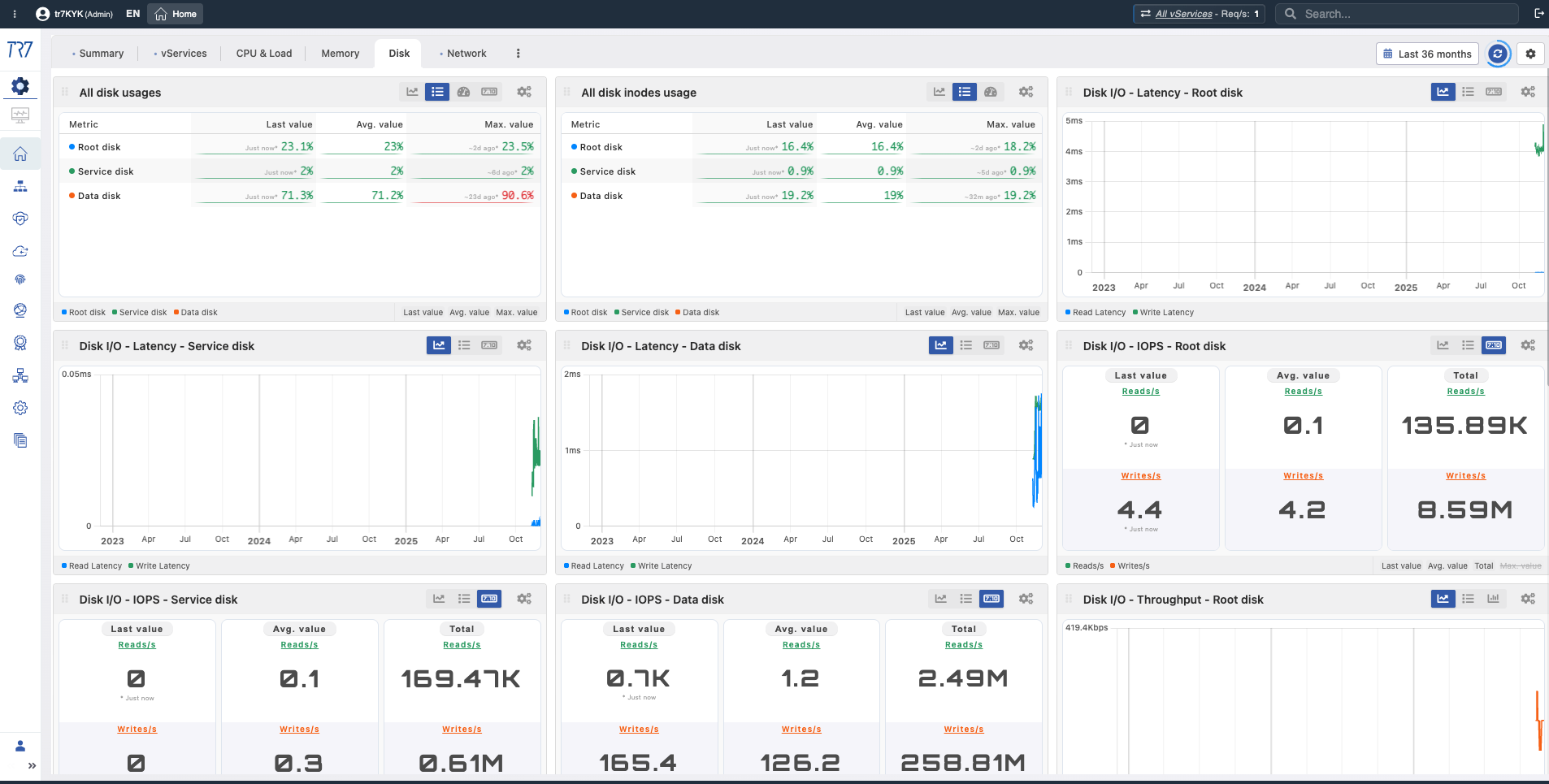
Festplatte & I/O: Nutzung, Inode, Latenz, IOPS — ist Log-Schreibung oder Cache-Performance betroffen?
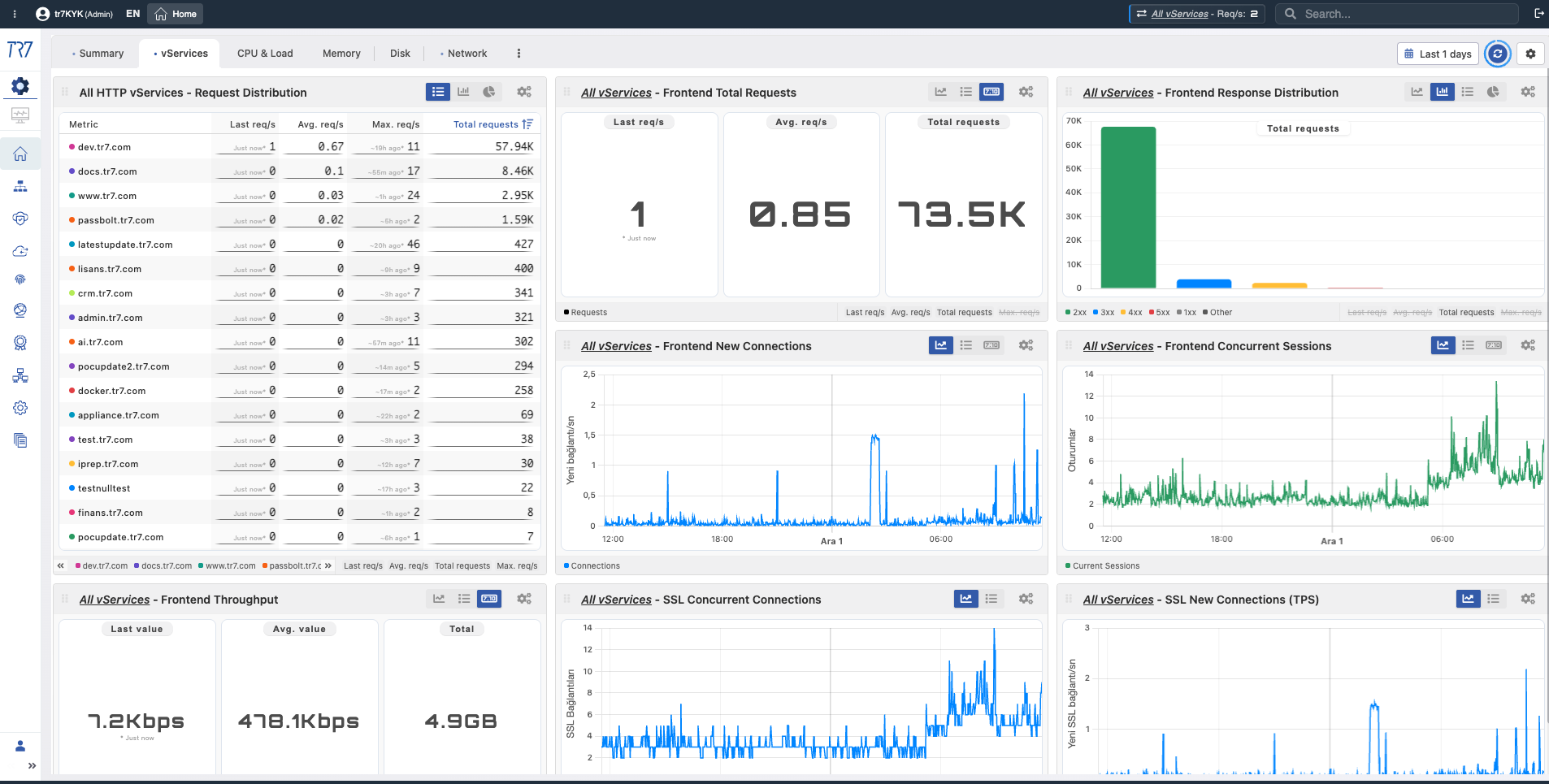
Service & Backend: Performance- und Health-Metriken
Nach der Systemübersicht auf die Service-Schicht zoomen. Alle vServices' Request-Verteilung, Response-Codes, Backend-Health und Service-Topologie über Dynamic Flow Panel — alles auf einen Blick. Jeder vService hat sein eigenes Dashboard.
vService-Übersicht: Request-Verteilung und Response-Codes (2xx/3xx/4xx/5xx) über alle Services — welcher Service hat Anomalien?
vService-Zusammenfassung: Uptime, Frontend-Requests, WAF-Block-Anzahl und Dynamic Flow Panel — aktueller Zustand des Service.
Backend-Verteilungen: Welches Backend ist langsam? Welches erhält mehr Requests? Antwortzeit- und Verbindungsmetriken.
Netzwerk & Interface: Verbindungsstatus und Traffic-Fluss
Liegt das Problem im Service oder im Netzwerk? Topologie, Bandbreite, TCP-Zustandsverteilung und Interface-Metriken beantworten diese Frage. Link-Statusänderungen und Paketfehler zeigen Netzwerkschicht-Probleme schnell auf.
Netzwerktopologie: Bandbreite, TCP-Zustandsverteilung — erster Hinweis zur Trennung von Service- vs. Netzwerkproblemen.
Interface-Metriken: RX/TX-Bandbreite, Paketzähler, Fehler — Link-Performance und Health.
vService-Netzwerk: Pro-Service-Durchsatz und Verbindungszustände — ist das Traffic-Muster normal?
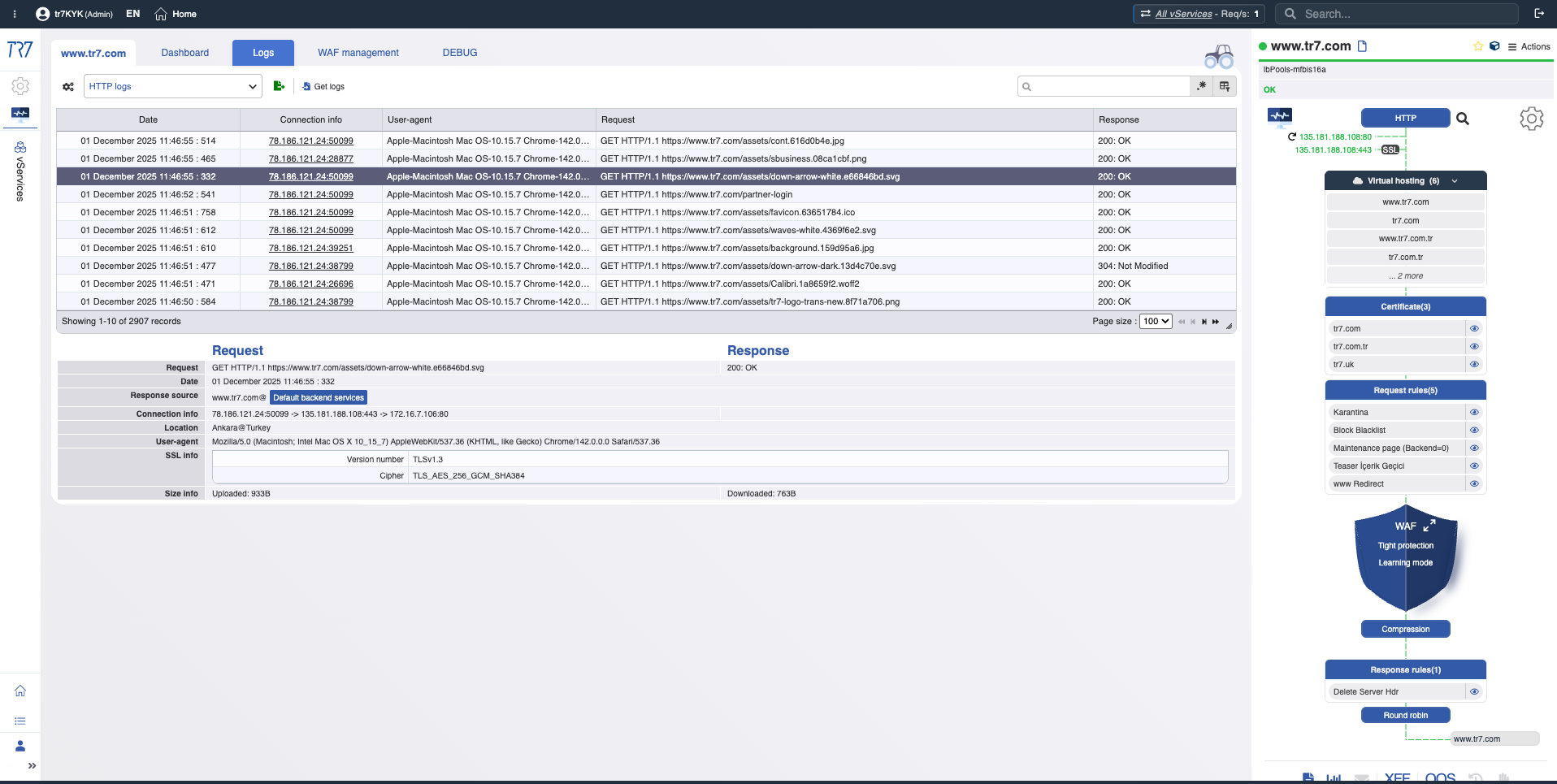
HTTP & WAF Logs: Request-Level-Untersuchung
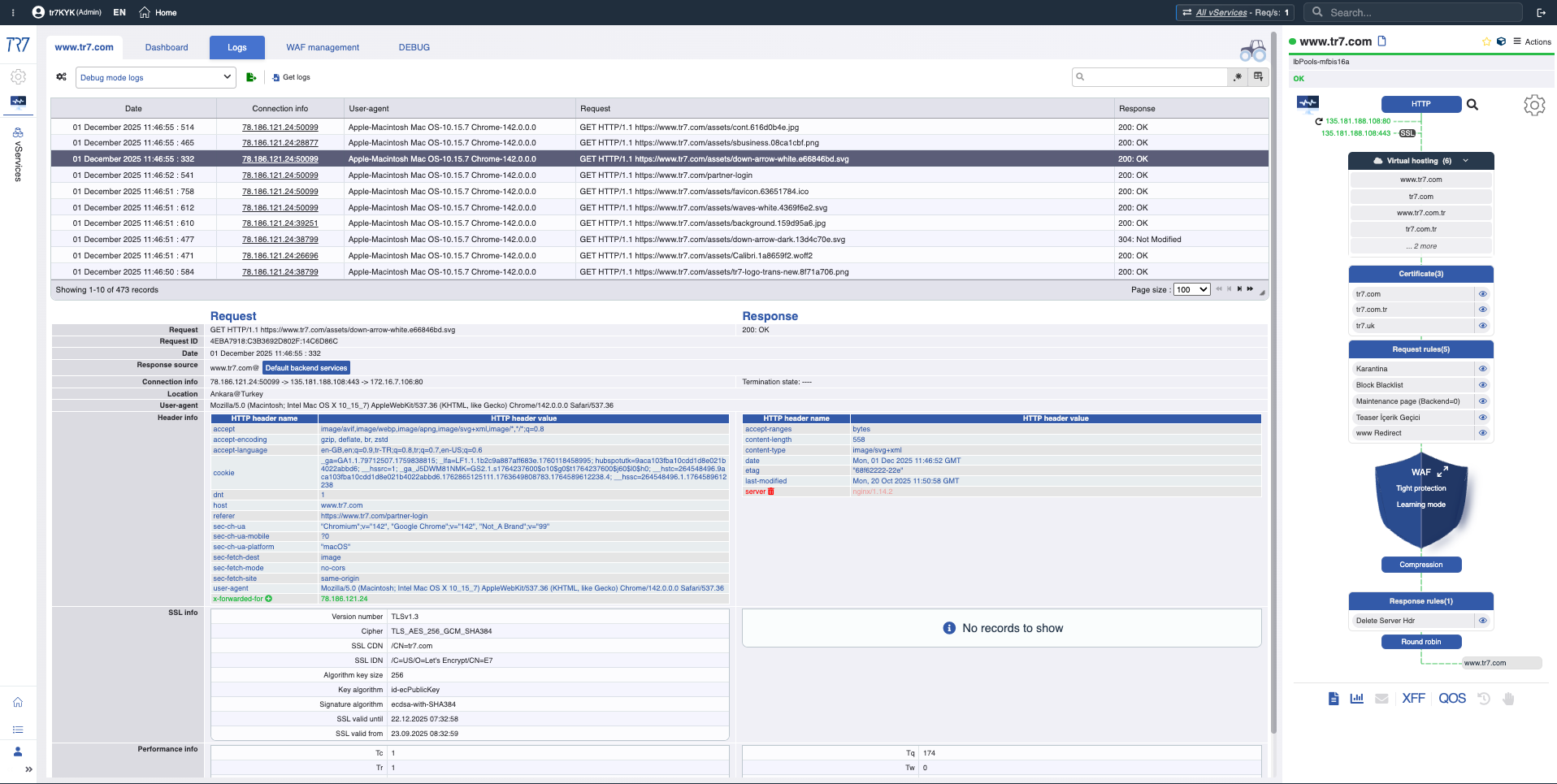
HTTP-Traffic und WAF-Events sind ohne Debug-Aktivierung sichtbar. Bei Bedarf erfasst gezieltes Debug vollständige Details nur für spezifischen Host/Pfad/Header. Request-Level-Forensik ohne Produktionsbeeinträchtigung.
HTTP Logs: Quell-IP, Ziel, Response-Code, Größe, Dauer — grundlegende Sichtbarkeit auch bei ausgeschaltetem Debug.
Gezieltes Debug: Vollständige Header und Cookies nur für relevanten Traffic — Detail ohne Produktionsbeeinträchtigung.
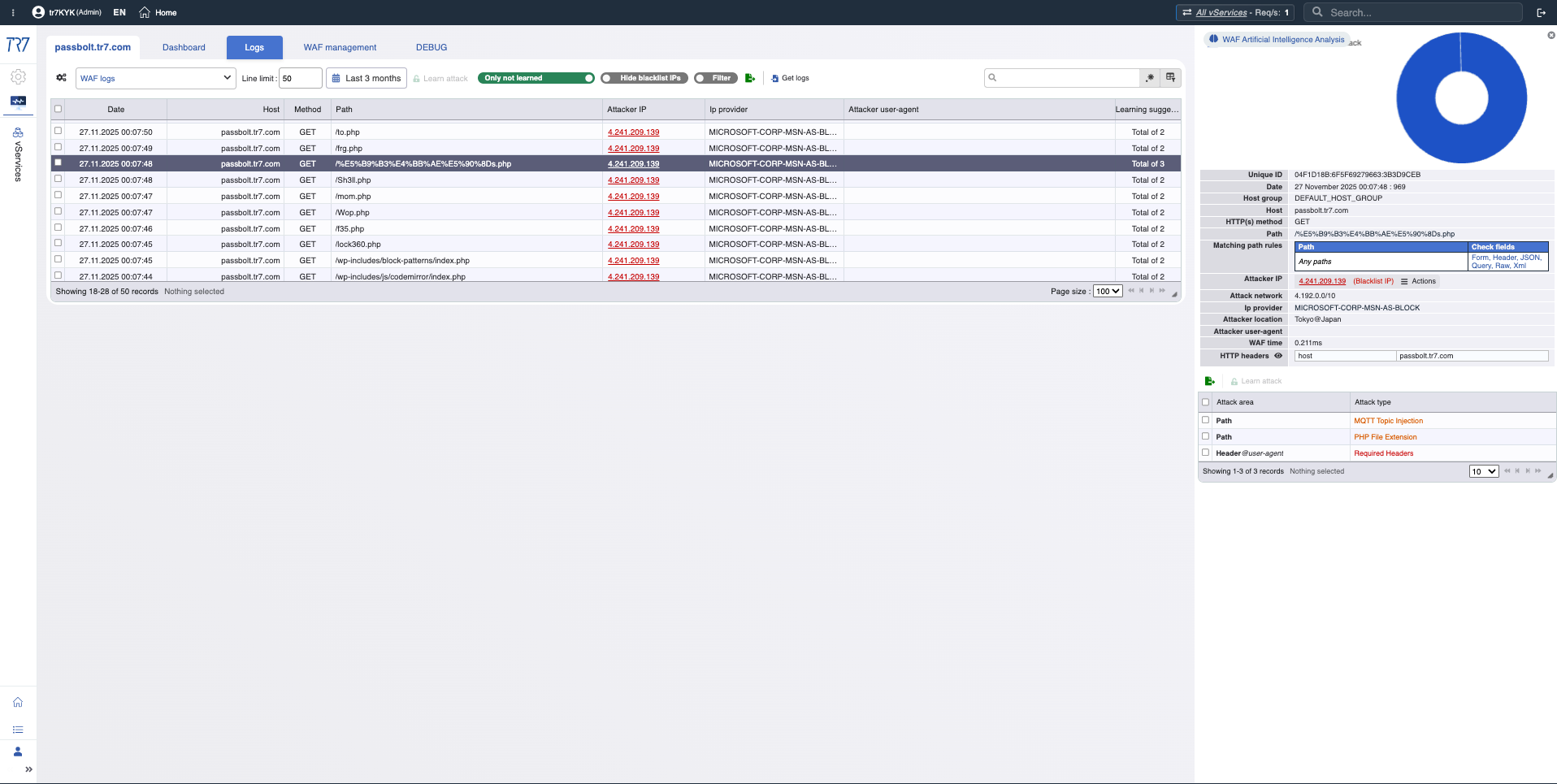
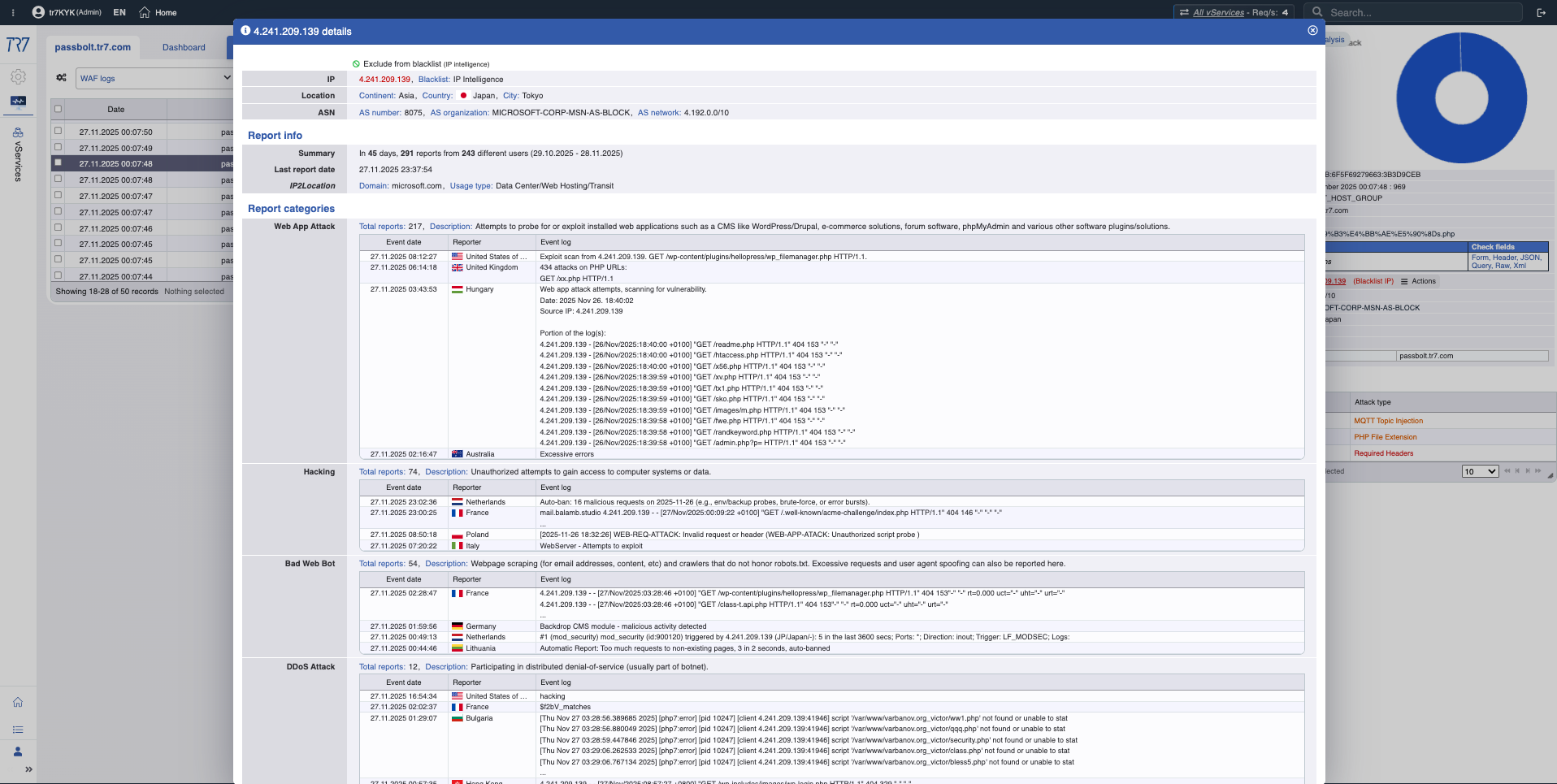
IP-Reputations-Scores und WAF-Metriken zeigen schnell das Angreiferprofil. Die erste Antwort auf 'False Positive oder echter Angriff?' ist hier. Bedrohungskategorien (Botnet, Proxy, VPN, Tor) zeigen die Art der Quell-IP.
IP Intelligence: Reputations-Score, Bedrohungskategorien — Angreiferprofil wird schnell klar.
WAF-Metriken: Blockierungstrend, Inspektionsverteilung — Übersicht der Sicherheitsereignisse.
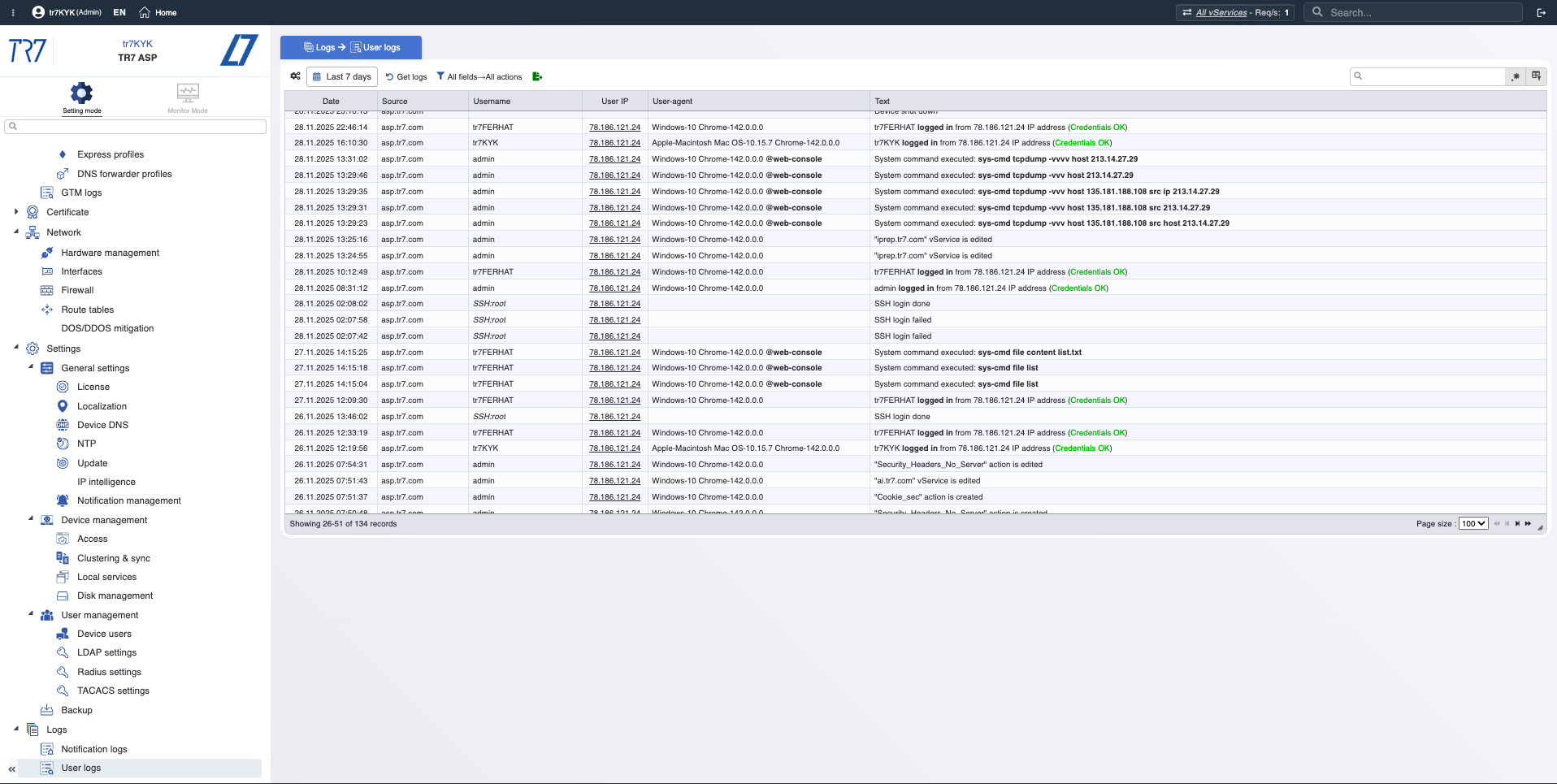
Event-Zeitachse: Benachrichtigungen und Audit-Trail
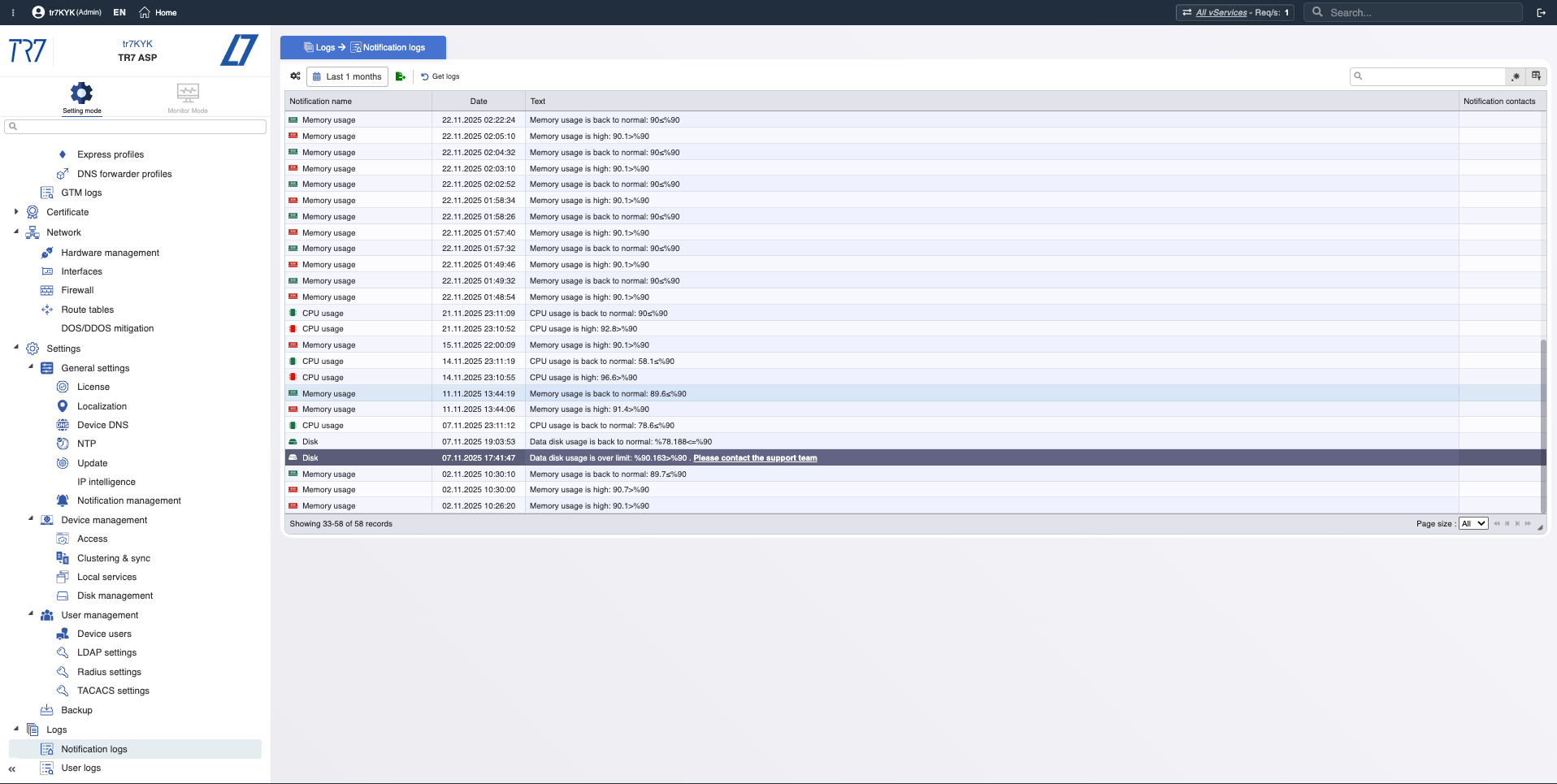
Metriken allein reichen nicht. Welche Warnungen wurden ausgelöst? Wer hat wann was geändert? Bei der Vorfalluntersuchung ist 'welche Änderung hat was beeinflusst?' kritisch. TR7 hält Benachrichtigungs-/Eventaufzeichnungen und Audit-Trail zusammen und beschleunigt diese Korrelation.
Benachrichtigungstypen: CPU, Speicher, Festplatte, Bandbreite, Servicestatus — welche Events werden überwacht?
Benachrichtigungshistorie: Chronologie der ausgelösten Warnungen — welche Warnungen kamen während des Vorfalls?
Audit-Trail: Wer hat wann was geändert? Nachweis für schnelle Korrelation von Vorfällen mit Änderungen.
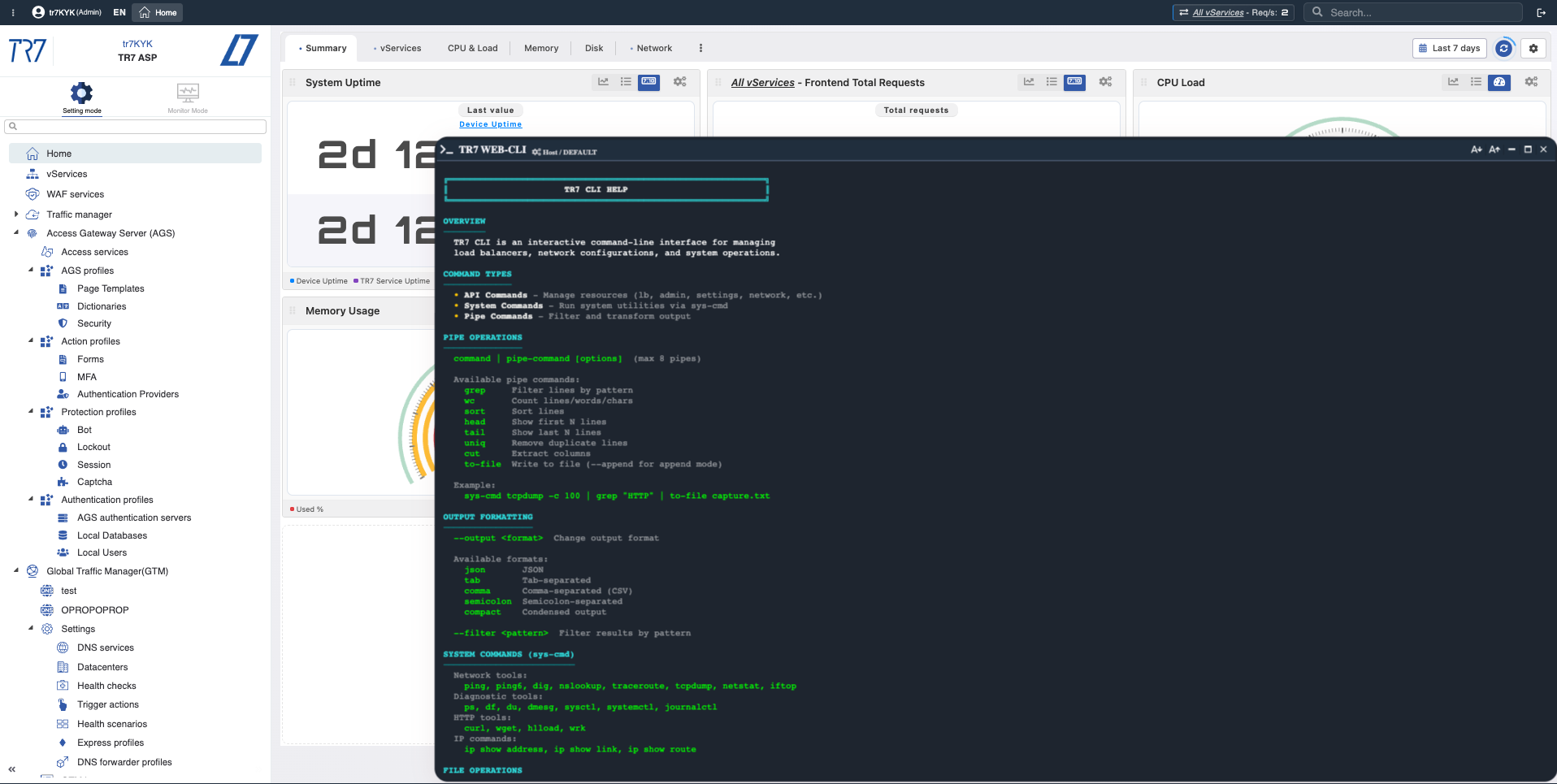
Web-Konsole: Hypothese verifizieren
Metriken liefern eine Hypothese; manchmal werden Befehle zur Verifizierung benötigt. Führen Sie ping, traceroute, curl, tcpdump von der Web-Konsole aus. Kein SSH erforderlich — Ergebnisse erscheinen auf dem gleichen Bildschirm.
Web-Konsole: Diagnosebefehle von der Web-UI — Backend-Konnektivität, DNS, Routenverifizierung schnell erledigt.
Befehlsausgabe: Ergebnisse sofort angezeigt — gezieltes Traffic-Capture mit tcpdump-Beispiel.
Web-Konsole & TR7 CLI: Sofortige Diagnose und Beweissammlung von der UI
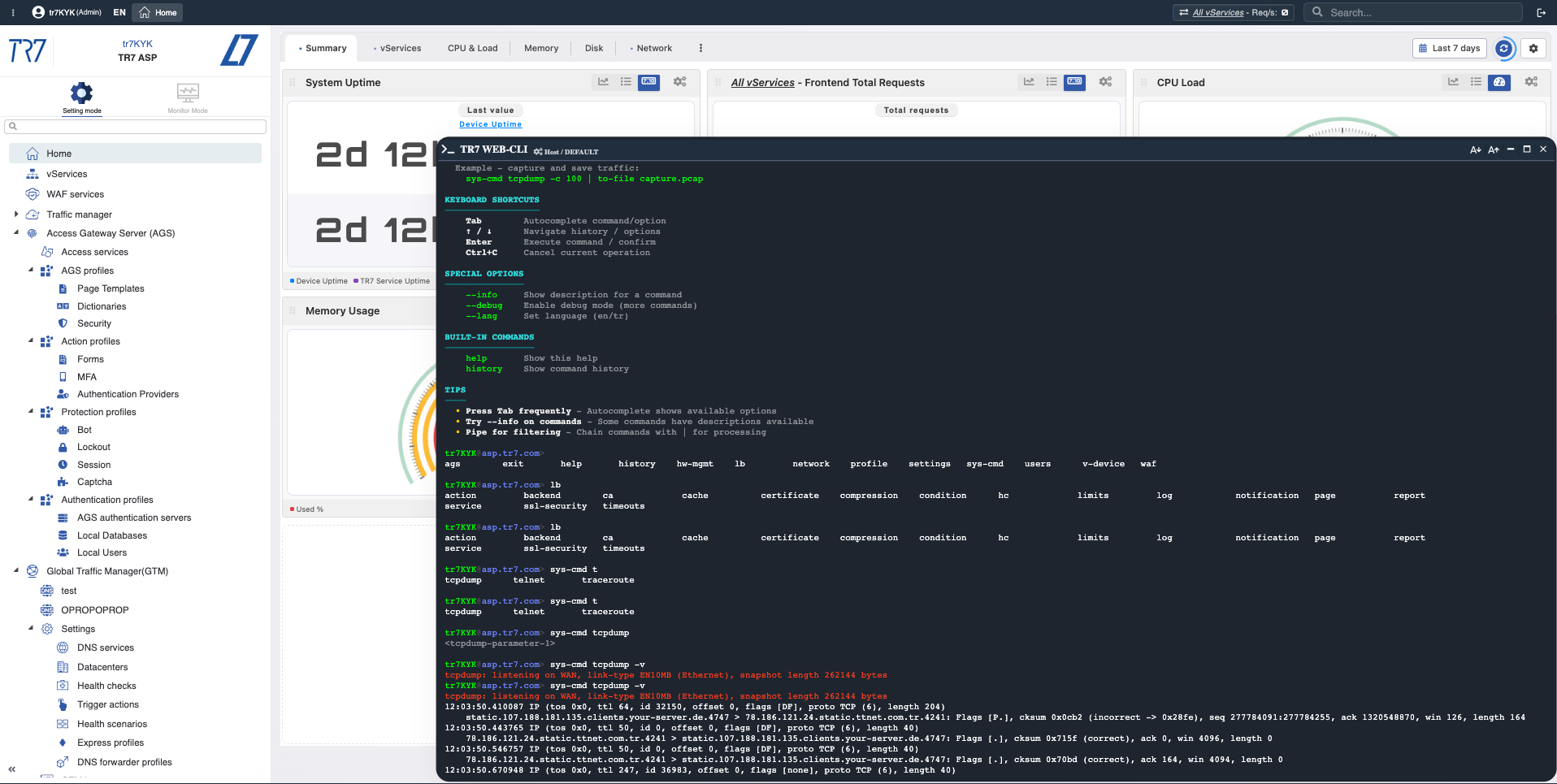
Die Untersuchung auf TR7 endet nicht bei Diagrammen. Die Web-Konsole ermöglicht das Ausführen der am meisten benötigten System- und Netzwerkbefehle von der Web-Oberfläche in der Produktion. Kein SSH erforderlich. TR7 CLI bringt die gleiche Fähigkeit zur Kommandozeile; Ausgabeformate (JSON/CSV/tab) und Pipe-Befehle machen Untersuchungsschritte wiederholbar.
Netzwerkprüfung: ping, traceroute, dig, iftop
Backend-Konnektivität, DNS-Auflösung, Pfadanalyse und Echtzeit-Bandbreitenverteilung vom Appliance aus verifizieren.
Gezieltes Traffic-Capture: tcpdump, ssldump
Pakete für spezifischen Host/Port erfassen. TLS-Handshakes untersuchen. Nur relevanten Traffic in Datei speichern.
Backend-Tests: curl, wrk
Backend-Response-Code und -Zeit aus ADC-Perspektive messen. Bei Bedarf kontrollierte Lasttests durchführen.
Systemstatus: netstat, ps, df, journalctl
TCP-Zustände, Prozesse, Festplattennutzung und Systemlogs von einem einzigen Bildschirm aus anzeigen.
Web-Konsole: Beispiel-Untersuchungsabläufe
Sie haben eine Warnung im Flow Panel entdeckt. Die folgenden Abläufe sind praktische Beispiele für schnelle Triage.
Backend-Timeout oder Netzwerkproblem?
Metriken zeigen Timeout
ping backend-ip → ist es erreichbar?
curl -I http://backend:8080/health → was ist der Response-Code?
traceroute backend-ip → irgendwelche Unterbrechungen auf dem Pfad?
Ergebnis: Netzwerk oder Anwendung — schnell getrennt
Zertifikat-, Protokoll- oder Cipher-Mismatch identifizieren
Ergebnis: Client- oder Server-Konfiguration — mit Paketen bewiesen
Plötzliche Traffic-Spitze: Angriff oder echte Last?
Request-Anzahl plötzlich gestiegen
iftop -i wan0 → Echtzeit-Top-Talker sehen
netstat -an | grep ESTABLISHED | wc → Verbindungsanzahl
tcpdump -c 1000 port 443 | to-file spike.pcap → Probe-Capture
Ergebnis: DDoS, Bot oder legitimer Traffic — mit Daten entscheiden
Backend 'schnell' aber Benutzer sagt 'langsam'
App-Team sieht kein Problem
curl -w '%{time_total}' http://backend/api → Zeit aus ADC-Sicht
wrk -t2 -c10 -d10s http://backend/api → Test unter Last
Ergebnis: Client–ADC–Backend-Kette — Unterschied wird klar
Aktivieren Sie nicht Debug — zielen Sie es.
Metrik-Bibliothek: Retrospektive Überwachung und Analyse-Charts
Die folgenden Überschriften sind Metrik-Chart-Gruppentitel in der TR7-Oberfläche. Jede Gruppe enthält Charts, in denen verwandte Metriken retrospektiv überwacht und analysiert werden können. Diese Charts ermöglichen es Ihnen, bestimmte Zeitbereiche während oder nach einem Vorfall zu untersuchen, Trends zu erkennen und Anomalien zu entdecken.
Frontend Gesamtanfragen
Total Requests
What?Zeigt die Gesamtzahl der HTTP/HTTPS-Anfragen an den Service im Zeitverlauf.
Why important?Grundlegende Referenz zum Verständnis von Traffic-Spitzen, plötzlichen Rückgängen und Kapazitätsauswirkungen. Ermöglicht Vorher/Nachher-Vergleich bei Vorfällen.
Frontend Statuscode-Verteilung
Status Code Distribution
What?Zeigt die Verteilung von HTTP-Response-Codes (2xx Erfolg, 3xx Weiterleitung, 4xx Client-Fehler, 5xx Server-Fehler) im Zeitverlauf.
Why important?Schnelle Erkennung von Fehlerraten-Anstiegen. 5xx-Spitze kann auf Backend-Probleme hinweisen; 4xx-Spitze kann auf Client-seitige oder Konfigurationsprobleme hinweisen.
Frontend Neue Verbindungen
New Connections
What?Zeigt neue TCP-Verbindungen, die pro Sekunde geöffnet werden.
Why important?Plötzliche Verbindungsanstiege können auf DDoS-Angriffe, Bot-Aktivität oder Client-seitige Wiederverbindungsprobleme hinweisen.
Frontend Gleichzeitige Sessions
Concurrent Sessions
What?Zeigt die gleichzeitig aktive Session-Anzahl.
Why important?Hilft zu verstehen, wie nah Sie an Kapazitätsgrenzen sind. Annäherung an Session-Limits kann Performance-Degradation verursachen.
Frontend Durchsatz
Throughput
What?Zeigt das gesamte Datenvolumen, das durch den Service fließt (bits/sec oder bytes/sec).
Why important?Wird verwendet, um Bandbreitennutzung und Traffic-Trends zu verstehen. Durchsatzrückgang kann auf Netzwerk- oder Backend-Probleme hinweisen.
SSL Gleichzeitige Verbindungen
SSL Concurrency
What?Zeigt die gleichzeitig aktive verschlüsselte TLS-Verbindungsanzahl.
Why important?SSL/TLS-Operationen sind CPU-intensiv; diese Metrik ist kritisch für Kapazitätsplanung und Performance-Analyse.
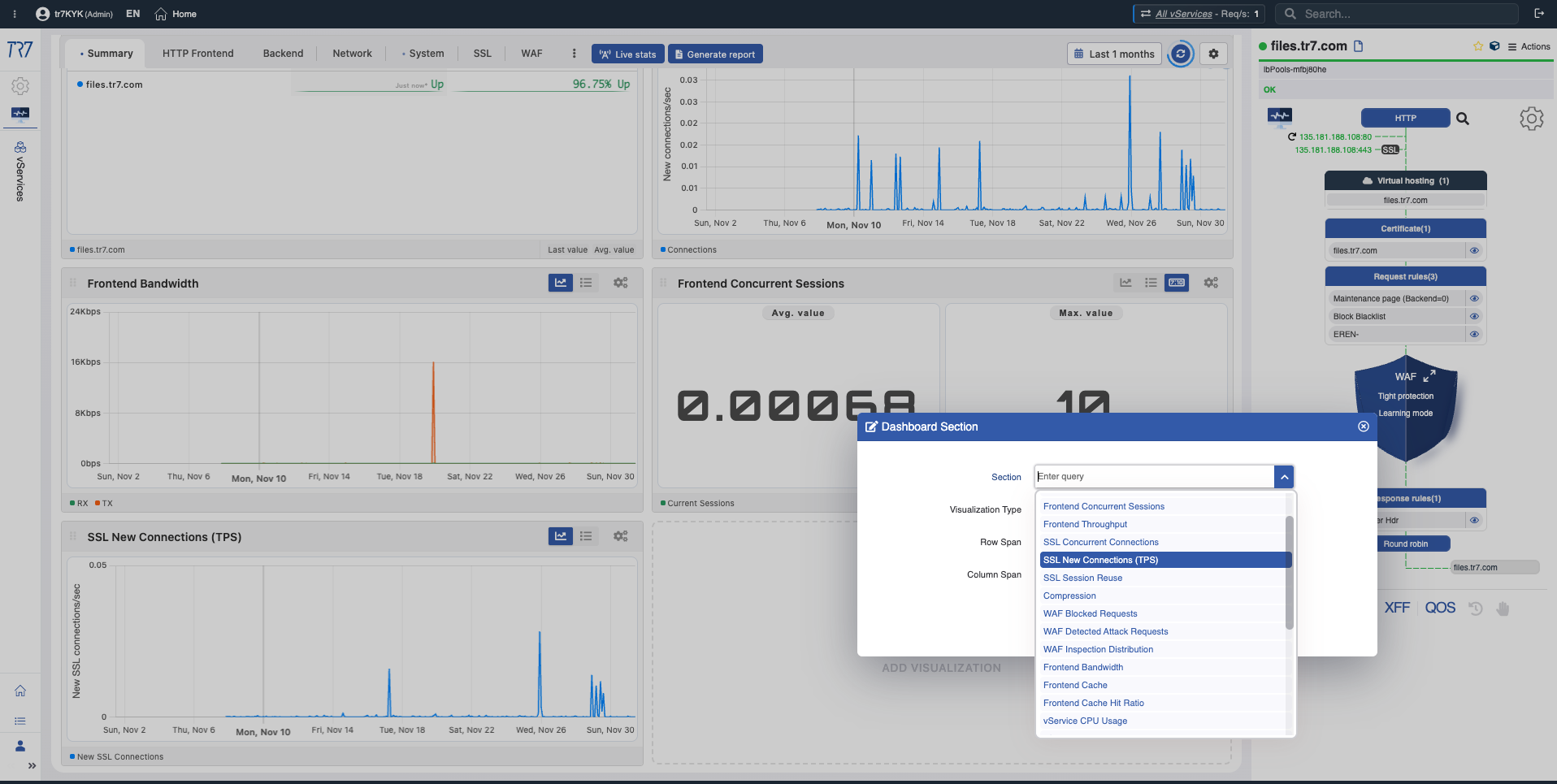
SSL Neue Verbindungen (TPS)
TLS Handshake TPS
What?Zeigt durchgeführte TLS-Handshakes pro Sekunde.
Why important?Plötzliche Handshake-Raten-Anstiege können darauf hinweisen, dass Session-Wiederverwendung nicht funktioniert oder Client-seitige Probleme vorliegen. Hohe Handshake-Raten erhöhen die CPU-Last.
SSL Session-Wiederverwendung
SSL Session Reuse
What?Zeigt TLS-Session-Wiederverwendungsrate und Statistiken.
Why important?Niedrige Session-Wiederverwendung verursacht unnötige CPU-Nutzung und höhere Latenz. Diese Metrik leitet die TLS-Performance-Optimierung.
Kompression
Compression
What?Zeigt HTTP-Response-Kompressionsrate und komprimiertes Datenvolumen.
Why important?Kompression spart Bandbreite, aber verbraucht CPU. Das Verständnis dieser Balance ist wichtig für Performance-Optimierung.
WAF Blockierte Anfragen
WAF Blocked Requests
What?Zeigt die Anzahl der von der Web Application Firewall blockierten Anfragen im Zeitverlauf.
Why important?Plötzlicher Anstieg der Blockierungen kann auf eine Angriffswelle oder eine neue Regel mit False Positives hinweisen. Beide Fälle erfordern Untersuchung.
WAF Erkannte Angriffsanfragen
WAF Detected Attacks
What?Zeigt Anzahl und Typen der von WAF erkannten Angriffsversuche.
Why important?Ermöglicht die Verfolgung von Bedrohungsstufe und Angriffstrends. Das Verständnis, welche Angriffstypen versucht werden und wie oft, ist wertvoll für die Sicherheitsstrategie.
WAF Inspektionsverteilung
WAF Inspection Distribution
What?Zeigt, welcher Anteil der WAF-Regeln und -Kategorien ausgelöst wird.
Why important?Zeigt, welche Regelsätze aktiv sind und welche am häufigsten auslösen. Grundlegende Daten für Regel-Tuning und Optimierungsentscheidungen.
Frontend Bandbreite
Bandwidth
What?Zeigt eingehende und ausgehende Bandbreite, die vom Service verwendet wird.
Why important?Wird verwendet, um Link-Sättigung und Durchsatzänderungen zu überwachen. Annäherung an Bandbreitengrenzen kann Performance-Probleme verursachen.
Frontend Cache
Cache
What?Zeigt das Cache-Verhalten des Service, Daten, die in den Cache geschrieben und daraus gelesen werden.
Why important?Caching reduziert die Backend-Last und verbessert die Antwortzeiten. Cache-Verhaltensänderungen beeinflussen direkt die Performance.
Frontend Cache-Hit-Ratio
Cache Hit Ratio
What?Zeigt, welcher Prozentsatz der Anfragen aus dem Cache bedient wird.
Why important?Hohe Hit-Ratio reduziert die Backend-Last und verkürzt die Antwortzeiten. Hit-Ratio-Rückgang erfordert die Untersuchung von Cache-Konfiguration oder Inhaltsänderungen.
vService CPU-Nutzung
vService CPU Usage
What?Zeigt den diesem Service zugeschriebenen CPU-Nutzungsprozentsatz.
Why important?Ermöglicht zu sehen, wie viel CPU ein einzelner Service verbraucht. Ein Service, der übermäßig CPU verbraucht, kann andere beeinflussen.
vService Speichernutzung
vService Memory Usage
What?Zeigt die diesem Service zugeschriebene Speichernutzung.
Why important?Die Überwachung des pro-Service-Speicherverbrauchs hilft bei der Erkennung von Speicherlecks oder übermäßigen Ressourcennutzungsproblemen.
vService Speichernutzung %
vService Memory %
What?Zeigt die Service-Speichernutzung als Prozentsatz.
Why important?Wird für Trendanalyse und Kapazitätsplanung verwendet. Kontinuierlich steigende Speichernutzung kann auf ein Problem hinweisen.
vService Uptime
vService Uptime
What?Zeigt die seit dem letzten Neustart des Service vergangene Zeit.
Why important?Ermöglicht die Korrelation von Service-Neustarts mit Vorfall-Zeitachsen. Unerwartete Neustarts erfordern Untersuchung.
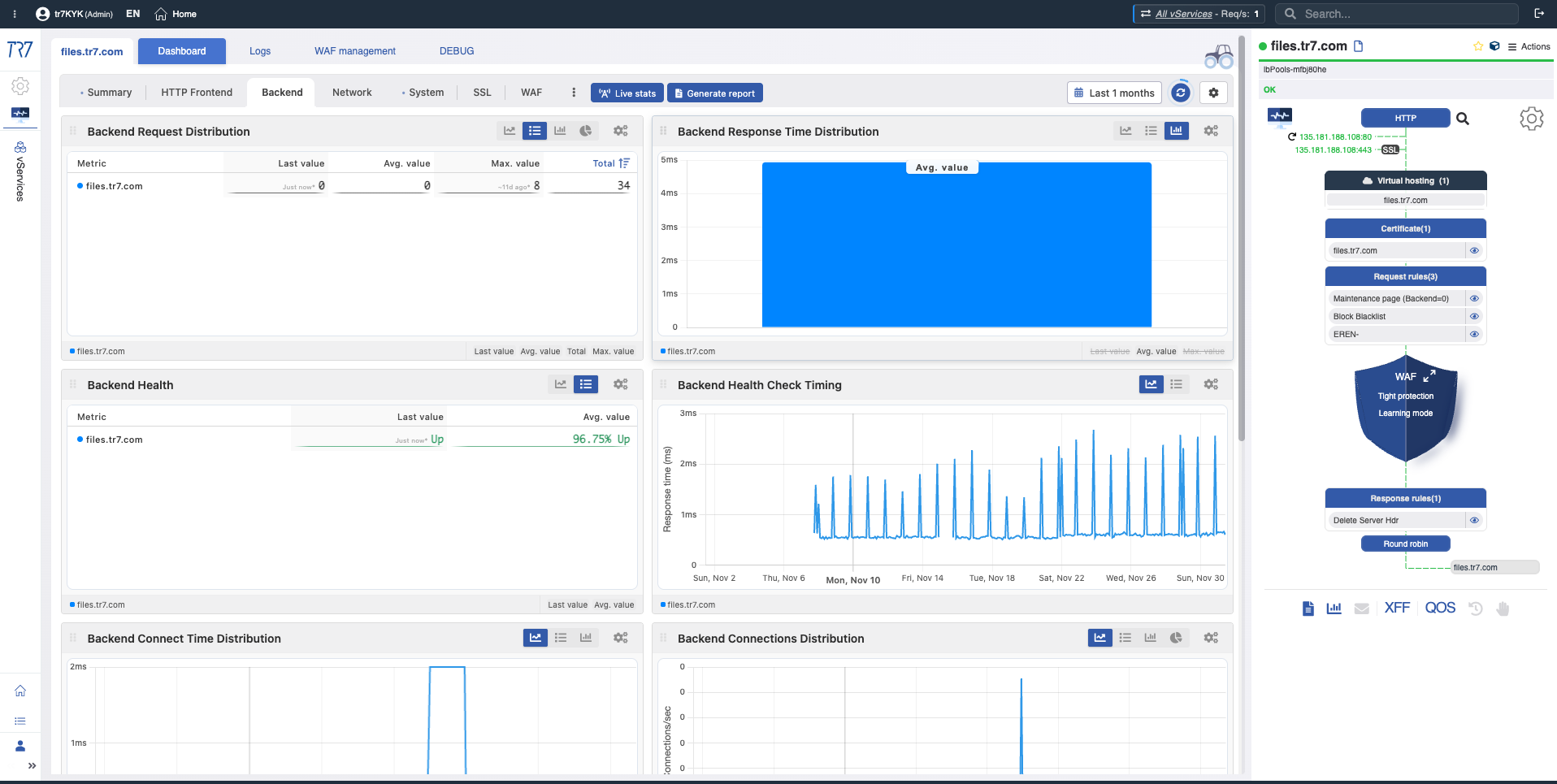
Backend Request-Verteilung
Backend Request Distribution
What?Zeigt, wie eingehende Anfragen unter Backend-Servern verteilt werden.
Why important?Ermöglicht die Erkennung ungleichmäßiger Lastverteilung. Ein Backend, das unverhältnismäßig mehr oder weniger Anfragen erhält, kann auf Konfigurations- oder Health-Probleme hinweisen.
Backend Antwortzeit-Verteilung
Backend Response Time Distribution
What?Zeigt die durchschnittliche Antwortzeit jedes Backend-Servers im Vergleich.
Why important?Ermöglicht die schnelle Identifizierung langsamer Backends. Wenn die Antwortzeit eines Backends deutlich höher ist als bei anderen, kann es ein Problem mit diesem Server geben.
Backend Health
Backend Health
What?Zeigt Health-Check-Ergebnisse und Health-Status für jeden Backend-Server.
Why important?Ermöglicht sofort zu sehen, welche Backends gesund, ausgefallen oder beeinträchtigt sind.
Backend Health-Check-Timing
Health Check Timing
What?Zeigt, wie oft Health-Checks ausgeführt werden und ihre Antwortzeiten.
Why important?Ermöglicht die Erkennung von Health-Check-Timing-Problemen. Langsame Health-Check-Antworten können die Erkennung eines problematischen Backends verzögern.
Backend Verbindungszeit-Verteilung
Connection Time Distribution
What?Zeigt die Verteilung der Verbindungsaufbauzeit zu Backends.
Why important?Hilft bei der Erkennung von Netzwerkverzögerungen und TCP-Verbindungsproblemen. Hohe Verbindungszeit weist auf Netzwerk- oder Backend-seitige Probleme hin.
Backend Verbindungsverteilung
Connection Distribution
What?Zeigt die Verteilung aktiver Verbindungen unter Backends.
Why important?Ermöglicht die Überwachung von Sticky-Session-Verhalten und Lastausgleich. Unverhältnismäßige Verbindungsansammlung auf einem Backend kann Performance-Probleme verursachen.
Backend Bandbreite IN-Verteilung
Bandwidth IN Distribution
What?Zeigt die Bandbreitenverteilung des Traffics, der zu Backends geht.
Why important?Ermöglicht zu sehen, welche Backends wie viel Traffic erhalten. Ein Backend, das übermäßig Traffic erhält, kann zum Engpass werden.
Backend Bandbreite OUT-Verteilung
Bandwidth OUT Distribution
What?Zeigt die Bandbreitenverteilung des Antwort-Traffics von Backends.
Why important?Hilft beim Verständnis der Backend-Antwortgrößen und Traffic-Muster. Backends, die große Antworten produzieren, beeinflussen die Bandbreitenplanung.
Backend Session-Verteilung
Session Distribution
What?Zeigt die Verteilung aktiver Sessions unter Backends.
Why important?Ermöglicht die Überwachung von Session-Persistenz-Verhalten und pro-Backend-Session-Dichte.
Backend Queue-Verteilung
Queue Distribution
What?Zeigt den Queue-Status von Anfragen, die auf Routing zu Backends warten.
Why important?Queue-Aufbau ist ein frühes Signal für unzureichende Backend-Kapazität. Wenn sich Queues füllen, steigen die Antwortzeiten.
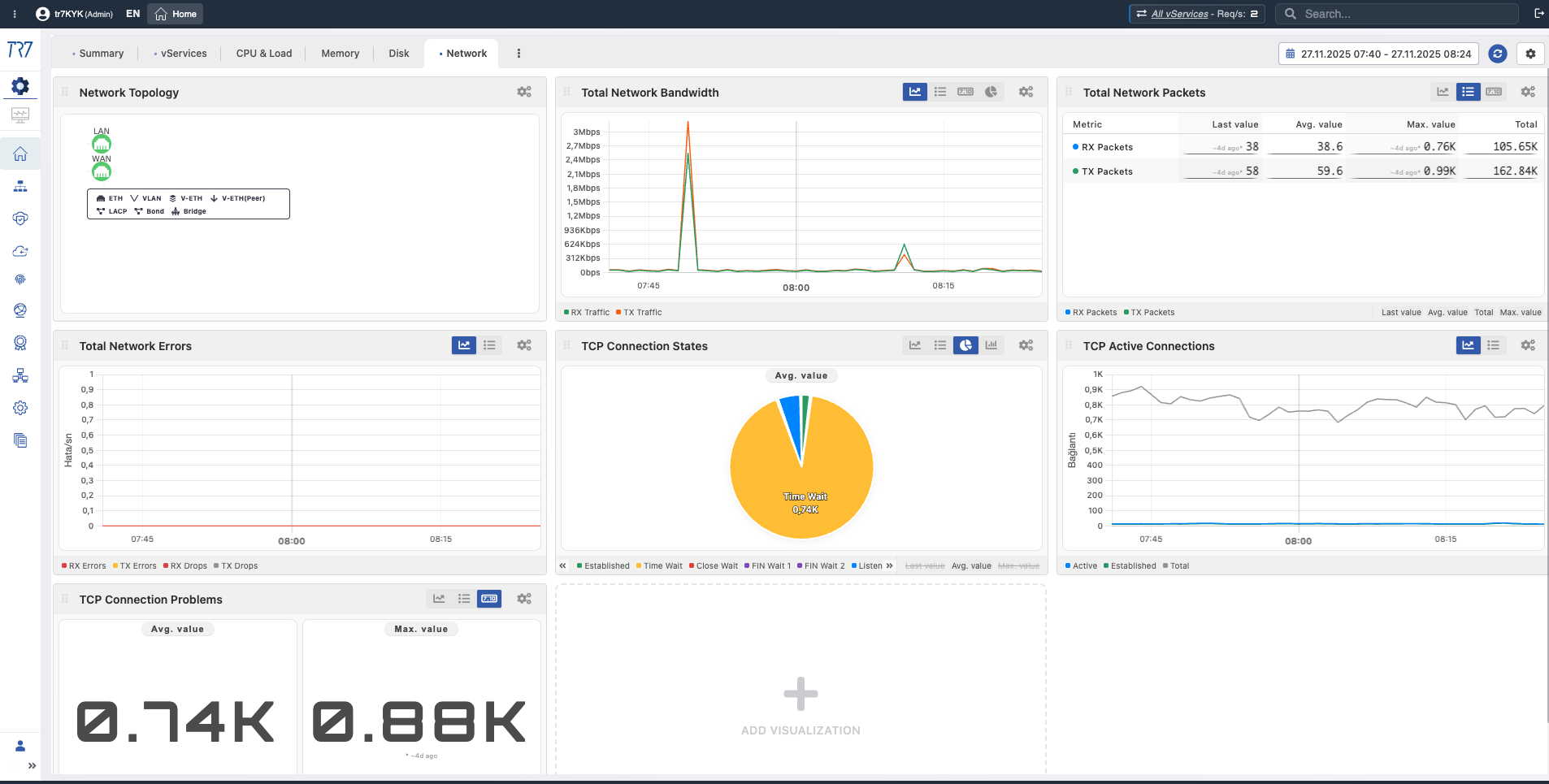
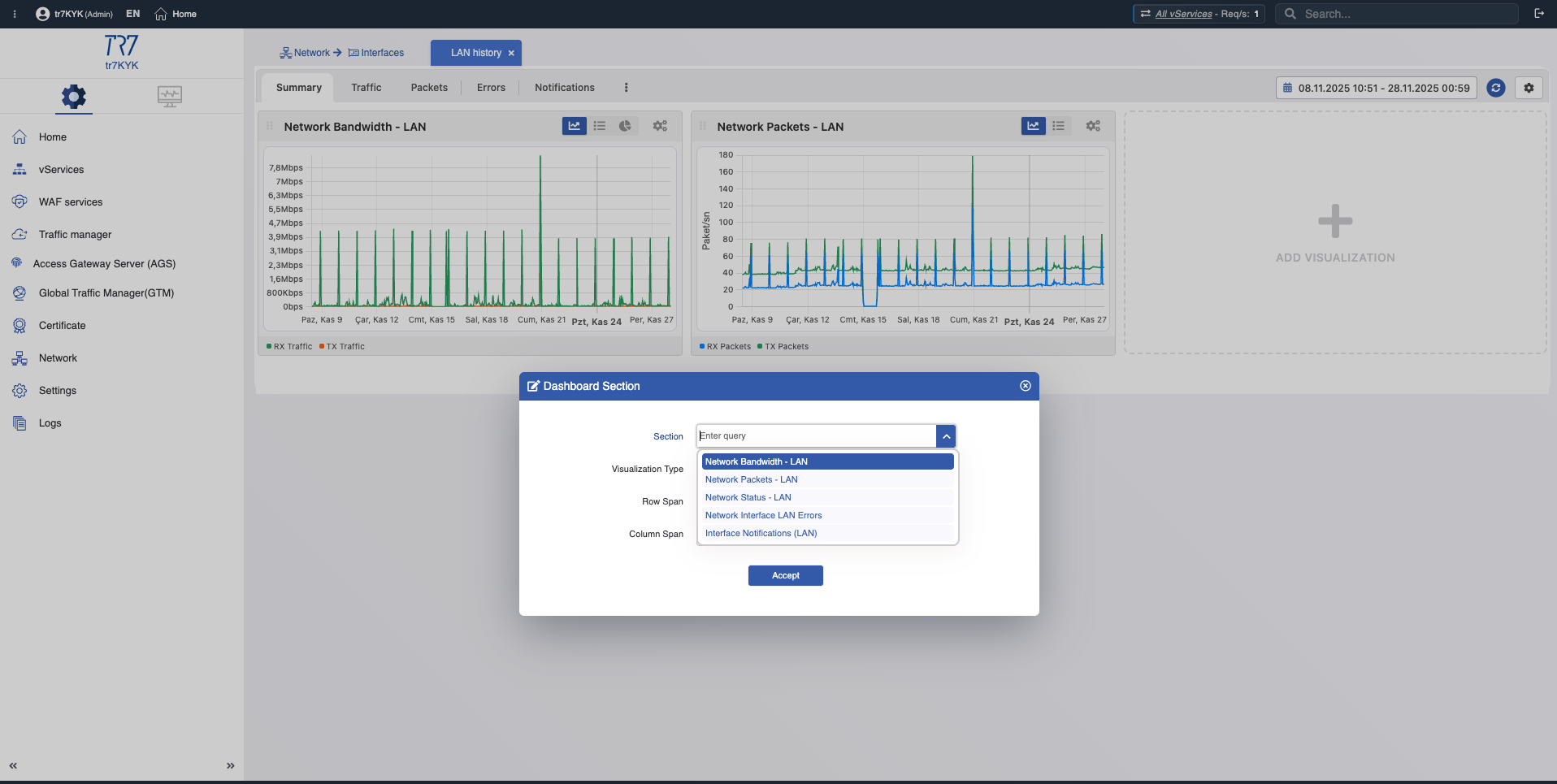
Netzwerk-Bandbreite - WAN
WAN Bandwidth
What?Zeigt das gesamte Traffic-Volumen, das durch das WAN-Interface fließt.
Why important?Ermöglicht zu sehen, wie nah Sie an der Link-Kapazität sind. Link-Sättigung verursacht Paketverlust und Latenzanstieg.
Netzwerk-Pakete - WAN
WAN Packets
What?Zeigt verarbeitete Pakete pro Sekunde (PPS).
Why important?PPS-Anomalien können auf DDoS-Angriffe oder Netzwerkprobleme hinweisen. Hohe PPS bei niedriger Bandbreite weist auf Small-Packet-Flood hin.
Netzwerk-Status - WAN
WAN Status
What?Zeigt den Betriebsstatus (up/down) und die Link-Qualität des Netzwerk-Interfaces.
Why important?Ermöglicht sofortige Erkennung von Link-Statusänderungen. Intermittierende Link-Downs verursachen Konnektivitätsprobleme.
Netzwerk-Interface-Fehler
Interface Errors
What?Zeigt Fehler, die auf dem Interface auftreten (CRC, Kollision, Drop, etc.).
Why important?Interface-Fehler können auf physische Kabelprobleme, MTU-Mismatches oder Hardware-Ausfälle hinweisen.
Interface-Einheiten (WAN)
Interface Units
What?Zeigt Status von Sub-Interfaces und VLANs.
Why important?Ermöglicht die separate Überwachung des Status jeder Sub-Einheit in komplexen Netzwerktopologien.
Gerät CPU-Nutzung
Device CPUSystem CPU
What?Zeigt die gesamte CPU-Nutzung des Geräts in Prozent.
Why important?Hohe CPU-Nutzung beeinträchtigt die Performance aller Services. Dauerhaft hohe CPU erfordert Kapazitätserhöhung oder Optimierung.
Gerät CPU-Temperatur
CPU Temperature
What?Zeigt die CPU-Betriebstemperatur.
Why important?Hohe Temperatur kann Thermal Throttling und Performance-Degradation verursachen. Übermäßige Temperaturanstiege erhöhen das Hardware-Ausfallrisiko.
System-Uptime
System Uptime
What?Zeigt die seit dem letzten Start des Geräts vergangene Zeit.
Why important?Ermöglicht die Erkennung unerwarteter Neustarts. Wenn Uptime zurückgesetzt wurde, untersuchen Sie, warum das Gerät neu gestartet wurde.
Systemlast
System LoadLoad Average
What?Zeigt 1-, 5- und 15-Minuten-Systemlast-Durchschnitte.
Why important?Hilft zu verstehen, wie beschäftigt das System ist. Wenn der Last-Durchschnitt dauerhaft die CPU-Anzahl übersteigt, ist das System überlastet.
Gesamte Speichernutzung
Total Memory Usage
What?Zeigt die vom System genutzte Gesamtspeichermenge.
Why important?Ermöglicht die Verfolgung des Speicherverbrauchs im Zeitverlauf. Kontinuierlich steigende Speichernutzung kann auf ein Speicherleck hinweisen.
Verfügbarer Speicher
Available Memory
What?Zeigt die für neue Prozesse verfügbare Speichermenge.
Why important?Niedriger verfügbarer Speicher kann verhindern, dass neue Verbindungen und Prozesse gestartet werden.
Speichernutzungsverhältnis
Memory Usage %
What?Zeigt, welcher Prozentsatz des Gesamtspeichers genutzt wird.
Why important?Wird für Kapazitätsplanung und schwellenwertbasierte Warnungen verwendet. Nutzung über 90% ist kritisches Niveau.
Swap-Nutzung
Swap Usage
What?Zeigt die Nutzung des Swap-Bereichs auf der Festplatte.
Why important?Swap-Nutzung zeigt an, dass physischer Speicher unzureichend ist. Aktive Swap-Nutzung verursacht erhebliche Performance-Degradation.
Festplattennutzung
Disk Usage
What?Zeigt die genutzte Festplattenspeichermenge.
Why important?Ermöglicht die Überwachung der Festplattenfüllrate. Wenn die Festplatte voll wird, kann das Log-Schreiben stoppen und das System instabil werden.
Festplattenkapazität
Disk Capacity
What?Zeigt die Gesamtfestplattenkapazität.
Why important?Referenzpunkt für Kapazitätsplanung und Wachstumstrendanalyse.
Festplattennutzungsverhältnis
Disk Usage %
What?Zeigt, welcher Prozentsatz der Festplattenkapazität genutzt wird.
Why important?Über 90% ist Warnung, über 95% ist kritisches Niveau. Festplatten-Vollheit erfordert Log-Rotation und Archivierungsplanung.
Festplatten-Inode-Nutzung
Inode Usage
What?Zeigt die Dateisystem-Inode-Nutzung.
Why important?Selbst bei freiem Festplattenplatz können, wenn Inodes erschöpft sind, keine neuen Dateien erstellt werden. Kritisch für Systeme mit vielen kleinen Dateien.
Festplatten-I/O Lesen
Disk Read I/O
What?Zeigt Festplatten-Leseoperationen pro Sekunde und Geschwindigkeit.
Why important?Hohe Lese-I/O kann auf Festplatten-Engpass hinweisen. Besonders wichtig für Nicht-SSD-Systeme.
Festplatten-I/O Schreiben
Disk Write I/O
What?Zeigt Festplatten-Schreiboperationen pro Sekunde und Geschwindigkeit.
Why important?Log- und Audit-Schreiben erzeugt konstant Festplatten-I/O. Wenn die Schreibgeschwindigkeit sinkt, besteht Log-Verlust-Risiko.
Festplatten-I/O-Latenz
I/O Latency
What?Zeigt die durchschnittliche Abschlusszeit für Festplattenoperationen.
Why important?Hohe I/O-Latenz ist ein frühes Signal für Festplatten-Performance-Degradation. Latenzanstieg beeinflusst die Gesamtsystem-Performance.
TCP-Verbindungsanzahl
TCP Connections
What?Zeigt die Gesamt-TCP-Verbindungsanzahl auf dem System.
Why important?Ermöglicht zu sehen, ob Sie sich Verbindungslimits nähern. Wenn das Verbindungslimit überschritten wird, werden neue Verbindungen abgelehnt.
TCP Established
Established Connections
What?Zeigt die Verbindungsanzahl, die aktiv Daten überträgt.
Why important?Indikator für die tatsächliche Arbeitslast. Established-Verbindungsanzahl steht in direktem Zusammenhang mit Kapazität.
TCP TIME_WAIT
TIME_WAIT
What?Zeigt die Verbindungsanzahl im TIME_WAIT-Zustand.
Why important?Hohe TIME_WAIT-Anzahl weist auf Port-Erschöpfungsrisiko hin. Kurzlebige Verbindungen und hoher Traffic verursachen TIME_WAIT-Aufbau.
TCP CLOSE_WAIT
CLOSE_WAIT
What?Zeigt die Verbindungsanzahl im CLOSE_WAIT-Zustand.
Why important?Hohe CLOSE_WAIT-Anzahl zeigt an, dass die Anwendung Verbindungen nicht ordnungsgemäß schließt. Dies ist üblicherweise ein Anwendungs-seitiger Bug.
TCP Retransmit
Retransmissions
What?Zeigt die TCP-Paket-Neuübertragungsanzahl.
Why important?Neuübertragungsanstieg zeigt Netzwerkqualitätsprobleme, Paketverlust oder Stau an. Hohe Neuübertragungsrate verursacht Latenzanstieg und Durchsatzrückgang.
vService Gesamtanfragen
Total vService Requests
What?Zeigt die Gesamtanfrageanzahl für alle vServices in einem Chart.
Why important?Ermöglicht das Verständnis des Gesamttraffic-Volumens und der Trends über das Gerät. Grundlegende Referenz für Kapazitätsplanung und Gesamtlastbewertung.
vService Gesamtverbindungen
Total vService Connections
What?Zeigt die Gesamtzahl aktiver Verbindungen für alle vServices.
Why important?Ermöglicht die Überwachung von Verbindungsdruck und Verbindungstabellennutzung über das Gerät. Annäherung an Verbindungstabellenlimits kann zur Ablehnung neuer Verbindungen führen.
Integrationen: verfügbar, aber Untersuchung hängt nicht von ihnen ab
TR7 kann in das Monitoring- und Log-Management-Ökosystem Ihrer Organisation integriert werden. Der kritische Unterschied: Die Vorfalluntersuchung hängt nicht ausschließlich von externen Pipelines ab. Externe Systeme fügen Wert hinzu; On-Appliance-Aufzeichnungen dienen als grundlegende Referenz.
Häufig gestellte Fragen
Das Ziel ist, dass untersuchungserforderliche Daten immer auf dem Appliance bereit sind. Externer Export und zentralisierte Archivierung werden unterstützt. Der Untersuchungserfolg hängt jedoch nicht ausschließlich von der Export-Konfiguration ab.
Das Ziel ist nicht, ständig alles anzusehen. Kategorien, Suche und Filterung ermöglichen es Ihnen, bei Bedarf schnell das richtige Signal zu erreichen.
Das Ziel der Web-Konsole ist nicht uneingeschränkter Zugang, sondern kontrollierte Diagnose. Bei Verwendung mit ordnungsgemäßer Autorisierung und Runbooks verkürzt sie die Untersuchungszeit.
Es ist in Echtzeit. Servicezustände werden zur Runtime überwacht und Änderungen werden sofort als Farbänderungen reflektiert. Zusätzlich werden retrospektive Metrik- und Eventaufzeichnungen beibehalten.
Normales Debug erfasst typischerweise allen Traffic und erfordert späteres Filtern. Gezieltes Debug erfasst von Anfang an Aufzeichnungen nur für spezifischen Host, Port, Pfad oder Header. Dies reduziert Rauschen, beschleunigt die Untersuchung und minimiert die Produktionsauswirkung.
TR7 unterstützt Prometheus-Export und SIEM-Log-Weiterleitung. Integrationen behalten ihren Wert. Der Unterschied: Untersuchungserforderliche Daten hängen nicht ausschließlich von externen Systemen ab—sie sind auch auf dem Appliance bereit.
Die Aufbewahrungsdauer ist konfigurierbar. Wichtig ist, dass Benutzeraktionen und Config-Änderungen auf der gleichen Zeitachse wie Metriken und Eventaufzeichnungen gehalten werden.
Detail ist Vorbereitung, nicht Komplexität. Selbst in kleinen Teams spart schnelles Erreichen der richtigen Daten während eines Vorfalls Zeit. Kategorisierte Struktur und Suchfunktionen erleichtern es, sich nur auf benötigte Daten zu konzentrieren.
Fazit
Der Anspruch von TR7 ist nicht 'mehr Charts'—es geht darum, die ADC/WAF-Schicht investigation-ready zu machen. vService/Backend/Interface-Metriken, Event/Benachrichtigungsaufzeichnungen, Audit-Trail und HTTP/WAF-Sichtbarkeit kombinieren sich auf einer einzigen Zeitachse; retroaktive Forensik und gezieltes Debug beschleunigen die Ursachenanalyse.
Export-Integrationen sind wertvoll; aber um das Risiko 'wurde nicht gesendet, existiert also nicht' in kritischen Momenten zu minimieren, muss die Beweiskette jederzeit innerhalb des Produkts zugänglich bleiben.
Diese und ähnliche Fähigkeiten—Details, die nicht auf Datenblättern erscheinen, in Demos schwer zu erfassen sind, aber die operative Qualität in der Praxis definieren—sind der Hauptgrund, warum fast alle Organisationen, die TR7 evaluieren, sich für den Wechsel entscheiden.